





在数据库环境中,“扩展”甚至意味着什么? 在谈论扩展时,人们已经跳到了供应商得出的结论:
- SQL无法扩展
- NoSQL扩展
很明显, NoSQL供应商做出了这样的声明 。 有趣的是,许多NoSQL使用者都提出了这样的主张,即使他们可能通常将SQL 特别是与MySQL混淆了。 然后,他们继续将MongoDB与MySQL可伸缩性进行比较 ,这完全有意义,因为MySQL对MySQL而言就像MySQL对NoSQL一样 。
让我们回到地面……
…因为在过去的几十年中,没有任何数据库可以在事务处理绩效委员会的基准上击败Oracle。 我们相信CERN的员工在选择Oracle Exadata和其他Oracle产品来管理其巨大的数据时已经做出了明智的决定,甚至在将大数据称为Big Data之前 。
因此,让我们进行快速比较。 最近,Vlad Mihalcea发表了有关“闪电速度聚合” (使用MongoDB)的博客。 他以以下形式收集了5000万条记录的数据集:
created_on | value
-------------------------------------------
2012-05-02T06:08:47Z | 0.9270193106494844
2012-09-06T22:40:25Z | 0.005334891844540834
2012-06-15T05:58:22Z | 0.05611344985663891
... | ...这些是随机时间戳和随机浮点数。 然后,他使用以下查询汇总了该数据:
var dataSet = db.randomData.aggregate([
{
$group: {
"_id": {
"year" : {
$year : "$created_on"
},
"dayOfYear" : {
$dayOfYear : "$created_on"
}
},
"count": {
$sum: 1
},
"avg": {
$avg: "$value"
},
"min": {
$min: "$value"
},
"max": {
$max: "$value"
}
}
},
{
$sort: {
"_id.year" : 1,
"_id.dayOfYear" : 1
}
}
]);并得到了“麻木”,闪电般的聚合结果:
聚集了:129.052s
对于具有50M条记录的中型表来说129秒对MongoDB来说是闪电般的速度? 好吧,我们想。 让我们在Oracle上尝试一下。 Vlad有礼貌地向我们提供了示例数据,我们将其导入到以下简单的Oracle表中:
CREATE TABLESPACE aggregation_test
DATAFILE 'aggregation_test.dbf'
SIZE 2000M ONLINE;
CREATE TABLE aggregation_test (
created_on TIMESTAMP NOT NULL,
value NUMBER(22, 20) NOT NULL
)
TABLESPACE aggregation_test;现在,让我们使用sqlldr将数据加载到我的单核许可的Oracle XE 11gR2实例中:
OPTIONS(skip=1)
LOAD DATA
INFILE randomData.csv
APPEND
INTO TABLE aggregation_test
FIELDS TERMINATED BY ','
(
created_on DATE
"YYYY-MM-DD\"T\"HH24:MI:SS\"Z\"",
value TERMINATED BY WHITESPACE
"to_number(ltrim(rtrim(replace(:value,'.',','))))"
)然后:
C:\oraclexe\app\oracle\product\11.2.0\server\bin\sqlldr.exe
userid=TEST/TEST
control=randomData.txt
log=randomData.log
parallel=true
silent=feedback
bindsize=512000
direct=true使用旧磁盘在计算机上加载记录花费了一段时间:
Elapsed time was: 00:03:07.70
CPU time was: 00:01:09.82我可能能够以一种或另一种方式进行调整,因为SQL * Loader并不是最快的工具 。 但是,让我们挑战129的汇总。 到目前为止,我们还没有指定任何索引,但这不是必需的,因为我们将整个表与所有5000万条记录汇总在一起。 让我们使用以下与Vlad的等效查询来执行此操作:
SELECT
EXTRACT(YEAR FROM created_on),
TO_CHAR(created_on, 'DDD'),
COUNT(*),
AVG(value),
MIN(value),
MAX(value)
FROM aggregation_test
GROUP BY
EXTRACT(YEAR FROM created_on),
TO_CHAR(created_on, 'DDD')
ORDER BY
EXTRACT(YEAR FROM created_on),
TO_CHAR(created_on, 'DDD')这在我的计算机上花费了32秒,并且进行了明显的全表扫描。 不令人印象深刻。 让我们尝试一下Vlad的其他查询,它按一个小时进行过滤,并在其基准测试中以209ms执行( 我们认为这根本不够快 ):
var dataSet = db.randomData.aggregate([
{
$match: {
"created_on" : {
$gte: fromDate,
$lt : toDate
}
}
},
{
$group: {
"_id": {
"year" : {
$year : "$created_on"
},
"dayOfYear" : {
$dayOfYear : "$created_on"
},
"hour" : {
$hour : "$created_on"
}
},
"count": {
$sum: 1
},
"avg": {
$avg: "$value"
},
"min": {
$min: "$value"
},
"max": {
$max: "$value"
}
}
},
{
$sort: {
"_id.year" : 1,
"_id.dayOfYear" : 1,
"_id.hour" : 1
}
}
]);弗拉德(Vlad)生成了一个随机日期,他记录为
Aggregating
from Mon Jul 16 2012 00:00:00 GMT+0300
to Mon Jul 16 2012 01:00:00 GMT+0300 因此,让我们使用完全相同的日期。 但是首先,我们应该在AGGREGATION_TEST(CREATED_ON)上创建一个索引:
CREATE TABLESPACE aggregation_test_index
DATAFILE 'aggregation_test_index1.dbf'
SIZE 2000M ONLINE;
CREATE INDEX idx_created_on
ON aggregation_test(created_on)
TABLESPACE aggregation_test_index; 好。 现在,让我们运行与Vlad的查询等效的Oracle(请注意, GROUP BY, SELECT, ORDER BY子句中有一个新列):
SELECT
EXTRACT(YEAR FROM created_on),
TO_CHAR(created_on, 'DDD'),
EXTRACT(HOUR FROM created_on),
COUNT(*),
AVG(value),
MIN(value),
MAX(value)
FROM aggregation_test
WHERE created_on
BETWEEN TIMESTAMP '2012-07-16 00:00:00.0'
AND TIMESTAMP '2012-07-16 01:00:00.0'
GROUP BY
EXTRACT(YEAR FROM created_on),
TO_CHAR(created_on, 'DDD'),
EXTRACT(HOUR FROM created_on)
ORDER BY
EXTRACT(YEAR FROM created_on),
TO_CHAR(created_on, 'DDD'),
EXTRACT(HOUR FROM created_on);第一次运行耗时20秒。 公平地说,在运行此语句之前,我清除了一些缓存。 我相信弗拉德的MongoDB已经为第二个查询“热身”了:
alter system flush shared_pool;
alter system flush buffer_cache;因为当我再次运行相同的查询时,Oracle的缓冲区高速缓存启动仅花费了0.02秒的时间,从而阻止了实际的磁盘访问。 我可能已经调整了我的Oracle实例,以使整个表都不会出现在第一个查询中,在这种情况下,Oracle将击败MongoDB一个数量级。
另一种选择是调整索引编制。 让我们删除现有索引,并用“覆盖”索引替换它:
DROP INDEX idx_created_on;
CREATE INDEX idx_created_on_value
ON aggregation_test(created_on, value)
TABLESPACE aggregation_test_index;让我们再次刷新缓存:
alter system flush shared_pool;
alter system flush buffer_cache;并运行查询...
- 第一次执行:0.5秒
- 第二次执行:0.005s
从执行计划中,我现在可以知道查询不再需要访问表。 所有相关数据都包含在索引中:
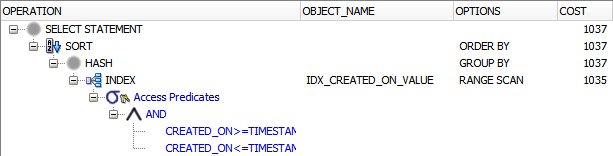
现在开始变得令人印象深刻,对吗?
那么,我们可以从中得出什么结论呢?
以下是一些发现:
不要下结论
首先,我们应该谨慎一点,以免得出任何结论。 我们正在将苹果与橙子进行比较。 在将Oracle与SQL Server进行比较时,我们甚至将苹果与橙子进行比较。 这两个基准都是快速编写的,这些基准不能代表任何有效的情况。 我们现在已经可以说的是,在50M记录表中聚合数据时,并没有一个明显的赢家,但是Oracle似乎在SSD(MongoDB)与HDD(Oracle)磁盘基准测试中表现得非常好!
公平地讲,我的计算机具有比Vlad更好的CPU:
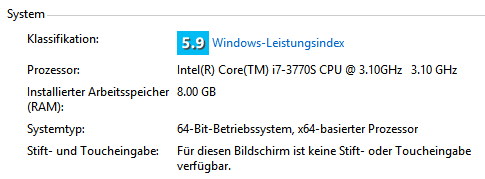
我的电脑
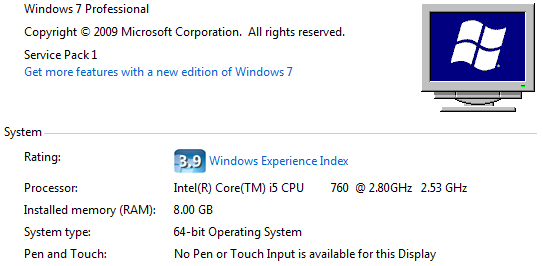
弗拉德的电脑
SQL和NoSQL均可扩展
NoSQL扩展的争论主要是FUD。 人们总是希望相信倾向于说“他们的产品不能做到这一点和那件事”的供应商。 不要立即购买。 像上面那样运行一个较小的基准并亲自查看,对于SQL和NoSQL数据库而言 ,扩大规模都不是问题。 不要被Oracle最初的“慢”查询执行所蒙蔽。 Oracle是一个非常复杂的数据库,这得益于其基于成本的优化器和统计信息,它可以根据实际需要进行自我调整。
而且,没有什么可以阻止您(和您的DBA)使用工具的所有功能。 在此示例中,我们仅刮擦了表面。 例如,如果您使用的是Oracle Enterprise Edition,我们可能会应用IOT(索引组织表)或表分区。
50M不是大数据
欧洲核子研究组织拥有大数据。 谷歌这样做。 Facebook的。 你不知道 50M不是“大数据”。 这只是您的平均数据库表。
200ms不快
显然,您可能不太在意在专用批处理报告服务器上准备脱机报告所花费的时间。 但是,如果您在真实的UI上有一个真实的用户在等待它……如果这样,200ms的速度并不快,因为它们可能正在运行20个查询。 这些用户可能有1万。 在真正的OLTP系统中,具有这样的报告查询甚至是偶数意味着Oracle 0.005并不快!
所以,换句话说...
翻译自: https://www.javacodegeeks.com/2013/12/mongodb-lightning-fast-aggregation-challenged-with-oracle.html















 834
834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









