





尾递归优化
如果您像我们的许多工匠一样对函数式编程感兴趣,那么您将听说过尾递归。 尾递归是指从尾部位置进行的递归函数调用。 当函数调用处于尾部位置时,这意味着从被调用函数返回控制和调用函数的返回语句之间不再有任何指令。 我们将通过一些代码示例来说明这一点,但首先,为什么这么重要?
1977年,盖伊·斯蒂尔(Guy L. Steele) 向ACM提交了一篇论文,总结了关于GOTO和结构化编程的争论,他观察到,将例程尾部位置的过程调用最好视为将控制权直接转移到被调用对象上。程序。 他认为,这将消除不必要的堆栈操纵操作,该操作导致人们人为地认为GOTO比过程调用更有效。
在最基本的级别上,函数或过程是子例程,由跳转指令调用该子例程入口点。 子例程与简单跳转的区别在于,调用代码必须先跳转到调用堆栈上的返回地址(子例程返回后要执行的下一条指令的地址),然后再跳转到子例程。 子例程参数和局部变量也存储在堆栈中,该堆栈可以是调用堆栈或单独的堆栈:
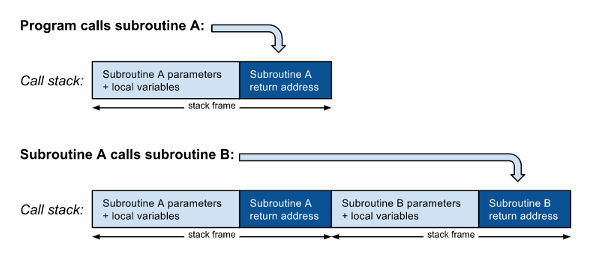
如图1所示,当子例程A调用另一个子例程B时 ,必须将包含返回地址的新堆栈帧压入调用堆栈中位于A的返回地址之上。 B完成后,它将读取返回地址,从调用堆栈中弹出其堆栈帧,然后返回其调用方A。 子例程A完成后,它会执行类似的操作:
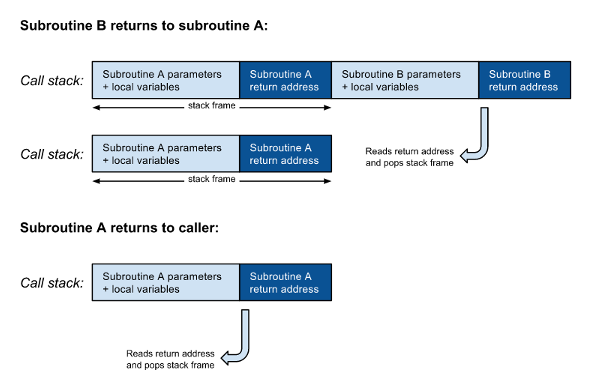
然而,当调用子程序B在尾部位置有控制的从B和回报A的return语句之间没有更多的指令。 换句话说,程序将从B返回,仅立即返回到A的调用者。 因此,无需将B的返回地址压入调用堆栈:程序可以简单地跳转到B,并且在完成后,它将从调用堆栈读取A的返回地址并直接返回给A的调用者。 此外, A的局部变量或参数不再有用,因此可以用B的参数和局部变量代替:
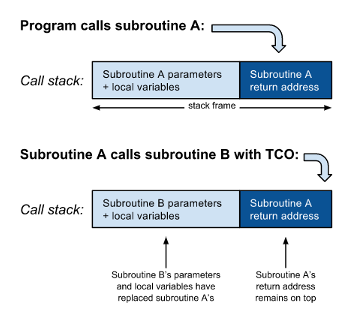
因此,通过用跳转指令替换子程序,可以有效地优化尾部位置的子程序调用。 因此,尾部呼叫优化也称为尾部呼叫消除 。 这很重要,因为每次递归子例程在没有TCO的情况下调用自身时,都需要更多的堆栈空间。 递归程序始终会存在用尽等效非递归程序所没有的空间的危险。 这对以功能样式编写的程序尤为重要。
当我们以命令式方式进行编程时,递归是一种可以在问题的性质适合时使用的工具; 我们会注意内存要求,并采取措施避免损坏堆栈。 由于递归是实现迭代的首选方法,因此该问题在函数式编程中假设了一个新的层面。 命令性程序可能能够很高兴地迭代一千万次。 一个功能程序不能执行相同的计算将是完全不可接受的。 尾调用优化使我们能够编写不会像这样增长堆栈的递归程序。 Guy Steele与Gerald Jay Sussman共同开发Scheme时,他们在语言定义中提出要求TCO必须由编译器实现。 不幸的是,并非所有功能语言都如此。
考虑一下Java的尾部递归程序的人为设计示例:
int sumReduce(List<Integer> integers, int accumulator) {
if (integers.isEmpty())
return accumulator;
int first = integers.get(0);
List<Integer> rest = integers.stream().skip(1).collect(toList());
return sumReduce(rest, accumulator + first);
} 据说对sumReduce的递归调用处于尾部位置,因为一旦对其进行了评估,则在外部调用中无需执行任何操作,只返回值。 使用默认的JVM内存设置,当仅用一万个整数列表进行调用时,此例程将引发堆栈溢出错误。
为了说明某些功能语言解决此问题的方式,让我们在Clojure中重写sumReduce函数:
(defn sum-reduce [integers accumulator]
(if (empty? integers)
accumulator
(let [[first & rest] integers]
(sum-reduce rest (+ accumulator first))))) 不建议在现实生活中这样写Clojure。 (reduce + integers)可以更好地完成同一件事,但是出于讨论的目的,我们将忽略它。 sum-reduce函数表现出与Java完全相同的问题:
user=> (sum-reduce (range 1 10000) 0)
StackOverflowError clojure.lang.ChunkedCons.next (ChunkedCons.java:41) 为了解决这个问题,Clojure提供了(loop (recur))形式:
(defn sum-reduce [integers]
(loop [[first & rest] integers, accumulator 0]
(if (nil? first)
accumulator
(recur rest (+ first accumulator))))) 现在,该函数完全可以求和一千万个甚至更多的整数(尽管reduce仍然更快):
user=> (sum-reduce (range 1 10000000))
49999995000000但这不是尾声优化。 Clojure文档将loop-recur描述为“一种hack,以便在clojure中可以进行诸如尾递归优化之类的工作。” 这表明JVM中不提供尾部调用优化功能,否则就不需要循环重现。 不幸的是确实如此。
回到我们开始的讨论,与TCO的重要区别是go to比循环构造更笼统。 它还可以优化相互递归。 通过将尾递归转换为循环是不可能的。 为了说明一个简单的例子,请考虑以下流行的保龄球游戏kata的Clojure解决方案:
(declare sum-up-score)
(defn sum-next [n rolls]
(reduce + (take n rolls)))
(defn last? [frame]
(= frame 10))
(defn score-no-mark [rolls frame accumulated-score]
(sum-up-score
(drop 2 rolls)
(inc frame)
(+ accumulated-score (sum-next 2 rolls))))
(defn score-spare [rolls frame accumulated-score]
(sum-up-score
(drop 2 rolls)
(inc frame)
(+ accumulated-score (sum-next 3 rolls))))
(defn score-strike [rolls frame accumulated-score]
(if (last? frame)
(+ accumulated-score (sum-next 3 rolls))
(sum-up-score
(rest rolls)
(inc frame)
(+ accumulated-score (sum-next 3 rolls)))))
(defn spare? [rolls]
(= 10 (sum-next 2 rolls)))
(defn strike? [rolls]
(= 10 (first rolls)))
(defn game-over? [frame]
(> frame 10))
(defn sum-up-score
([rolls]
(sum-up-score rolls 1 0))
([rolls frame accumulated-score]
(if (game-over? frame)
accumulated-score
(cond
(strike? rolls) (score-strike rolls frame accumulated-score)
(spare? rolls) (score-spare rolls frame accumulated-score)
:else (score-no-mark rolls frame accumulated-score))))) 该程序是相互递归的: sum-up-score调用score-strike , score-spare和score-no-mark ,并且这三个都返回到sum-up-score。 对sum-up-score的前向引用使得必须在开始时声明它。 所有调用都处于尾部位置,因此可以作为TCO的候选者(JVM可以做到),但是不可能使用循环递归。
在此视频中 ,Java语言和库架构师Brian Goetz解释了JVM不支持尾递归的历史原因:某些对安全敏感的方法依赖于对JDK库代码和调用代码之间的堆栈帧进行计数,以找出谁在调用它们。 TCO会对此进行干预。 他补充说,此代码现在已被替换,并且对尾递归的支持也在积压中,尽管优先级不是很高。 随着人们对函数式编程的兴趣日益浓厚,尤其是在JVM上运行的函数语言(例如Clojure和Scala)的增长,对JVM中TCO支持的需求也在增长。
翻译自: https://www.javacodegeeks.com/2017/12/tail-call-optimisation.html
尾递归优化















 2806
2806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}