





drill apache
在我的第一篇文章中,我展示了如何使用Azure市场中可用的MapR模板将启用Drill的群集快速部署到Azure云 。 在我的下一篇文章中,我向您展示了如何使启用了Drill的群集查询Azure存储帐户以及Azure SQL数据库 。 在本文中,我想重点介绍如何通过Power BI使用该群集作为数据源, Power BI是一种受Microsoft技术用户欢迎的数据发现工具。
数据集
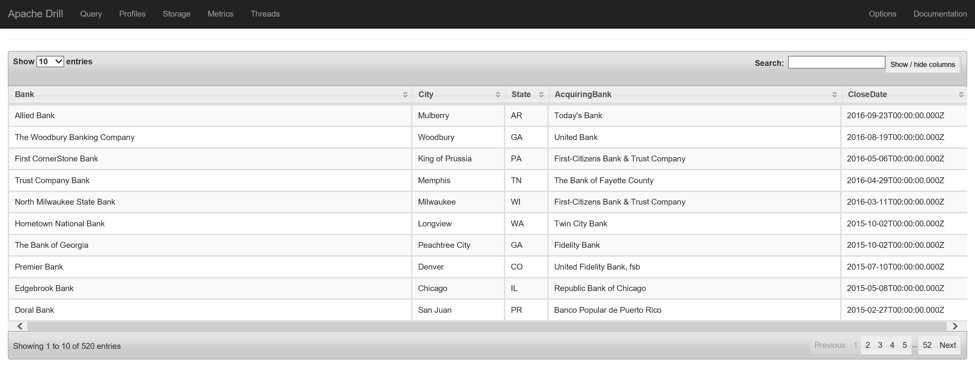
首先,我将数据集加载到我的Drill集群中。 为此,我将首先使用SysAdmin用户名(默认为mapradmin )和在群集部署时创建的密码在我的群集的节点0中打开SSH会话。 登录后,我将由联邦存款保险公司管理的失败银行清单下载到本地文件系统,并将CSV文件放入群集文件系统:
wgethttp://www.fdic.gov/bank/individual/failed/banklist.csv
sudo hadoop fs -mkdir /fdic/
sudo hadoop fs -put banklist.csv /fdic/banklist.csv
rm banklist.csv将文件加载到MapR文件系统中后,现在可以使用dfs插件在Drill中对其进行访问。 通过此查询,我将重点介绍自2008年以来关闭的银行:
SELECT
Bank,
City,
State,
AcquiringBank,
CloseDate
FROM (
SELECT
columns[0] as Bank,
columns[1] as City,
columns[2] as State,
columns[4] as AcquiringBank,
TO_DATE(columns[5], 'd-MMM-yy') as CloseDate
FROM dfs.`fdic/banklist.csv`
WHERE columns[0] <> 'Bank Name'
) a
WHERE DATE_PART('year', CloseDate) >= 2008;&nbsp
注意考虑将查询部署为Drill中的视图 。 这将使某些BI工具可以更轻松地获取模式信息,例如列数据类型。
注意您的存储插件可以配置为从CSV(和其他文本文件类型)中读取标题行。 这是由所示添加extractHeader属性来存储插件的文件类型定义做了这里 。 此配置性能更高,并且无需使用column [n]标识符即可直接引用列名称。 尽管如此,这仍然需要与存储插件相关联的这种类型的文件来一致地使用标题行。
与Power BI连接
通过Drill访问数据后,我现在可以集中精力通过Power BI进行连接。 我需要做的第一件事是确保我拥有最新版本的Power BI Desktop工具,可从此处免费获得。
接下来,我需要确定它是已安装到桌面的Power BI Desktop工具的32位还是64位版本。 为此,我启动Power BI,关闭启动屏幕,然后从“ 文件”菜单中单击“ 帮助” ,然后单击“ 关于” 。 出现的对话框标识应用程序的位数。
借助Power BI的已知性,我现在可以下载适用于Drill的ODBC驱动程序 ,将驱动程序的精度与应用程序的精度进行匹配。 (如果您正在阅读ODBC驱动程序随附的说明,则无需配置该驱动程序,而无需安装MSI支持的基本安装。)
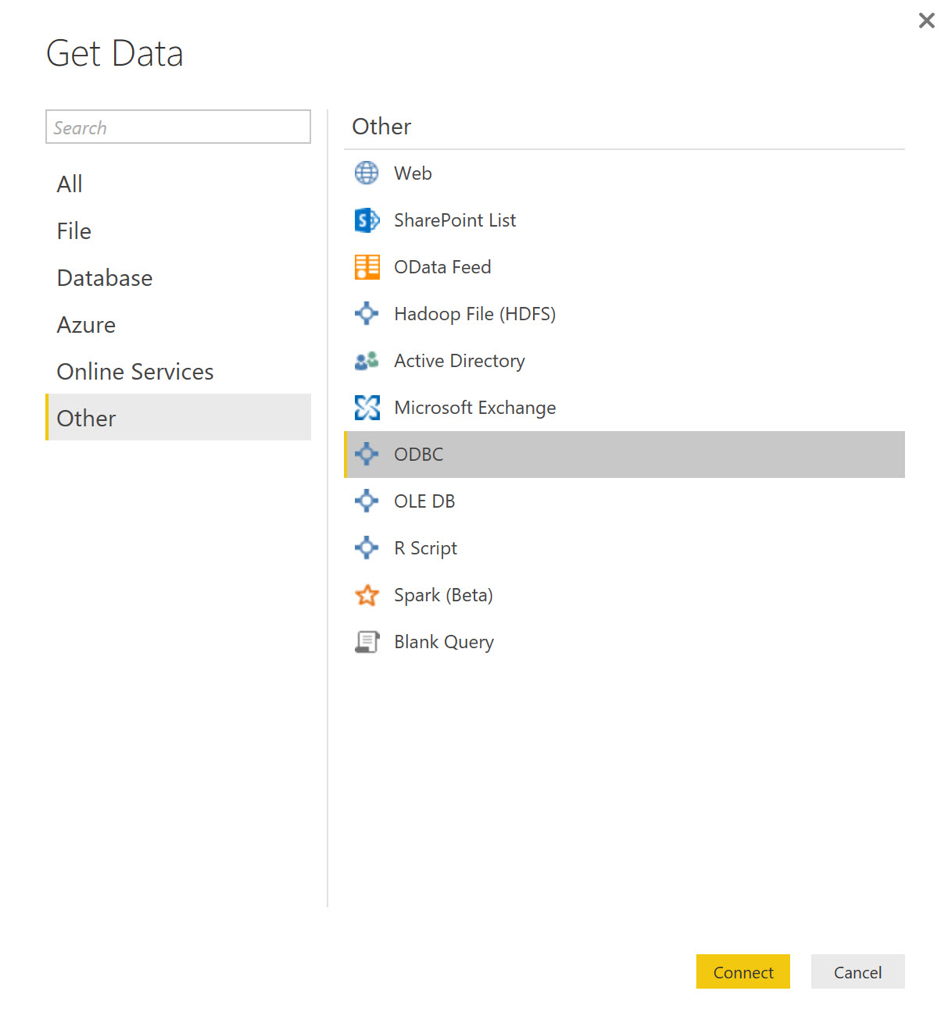
现在一切就绪,我启动Power BI,并从初始屏幕中选择Get Data 。 在出现的“ 获取数据”对话框中,从左侧导航栏中选择“ 其他 ”,然后在结果列表中选择“ ODBC ”。
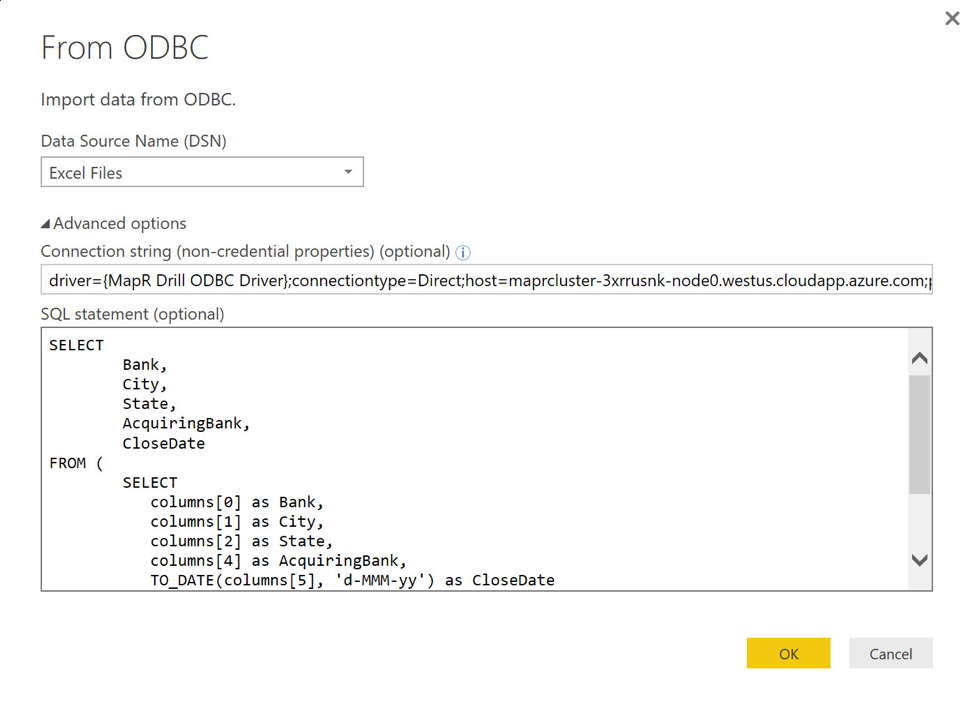
单击“ 下一步”将转到“ 来自ODBC”对话框。 在这里,我单击“ 高级”选项项,忽略“ 数据源名称”(DSN)下拉列表,然后输入一个连接字符串,并用适当的替代项代替host参数:
驱动程序= {MapR Drill ODBC驱动程序};连接类型=直接;主机= maprcluster-3xrrusnk-node0.westus.cloudapp.azure.com;端口= 31010;身份验证类型=无身份验证
请注意,连接字符串采用直接连接类型,表示该应用程序将直接与集群中的一个节点(由host参数标识)直接对话,而不与ZooKeeper服务对话。 鉴于我在早期部署期间对网络安全组所做的更改,ZooKeeper正在群集中使用,但未在外部公开。 即使暴露了ZooKeeper,它也会使用其内部名称跟踪群集的节点,以使包含群集的虚拟网络外部的任何应用程序都无法利用ZooKeeper中的信息来形成连接。 这里唯一起作用的选项是直接连接类型。
注意有关到Azure部署的Drill群集的网络连接的更多信息,请查看此博客文章 。
还要注意,“ 无身份验证”选项被设置为使用模板部署的Drill环境默认为该身份验证类型。 如果您更改集群采用的身份验证类型 ,则需要为此参数选择其他选项 。
返回到“ 从ODBC”对话框,我从上方将SELECT语句输入到SQL语句(可选)文本框中。 输入SQL语句时,请确保省略前面示例中使用的结束分号。
单击“ 确定”会将我带到“ 使用ODBC驱动程序访问数据源”对话框,要求我提供安全性信息。 由于我使用的是“ 无身份验证”身份验证类型,因此我只需从左侧导航中选择“ 默认”或“自定义”即可 ,并且不会在可选文本框中输入任何其他信息。
单击“ 连接”会将我带到数据预览页面。 如果需要使用Power BI的功能进一步调整数据的形状,可以单击“ 编辑”按钮,但是由于数据已经处于良好状态,因此只需单击“ 加载”即可继续。
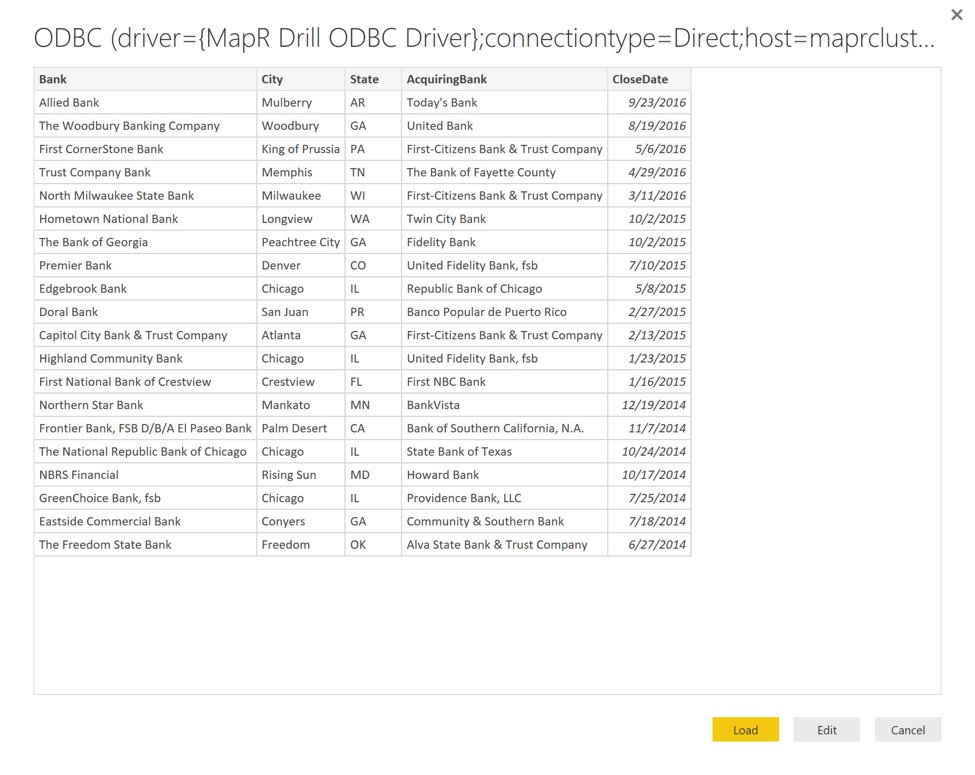
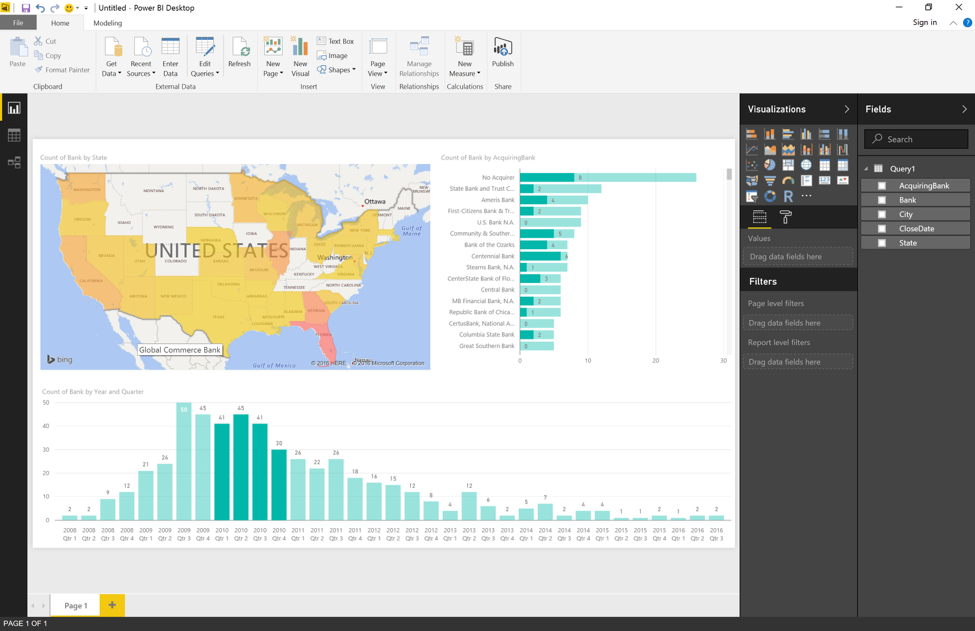
将数据加载到Power BI桌面应用程序后,我可以继续构建交互式报告。 如果您不熟悉Power BI,并且想了解有关如何构建报告的更多信息,请查看此处的视频和教程。
总结思想
我非常喜欢Power BI。 它是用于数据整形和建模的出色工具,即使使用免费版本,您所获得的功能也令人难以置信。 也就是说,我对Power BI团队有两个建议,以改善与Drill的交互性。
首先,我希望看到该应用程序提供对ODBC驱动程序的本机支持。 这将使用户能够连接到Drill群集,使Power BI工具能够检索架构信息,并允许用户以交互方式构建数据集而不必编写任何SQL语句。
其次,我希望看到该应用程序为针对Drill的实时查询提供支持。 Power BI的默认模式是将数据提取到非常强大的内存中缓存,这就是我在本演示中所做的。 但是对于某些具有快速查询响应能力的数据源(例如Spark),Power BI提供了一种针对后端执行实时查询的选项。 这样一来,就可以立即看到对后端的更新,而不必安排对缓存的自动刷新。 Drill能够支持此功能,因此我想在Power BI中看到此选项。
这里的好消息是Power BI团队维护了一个UserVoice网站,可以在其中提交改进建议并进行投票。 通过此站点收集的信息将直接影响Power BI团队的开发优先级,因此,如果您希望看到Power BI产品中实现的这些更改,请在此处对其投票。
翻译自: https://www.javacodegeeks.com/2016/12/connecting-apache-drill-power-bi-part-3.html
drill apache















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









