





rdbms nosql
在过去的25年中,使用带有预定义架构的RDBMS构建了应用程序,该架构强制数据符合写入时的架构。 许多人仍然认为,即使数据集中的记录彼此之间没有关系,他们也必须对应用程序使用RDBMS。 此外,这些数据库针对交易用途进行了优化,并且必须出于分析目的导出数据。 NoSQL技术已经改变了这种模式,以提供突破性的性能改进。
这是我在新加坡Strata + Hadoop World上的演讲 。 我浏览了架构中包含100多个表的音乐数据库,并演示了如何转换该模型以用于NoSQL数据库 。 此博客文章是此演示文稿的摘要。

为什么如此重要?
让我们为从RDBMS到NoSQL + SQL的发展为什么如此重要做好准备:
- 我在过去20年中经历的90%以上的用例不是需要关系数据库的用例 。 他们需要某种持久存储。 在大多数情况下,选择这些关系数据库是因为它们得到了IT团队的支持,这使得生产非常容易。
- RDBMS数据模型比单个表更复杂 。 当您开始想遍历关系模型的关系时,它们很复杂。 一对多关系需要多个表,并且创建代码以保留数据需要时间。
- 推断(或删除)的键不使用实际的外键 。 这种做法使其他分析师很难理解这种关系。
- 事务处理表永远不会与分析表相同 。 从工程角度看,软件是为事务表编写的,然后您提出了一些ETL流程,以将数据转换为星型模式或要遵循的任何其他数据仓库模型,然后运行分析。 这些过程需要大量时间来构建,维护和运行。
此处的目标是创建“按需采购”业务,并缩短数据行动周期。 如果可以摆脱从事务表到分析表的创建ETL流程的麻烦,那么我将加快数据到操作的周期。 这是我的目标。
更改数据模型
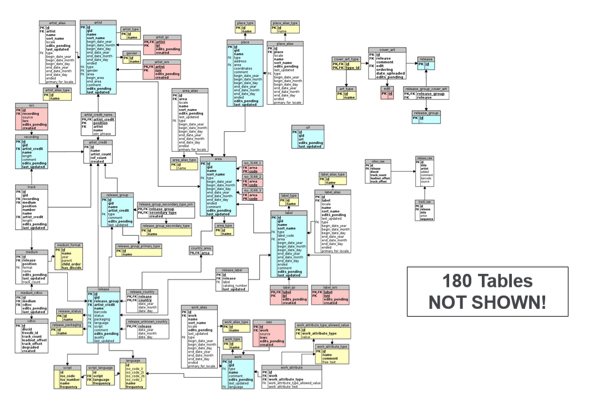
上面的数据模型实际上是音乐数据库的一部分; 实际上,该图中缺少180个表。 这表明这些类型的数据模型会变得非常复杂,非常快。 总体而言,该模式有236个表来描述七种不同类型的事物。 如果您是数据分析师,并且想深入研究该架构以查找新知识,那么编写查询以连接236个表可能并不容易。
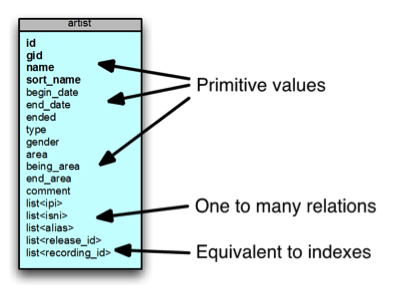
我们可以像艺术家那样获取一个子集,然后可以将其分解为一个表,如上所示。 在表格中,您可以在底部看到几个列表。 关系数据库并不真正支持列表概念。 对于多对多和一对多,您必须创建特殊的映射。 如果像这样将它们全部放在一个表中,则可以将数据对象的嵌套层次结构放在一起。 我们甚至可以在此处放置其他内容,例如对所需的其他ID的引用,然后可以支持我们拥有的所有不同用例。
从音乐数据库的角度来看,如果我说“给定关系数据库模式,为我找到猫王的所有作品”,那将是困难的。 但是使用上面显示的数据模型,这就是查询的样子。
寻找猫王
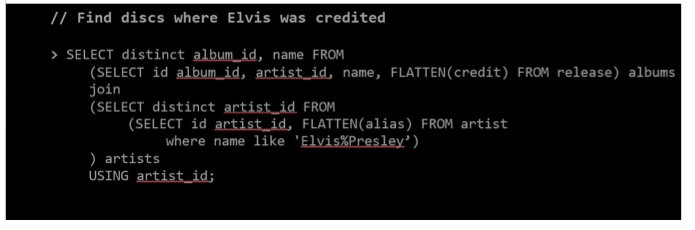
这是一个非常简单的嵌套选择查询。 我不必连接数百个表来查找所需的内容,因为我有一个可以查询的JSON文档模型。
好处
- 扩展的关系模型可以进行大量简化 。 如果您是软件工程师,则即使您使用的是Java Persistence API之类的代码,也可以编写代码将内部数据结构中的数据持久化到关系数据库中,但仍然需要编写代码,执行映射以及测试序列化和反序列化。 然后,您必须找出延迟加载的内容,而不是延迟加载的内容。 如果您可以将所有内容都编写为JSON文档,那么您将需要为持久性存储节省100倍的开发时间。
- 简化推动了自省 。 我们有Apache Drill之类的工具,可让我们查询JSON数据,您可以尝试一下。
- Apache Drill为扩展的关系查询提供了非常高性能的执行 。
JSON数据的新数据库
如果要处理事务性工作负载,则可能要使用文档数据库。 这是OJAI(开放JSON应用程序接口)出现的地方。OJAI是MapR-DB公开的文档数据库的API。 该API中的某些入口点会执行诸如插入,查找,删除,替换和更新之类的操作。
有关在Java中使用JSON以及在Java OJAI中创建,删除和查找文档的更多示例,请下载演示文稿 。
查询JSON数据等
如果您真的想简化数据到操作的周期,则需要能够进入并真正查询这些数据。 这意味着使数据科学团队,数据分析师和业务分析师能够获取数据。 如果您知道如何编写ANSI SQL,可以使用Apache Drill。 它不是SQL的变体。 它支持ANSI SQL2003。您具有熟悉SQL的能力,但同时也获得了NoSQL附带的好处,因此您不必担心如何针对不同的用例优化数据库。你有。
Drill支持即时模式发现
Apache Drill支持即时模式发现。 从写模式迁移到动态模式是一个非常艰巨的步骤。 因此,尽管Drill可以从Hive读取并使用Hive的metastore,但它不需要Hive。 如果要在笔记本电脑上安装Drill并开始查询文件,可以执行此操作。 像这样的技术具有如此低的进入门槛真是太好了。 它不需要Hadoop集群,除了Java虚拟机外不需要任何东西。
Drill的数据模型很灵活
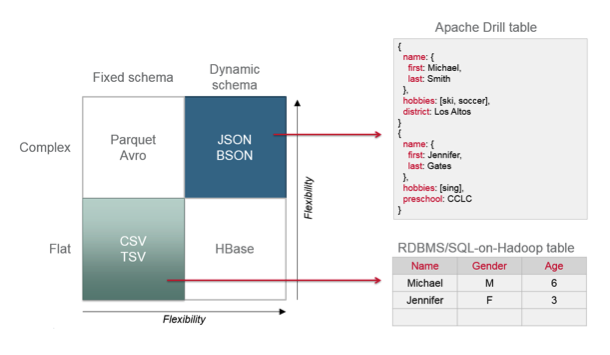
动态模式发现:这到底是什么意思? 我在该图中的右侧有一个示例。 这两个JSON文档实际上具有不同的字段。 当Drill逐条记录时,它会动态地动态生成和编译代码以处理其发现的架构发现。 它可以处理具有不同模式的所有这些不同记录。 其他SQL-on-Hadoop技术都无法做到这一点。
借助即时分析实现“按原样”业务
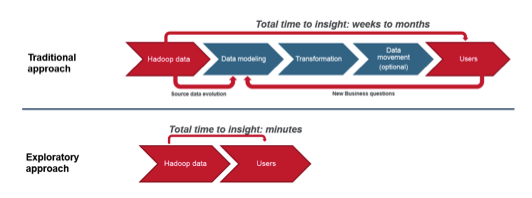
我们要做的是,在此过程中,我们基本上摆脱了所有中间人,使人们可以从数据中获取见解。 大多数企业的目标是使作为数据分析师和数据科学家的人员能够获取数据并尽快提出问题。 当您拥有所有这些阶段入口以获取数据以弄清楚如何将其与您拥有的数据仓库数据联接时,它就相当复杂,并且通常需要通过DBA。 请记住,我不是在告诉您摆脱您的DBA,也不是在告诉您放弃良好的数据建模实践。 但是,使用Apache Drill之类的工具,您可以使人们引入自己的数据源,并使用您在业务现场生成的数据跨这些数据源运行联接,从而缩短整个数据行动周期。 -飞。
随着Hadoop和其他大数据相关技术的出现,我们已经看到了一些变化。 技术在BI领域的变化非常缓慢。 在数据可视化中,它是第一个真正允许自助服务的领域。 这发生在大约十五年前,那时人们实际上可以创建自己的可视化文件而不必经过开发人员。 这很棒,因为它确实帮助人们更快地洞察了他们的数据。
自助数据探索的演进
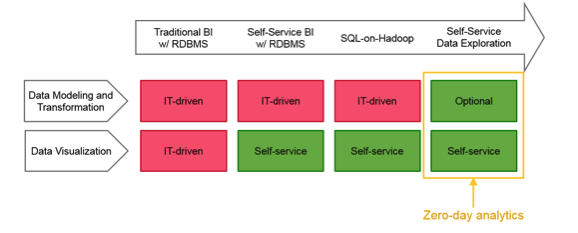
但是当我们使用SQL-on-Hadoop时,并没有真正改变。 这是一项技术交换。 开始使用Hadoop进行数据分析的人们将Hadoop换成了他们的数据仓库。 现在我们有能力做到这一点,以便他们可以做所有事情。 他们不必依靠别人来提出新的见解。 这创建了零时差分析的概念。 他们不必等待; 他们现在可以找到它。
钻取非常简单地分解查询。 它允许您指定存储插件,Drill可以连接到HBase,MapR-DB,MongoDB,Cassandra,并且其中的一个分支是为Apache Phoenix构建的。 当前正在为Elasticsearch构建连接器。 它可以查询定界文件,Parquet文件,JSON文件和Avro文件。 在谈到Drill时,我通常会谈到Drill是SQL-on-everything查询引擎。 您可以重复使用所有现有工具。 它与ODBC和JDBC驱动程序一起提供,因此您可以很轻松地将其插入开发环境中或BI工具中。
安全控制
Drill不需要第三方元存储来确保安全。 它使用文件系统安全性,这意味着没有新东西要学习,也没有复杂的东西要弄清楚。 您可以对视图和数据存储中的文件进行分组安全性查询。
通过钻取视图实现粒度安全
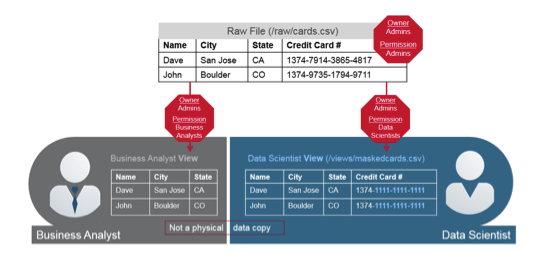
这使您能够在数据之上创建视图,然后围绕这些视图创建安全组。 如果您是数据所有者,则可以这样做,以便其他任何人都无法访问原始数据。 但是,如果我创建一个摆脱了信用卡号或将其屏蔽的视图,那么我可以做到这一点,以便您属于可以读取该视图的小组。 您没有直接访问数据的权限,但是通过安全模拟,它可以跳转用户,并确保可以按您所需的方式查询数据。 请记住,它不需要其他安全存储; 它使用文件系统安全性。 使用Apache Drill,安全性是逻辑,精细,分散的,并通过治理提供自助服务。 当对数据运行SQL查询时,这是一个非常引人注目的选择。
- 要深入了解将Drill与Yelp结合使用,请查看此演示文稿 。
想了解更多? 查看以下资源:
- 开始免费的MapR按需培训
- 使用AWS在云中进行测试驾驶练习
- 了解如何使用MapR沙盒将Drill与Hadoop结合使用
- 在10分钟内试用Apache Drill
- 为您的集群下载Apache Drill并开始探索
- 查看全面的教程和文档
- 深入了解健康选择
- 使用SQL + NoSQL的数据库架构的演变
翻译自: https://www.javacodegeeks.com/2016/02/evolve-rdbms-nosql-sql.html
rdbms nosql















 343
343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









