





 本文介绍了数据仓库设计的两种主要方法:自上而下和自下而上。自上而下的方法由Bill Inmon提出,强调数据仓库在商业智能系统中的整体地位,数据经过验证和汇总后加载到数据集市。自下而上的方法由Ralph Kimball倡导,主张数据集市是数据仓库的基础,通过总线架构连接。两种方法在数据提取、处理和加载的步骤上有所不同。
本文介绍了数据仓库设计的两种主要方法:自上而下和自下而上。自上而下的方法由Bill Inmon提出,强调数据仓库在商业智能系统中的整体地位,数据经过验证和汇总后加载到数据集市。自下而上的方法由Ralph Kimball倡导,主张数据集市是数据仓库的基础,通过总线架构连接。两种方法在数据提取、处理和加载的步骤上有所不同。
在以前的文章中,我们必须学习数据仓库对象 , 各种数据仓库模式和数据仓库基础知识 。 现在,我们该了解如何构建或设计数据仓库。
可以按照以下任一方法完成数据仓库的设计或构建。 这些方法尤其被称为:
- 自上而下的方法
- 自下而上的方法
这些方法由数据仓库的两个承担者Ralph Kimball和Bill Inmon定义 。
自上而下的方法
Bill Inmon提出了这种方法,他说:“ 数据仓库是整个商业智能系统的一部分。 一个企业有一个数据仓库,而约会市场从数据仓库中获取其信息。 在数据仓库中,信息以“第三范式”存储。
简而言之,Bill Inmon提倡“依赖数据集市结构”。

上图显示了自顶向下模型的工作方式。
步骤如下:
- 数据是从不同/相同的数据源中提取的。 将此数据加载到暂存区中,并进行验证和合并以确保准确性,然后将其推送到企业数据仓库(EDW)。
- 定期从EDW中提取详细数据,并将其临时存储在暂存区域中以进行汇总,汇总,然后提取并加载到数据仓库中。
- 一旦完成数据的汇总和汇总,数据集市就会将数据提取到数据集市中,并对其进行新的转换。 这样做是为了使随附的数据与为数据集市定义的结构同步。
自下而上的方法
Ralp Kimball提出了这种方法,他说: “数据仓库是企业内所有数据集市的联合体。 信息总是存储在维度模型中。”
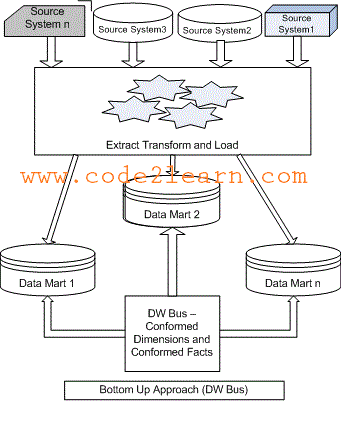
* Ralp kimball设计了数据仓库,其中数据集市通过总线结构连接到该数据仓库。
*如上所示,总线结构包含数据集市使用的所有常见元素,例如一致的尺寸,度量等。
基本上,Kimball模型逆转了Inmon模型,即直接从源系统中加载数据集市,然后使用ETL流程加载到数据仓库中。
步骤如下:
- 自下而上方法中的数据流始于从运营数据库中提取数据到暂存区域,在此将数据进行处理并加载到EDW中。
- EDW中的数据将刷新或替换为正在加载的新数据。 刷新EDW之后,将在暂存区域中再次提取当前数据,并进行转换以适合数据集市结构。 数据是从Data Mart提取到汇总,汇总等过渡区域的,然后加载到EDW中,然后可供最终用户进行分析。
参考:来自我们的JCG合作伙伴 Farhan Khwaja的Data Warehouse Design Approaches在Code 2学习博客上
翻译自: https://www.javacodegeeks.com/2013/01/data-warehouse-design-approaches.html















 8180
8180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









