





生产环境微服务部署
Java开发人员? Takipi替代了生产JVM中的日志记录,并让您在所有已记录的错误,警告和异常之后查看源代码,调用堆栈和变量状态– 试试Takipi
微服务的阴暗面:可能会出什么问题?
如今,似乎每个人都在使用微服务,而整体式架构则像崩溃老旧城堡一样受欢迎。
某些趋势引起的公众关注经常被夸大,不能反映实际情况,但是这次感觉更像是共识。 微服务迭代关注点分离的基本原理,并根据工程师团队的见解命名,这些工程师为需要解决的实际问题制定了解决方案。
在这篇文章中,我们将扮演魔鬼的拥护者,分享社区和用户的一些见解,研究生产中微服务的主要问题–以及如何解决它们。
新帖子:5种在生产中不支持微服务的方法https://t.co/RfdxwrE5qm pic.twitter.com/I5J1h0JEUW
— Takipi(@takipid) 2016年5月5日
微服务的另一面
关注点分离不是一个新概念,也不是分布式计算。 好处是巨大的,但是它们的代价通常是时间和金钱上的更高的运营成本。 混合两者,您会得到各种麻烦问题的皮氏培养皿。 将其投入生产后,问题就会翻两番。 调试救援,哦,等等...
调试并不是要解决问题。
正如布莱恩·坎特里尔(Bryan Cantrill) 在QCon上的讲话中指出的那样,“调试已演变成一种口头传统,民间传说中的问题已经消失”。 实际上,它更像是一门科学,了解系统是如何工作的,而不是我们如何思考它的工作。
调试不仅是次要任务,而且是一个基本问题。 Maurice Wilkes爵士是有史以来第一个创建的程序之一的调试器,他已经意识到调试对开发人员的主要作用:
“在1949年,我们开始编程时,我们惊讶地发现,正确地编写程序并不像我们想象的那么容易。 调试必须被发现。 我记得那一刻的确切瞬间,当我意识到从那时起我的一生中有很大一部分将被用来寻找自己程序中的错误”。
我们被认为只是使问题消失。 真正的挑战是了解系统的实际工作原理。
问题1:好像监视整体程序还不够困难
无论您是逐步将单片应用程序分解为微服务,还是从头开始构建新系统,现在都需要监视更多服务。 这些都很可能:
–使用不同的技术/语言
–住在其他机器/容器上
–有自己的版本控制
关键是要进行明智的监控,系统会变得高度分散,并且对集中式监控和日志记录的需求也越来越强,这样才能更好地了解正在发生的事情。
例如,在最近的“ 持续讨论”播客中描述的一种情况是不良版本,需要回滚。 通常,对于整料来说,这是一个简单的过程。 但是……我们现在有微服务。 因此,我们需要确定哪些服务需要回滚,回滚对其他服务的影响是什么,或者也许我们只需要增加一些容量,但是这可能会将问题推到下一个服务排队。
要点1:如果您认为监视整体架构非常困难,那么使用微服务则要困难10倍,并且需要在前期计划上进行更大的投资。
问题2:日志记录在服务之间分布
日志日志日志。 服务器每天都会生成GB的非结构化文本。 相当于IT排放的碳,以硬盘溢出和疯狂的Splunk账单/ ELK存储成本的形式出现。 顺便说一句,如果您正在研究Splunk或ELK,则应该查看我们最新的电子书:《 Splunk与ELK: 日志管理工具决策指南》 。
使用整体式体系结构,您的日志可能已经分散在不同的位置,因为即使采用整体式心态,您也可能必须使用一些可能记录到不同位置的不同层。 使用微服务–您的日志会进一步细分。 现在,在调查与某个用户事务相关的场景时,您必须从所有可能通过的服务中提取所有不同的日志,以了解问题所在。
在塔基皮,我们的团队通过在塔基皮上使用塔基皮来解决此问题。 对于来自生产JVM的所有日志错误和警告,我们将智能链接注入到日志中以进行事件分析。 包括它的完整堆栈跟踪和每帧的变量状态,即使它分布在许多服务/机器之间。
要点2:微服务就是将事物分解为单个组件。 副作用是,ops程序和监视也正在破坏每种服务,并失去了整个系统的功能。 这里的挑战是使用适当的工具将这些部件集中起来。
问题3:由一项服务引起的问题可能会在其他地方引起麻烦
如果您跟踪特定服务中的某个断掉的交易,则不能保证一定要归咎于您所寻找的同一服务。 假设您在服务之间具有某种消息传递机制,例如RabbitMQ,ActiveMQ,或者您正在使用Akka。
即使服务的行为符合预期,也可能会出现几种可能的情况:
–收到的输入是错误的,然后您需要了解是什么原因导致先前的服务不当
–结果的接收者返回了一些意外的响应,然后您需要了解下一个服务的行为
–这些依赖关系比1:1更复杂的可能性很高的场景呢? 还是有不止一种服务可以解决该问题?
无论问题是什么,微服务的第一步都是要了解从哪里开始寻找答案。 数据分散在各处,甚至可能根本不在日志和仪表板指标之内。
总结#3:有了整体,您通常会知道您正在寻找正确的方向,而微服务使您很难理解问题的根源以及应该从何处获取数据。
问题4:找出问题的根本原因
好吧,让我们继续进行调查。 现在的出发点是,我们已经确定了有问题的服务,提取了要提取的所有数据,从日志中收集了跟踪信息和一些变量值。 如果您拥有APM(例如我们在此处和此处也写过的New Relic,AppDynamics或Dynatrace),您可能还会获得一些方法处理时间过长的数据/对问题的严重性进行一些基本评估。
但是……那……实际的问题是什么? 真正的根本原因? 实际被破坏的代码。
在大多数情况下,您希望从日志中获取的可变数据的前几位不会移动针头。 它们通常会引出下一个线索,这要求您发现更多的内幕魔术,并添加另一个或多或两个受人欢迎的对数语句。 部署更改,希望问题不再发生,因为……有时仅添加日志记录语句似乎可以解决问题。 某种有害的逆墨菲定律。 那好吧。
要点4:当微服务错误的根本原因跨越多个服务时,至关重要的是要有一个集中的根本原因检测工具。 如果您使用的是Java /其他JVM语言,请务必查看我们在Takipi所做的工作 。
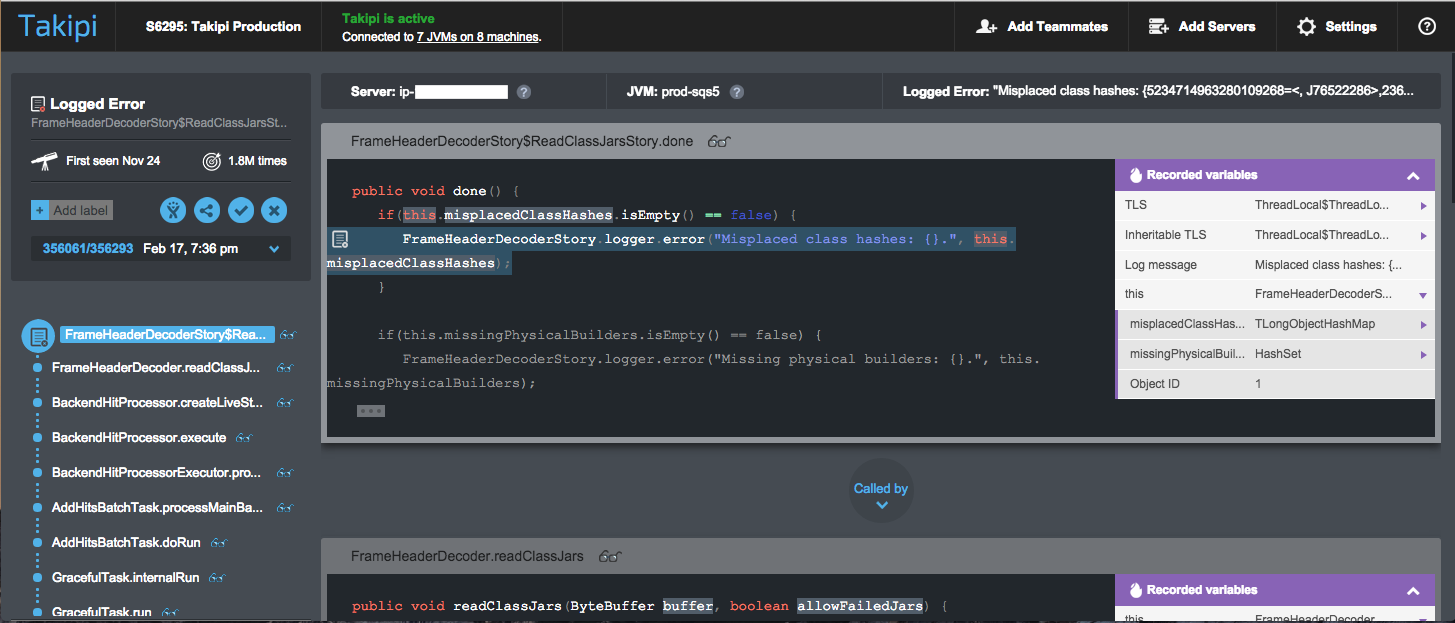
Takipi的错误分析仪表板–变量值覆盖堆栈中每一帧的实际代码 – 观看实时演示
问题5:版本管理和服务之间的循环依赖关系
在这里,我们要强调的“持续讨论”播客中提到的另一个问题是,从典型的整体架构中的层模型变为具有微服务的图模型。
这里可能发生的两个问题与检查依赖关系有关。
1.如果您的服务之间存在依赖关系的循环,则当某个事务可能陷入循环时,您很容易遭受分布式堆栈溢出错误的影响。
2.如果两个服务共享一个依赖性,并且您以可能影响其他服务的方式更新了该服务的API,则您需要一次更新所有三个。 这就提出了类似的问题,您应该先更新哪个? 以及如何使之安全过渡?
更多服务意味着每种服务的发布周期都不同,这增加了这种复杂性。 在一个版本中出现问题并在较新版本中出现问题时,重现问题将非常困难。
要点5:在微服务架构中,您更容易受到依赖关系问题引起的错误的影响。
最后的想法
调试立即使您进入解决问题的思路,这从字面上看是调试一词的直接含义。 当您考虑到系统的上下文来考虑它时,除了临时解决问题之外,还有很多其他功能。 这是关于了解系统的整体,如何使之滴答作响,以及事情的真相与希望的样子。
最重要的是,所有关于您使用的工具和您使用的工作流程的信息。 这正是我们在构建Takipi ,解决这些确切类型的问题以及将应用程序日志的世界颠倒过来面向生产应用程序当前状态时所想到的。
Java开发人员? Takipi替代了生产JVM中的日志记录,并让您在所有已记录的错误,警告和异常之后查看源代码,调用堆栈和变量状态– 试试Takipi
翻译自: https://www.javacodegeeks.com/2016/06/5-ways-not-mess-microservices-production.html
生产环境微服务部署















 726
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









