





为了解决计划或优化问题,一些求解器的扩展能力往往很差:由于问题具有更多的变量和更多的约束,因此他们使用大量的RAM内存和CPU功能。 它们可以达到数千个变量和几百万个约束匹配的硬件内存限制。 他们的用户通常在这种硬件限制下工作的一种方法是使用MapReduce 。 让我们看看如果我们MapReduce一个计划问题,例如Traveling Salesman Problem ,会发生什么。
关于MapReduce
MapReduce是一种编程模型,已被证明对大数据运行查询非常有效。 一般来说,它的工作方式如下:
- 数据跨多个计算机节点进行分区 。
- 映射函数在每个分区上运行并返回结果。
- 减少功能将2个结果减少为一个结果。 它持续运行直到只剩下一个结果。
例如,假设我们需要在数据集群中找到最昂贵的发票记录:
- 发票记录跨多个计算机节点进行分区。
- 对于每个节点, 地图功能都会提取该节点最昂贵的发票。
- 减少功能需要2张发票并退回最昂贵的发票。
关于旅行商问题
旅行商问题 (TSP)是一个非常基本的计划问题。 根据城市列表,找到访问所有城市的最短路径。
例如,这是一个包含68个城市的数据集,其最佳旅行距离为674 :
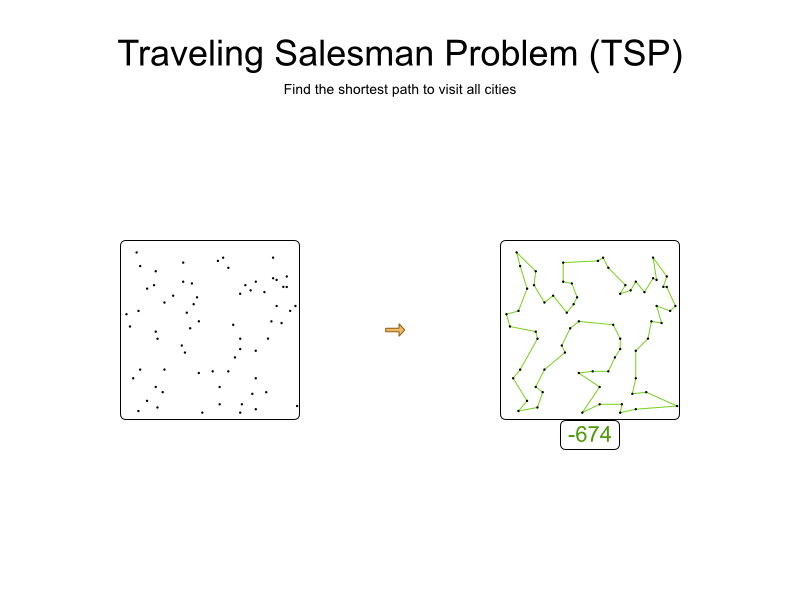
这个小型数据集的搜索空间具有68 (= 10 96 )个组合。 好多啊。
一个更现实的规划问题,例如车辆路线,具有更多的约束(无论在数量上还是在复杂性上),例如:车辆容量,车辆类型限制,时间窗,驾驶员限制等。
TSP上的MapReduce
即使大多数求解器可能不会仅对68变量耗尽内存,但此问题的小尺寸使我们可以清楚地看到它:

让我们对其应用MapReduce:
1)
首先,我们将问题分解为n部分。 通常, n是我们系统中计算机节点的数量。 出于视觉原因,我们仅将其分为4部分:
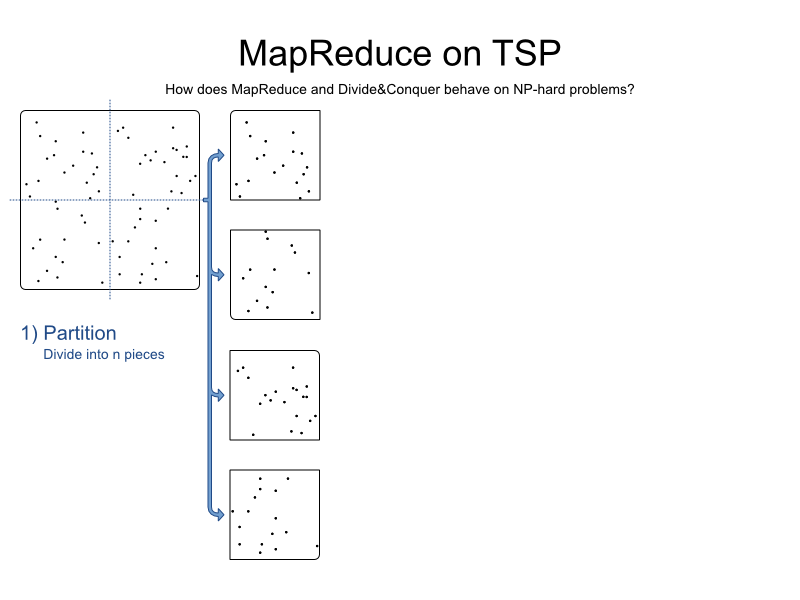
TSP易于分区,因为它只有1个相关约束:找到最短路径。
在更现实的计划问题中,合理的分区可能很难甚至不可能。 例如:
- 在容量较大的车辆路线中,任何2个分区都不应共享同一辆车辆。 如果我们的分区比车辆多怎么办?
- 在带有时间窗的车辆路线选择中,每个分区应该有足够的车辆时间来服务每个客户并开车到每个地点。 Catch 22:如果我们还不知道车辆路线,我们如何确定行驶时间?
做出错误的假设是很诱人的。
2)
使用规划求解来解决每个分区:
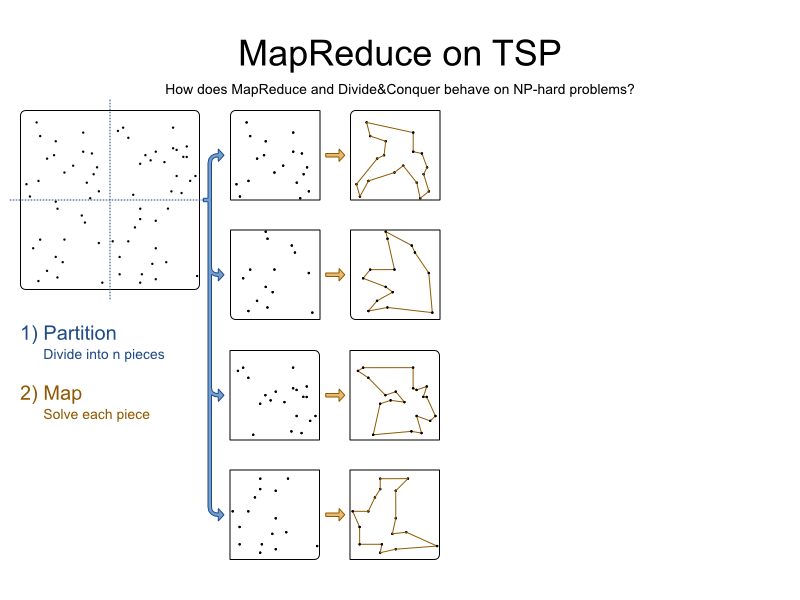
我们得到4件,每件都有部分解决方案。
3)
合并碎片。 要将2个片段合并在一起,我们从每个片段中删除一条弧,然后添加2条弧以连接不同片段的城市:
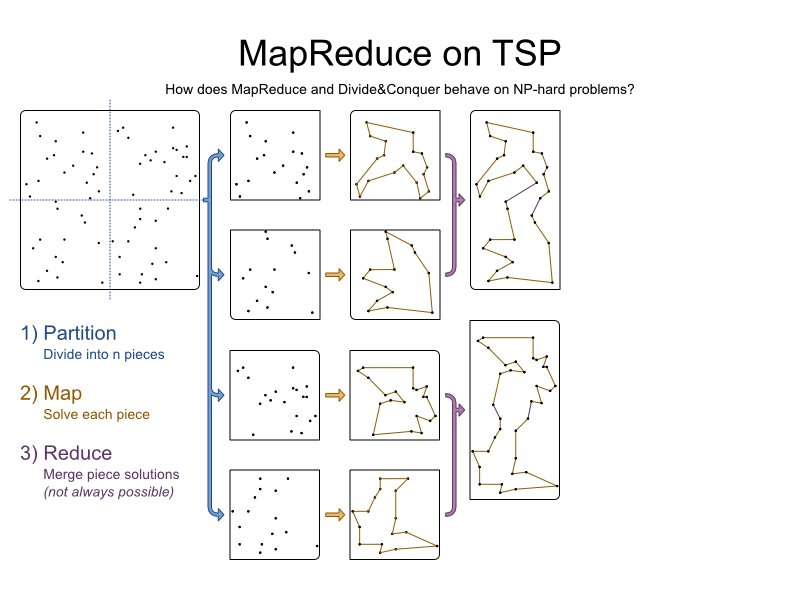
我们会合并几次,直到所有部分都合并:
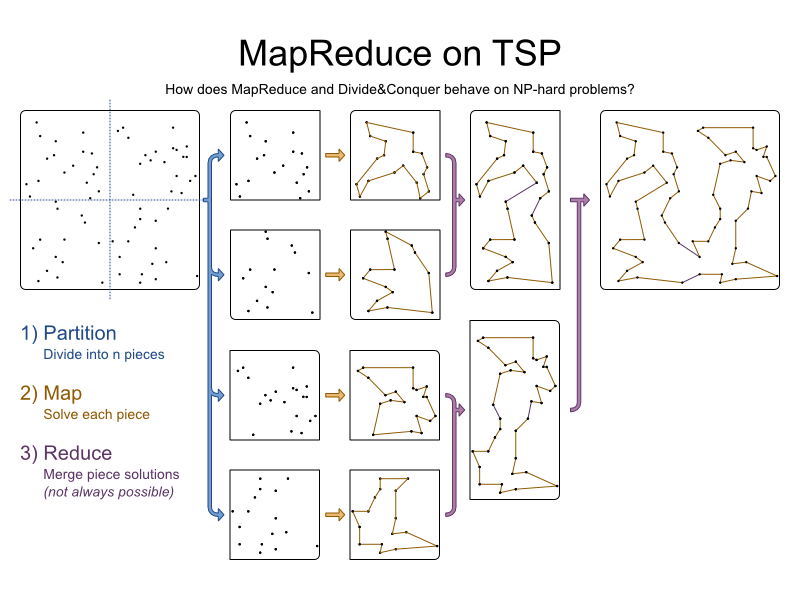
有两种方法可以将2个片段合并在一起。 在这里,我们尝试每种组合并选择最佳组合。 出于性能方面的考虑,我们可能会用一条弧线将两个不同零件的最近城市连接起来,然后在另一侧添加校正弧线(但可能要多久)。
在具有更复杂约束的更现实的计划问题中,合并可行的部分解决方案通常会导致不可行的解决方案(具有打破的硬约束)。 考虑到所有硬约束的更智能分区有时可以解决此问题……代价是要打破更多的软约束并增加维护成本。
4)
每件作品都得到了最佳解决。 件被最佳合并。 但是结果不是最佳的 :
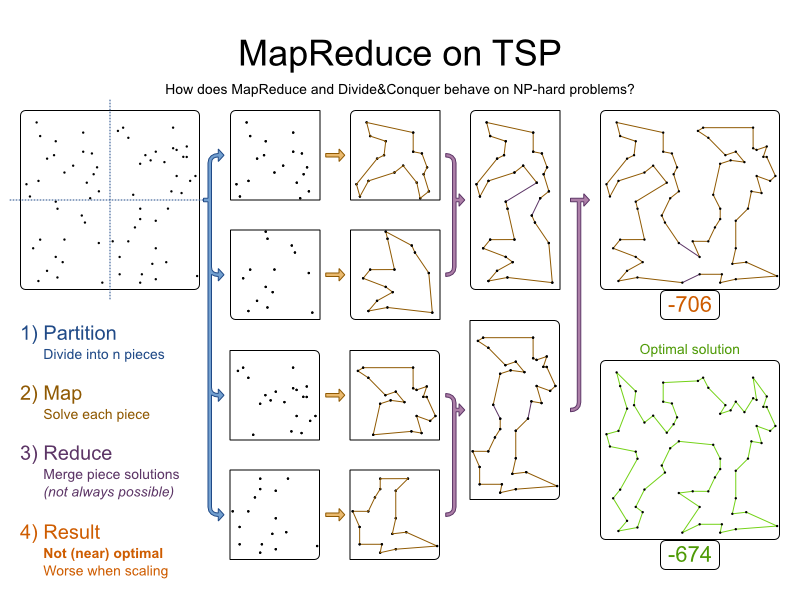
实际上,结果甚至还不是最佳的,尤其是当我们使用MapReduce方法进行横向扩展时:
- 更多变量会导致较低的结果质量。
- 更大的约束导致更低的结果质量,甚至可以合理地划分和减少。
- 分区越多,结果质量越低。
结论
MapReduce是处理查询问题(可能还有许多其他问题)的好方法。 但是MapReduce是解决计划或优化问题的可怕方法。 使用正确的工具完成工作。
注意:我们将MapReduce应用于规划问题,而不是针对规划求解中的优化算法实现,对此可以理解。 例如,在深度优先搜索算法中,MapReduce可以探索搜索树(尽管搜索树的缩放比例成指数倍,这使MapReduce的任何收益相形见))。
要解决较大的计划问题,请使用可在内存中很好地扩展的求解器(例如OptaPlanner ),因此您不必诉诸于分区而以解决方案质量为代价。
翻译自: https://www.javacodegeeks.com/2014/03/can-mapreduce-solve-planning-problems.html















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









