





adb摆脱数据线
订购一杯咖啡可以学到什么?
尝试索要比平常低得多的意式浓缩咖啡制成的卡布奇诺咖啡……通常,即使您以各种不同的方式索要,也不会得到您想要的。 我已经完成了这个实验:我喜欢咖啡,但是我需要喝非常稀的咖啡(主要是牛奶)和½的意式浓缩咖啡。 但是,当我以这种方式订购时,会得到常规强度的卡布奇诺咖啡,除非获得额外的强度。
为了做到这一点,我什至尝试过“喝一杯泡沫状的蒸煮的牛奶,一边喝一杯意式浓缩咖啡”,所以我自己只给一半的小费即可。 相反,服务员高兴地给我带来了一杯卡布奇诺咖啡,杯子里有两杯意式浓缩咖啡,侧面还有一枪。
问题在于,先入为主的观念会阻碍人们听到实际所说的话。
点咖啡时不仅要担心。 当我们研究新的和创新的大数据技术和技术时,可能会发生类似的情况。 我在伦敦Strata + Hadoop世界会议上最近发表的演讲中使用了卡布奇诺咖啡的例子。 主题为“建立更好的跨团队沟通”的演讲强调了识别和解决当具有不同经验和技能的两个小组聚集在一起时双方认为世界运作方式差异的重要性。 征求观众对您的意思的反馈是一种简单而有效的技术,可以揭示先入之见可能会在有用的交流方式中造成的障碍。
但是事实证明,这些问题不仅限于技能差异很大的人之间的交流。 当您考虑它时,在某个特定领域拥有大量经验可以使您更有可能被先入为主,尤其是在遇到真正的创新时,会误入歧途也就不足为奇了。 不太了解事物过去如何工作的人也不太容易误解新事物实际上是如何起作用的。 因此,具有特定领域经验的人们可能会错过新技术的关键方面。 考虑这个大数据示例,在过去的两个月中,我在讨论处理流数据的新技术时遇到了几次。
这是发生的事情:人们对从流数据中获取价值的兴趣Swift增长,随之而来的是对新兴的基于流的技术的兴趣。 当人们使用流数据时,他们不仅需要消息处理工具(例如Apache Spark Streaming , Apache Flink , Apache Apex或Apache Storm ),还需要消息传输技术-从连续事件中收集流数据并发布消息的技术。它到需要它的应用程序。 许多大规模处理流数据的人都熟悉一种称为Apache Kafka的消息传输。
这是先入为主的地方。通常,Kafka在与数据处理和数据存储不同的群集上运行。 因此,当人们听到一种称为MapR Streams的新消息传递技术时,他们可能会认为它也必须与流处理或数据存储一样在单独的群集上运行,就像Kafka一样。 那是不对的。 在做出此假设时,基于他们在Kafka上的经验,他们可能会错过认识到MapR Streams的关键优势之一的方法:尽管MapR Streams支持Kafka API,但它直接内置在MapR Converged Data Platform中 。
换句话说,在MAPR流短信传输功能并不需要一个单独的集群。
下图显示了这个想法:
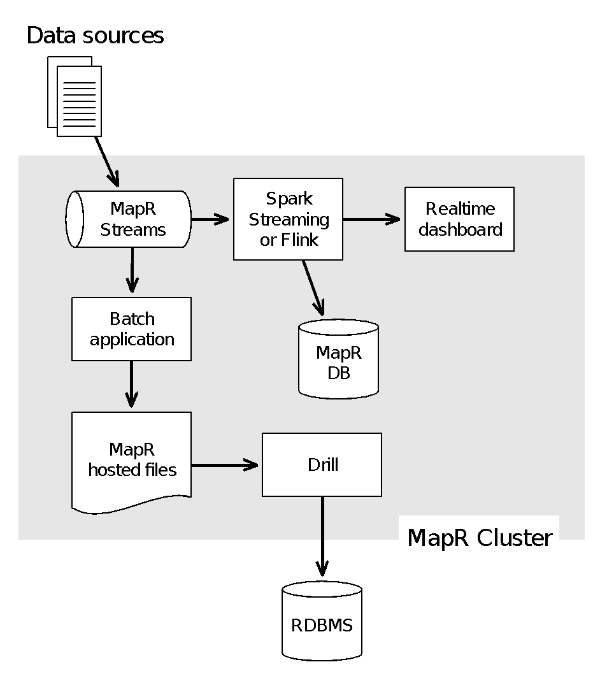
消息传输和流处理在同一群集上:此图显示,由于MapR Streams是MapR聚合数据平台的一部分,因此,消息队列的流传输与流处理在同一群集上运行(Apache Spark流,Apache Flink,Apache风暴等)。 MapR融合数据平台还具有集成的NoSQL数据库(MapR-DB)和分布式文件系统( MapR-FS )。 大数据生态系统中的各种开源工具(例如Apache Drill的大数据SQL引擎)也可以在同一集群上运行。
不需要单独的集群的想法对于那些习惯于Kafka的人来说非常令人惊讶,以至于他们甚至错误地认为MapR Streams消息传输也需要它,即使他们听到“已集成到MapR Converged Data Platform中”一词。 请注意,这种融合有许多有用的含义:
- 单一管理和安全性
- 通常需要较少的硬件
- 设计简单,文件存储,表和流传输均在同一平台上
- 消息的长期存储是可能的,因为MapR Streams中每个主题分区的副本不必放在一台机器上,而是可以分布在整个群集中
- 由于MapR Streams基于使MapR File System快速运行的相同技术,因此具有非常高的性能
挑战在于,如何改变思维方式,以便充分利用新技术? 对于人们过渡到大数据而言,这是一个广泛的问题-MapR Streams并非唯一。 随着人们开始处理大规模数据,他们不仅需要插入技术并了解要转动哪些旋钮,还需要做更多的事情。 为了从数据中获得最大价值,从业人员还需要改变他们对数据的看法以及设计解决方案的方式。
灵活性是一项新的优势,由于传统的假设,它可能会被忽略。 以下是发挥灵活性的几种方法。 现代大型分布式系统使其在成本和访问大量数据(有时甚至是原始格式)方面变得合理。 这意味着可以推迟有关如何为特定项目构造数据的决定-您不必在设置数据摄取时就知道要使用数据的所有方式。
为什么有帮助? 一方面,即使您尚未完全建立项目团队和计划,也可以在事件发生和数据可用时立即捕获数据。 这可能意味着流式传输数据或批量摄取,但是重点是要捕获数据并因此捕获未来的价值。 但这也意味着可以针对不同项目以不同方式转换和处理数据。 包括Apache Hadoop发行版在内的分布式系统引入了这种新的数据处理方式。 在《 Real World Hadoop》(O'Reilly,2015年)一书的第5章中,我的合著者Ted Dunning和我描述了有多少家公司通过卸载一些数据来减轻企业数据仓库的压力,从而迈入了大数据的第一步。昂贵的ETL到Hadoop集群上。 以后,其他组可能会处理相同的数据以用于NoSQL数据库,例如在MapR平台的情况下为MapR-DB 。 或者他们可能会进行不同的分析,然后将结果导出到Apache Solr或ElasticSearch中可搜索文档的字段中。
大数据SQL查询引擎Apache Drill是另一个非常灵活的工具。 令人惊讶的是,Drill支持标准ANSI SQL,但也可以直接用于各种大数据源,包括复杂的,自描述格式(例如Parquet和JSON),通常不需要或只需很少的预处理即可。 此功能不仅扩展了数据源的范围,而且使数据探索更加容易。
诸如Apache Kafka或MapR Streams之类的工具为开发提供了广泛的灵活性,因为基于流的体系结构可以使用流式消息队列来支持微服务方法。 我们将在流式架构的第3章 (O'Reilly,2016年3月)中描述其工作原理。
所有这些工具都违反了关于如何构造数据以及是否需要对其进行大量处理才能进行有用查询的先入之见。 它们使构建灵活的高性能架构变得很容易,这与不久前构建高性能应用程序的方式大不相同。
为了获得大数据方法的全部价值,请不要仅仅依靠您以前的经验进行假设。 认识到新技术不仅可以在大规模工作时节省时间和金钱,而且还为使用数据的新方法打开了大门。
当您听到有关新技术的消息时,请不要仅仅假设我要喝两杯意式浓缩咖啡。
想了解更多? 查看以下资源:
- Ted Dunning和Ellen Friedman的流媒体架构
- 使用Apache Drill下载MapR沙箱
- 超越实时数据应用白板演练

adb摆脱数据线















 1881
1881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









