





 本文介绍了Apache Samza、Apache Storm和Apache Spark在流处理中的应用,强调了实时处理的重要性。文章对三个框架进行了比较,讨论了各自的特性,如Samza的简单架构、Storm的元组和流以及Spark的RDD操作。同时,文章探讨了流处理的交付模式和一次、至少一次、最多一次的语义,并提到了Apache Flink作为新兴的流处理选择。
本文介绍了Apache Samza、Apache Storm和Apache Spark在流处理中的应用,强调了实时处理的重要性。文章对三个框架进行了比较,讨论了各自的特性,如Samza的简单架构、Storm的元组和流以及Spark的RDD操作。同时,文章探讨了流处理的交付模式和一次、至少一次、最多一次的语义,并提到了Apache Flink作为新兴的流处理选择。
使用流式处理上传大文件
实时处理来自社交媒体流和传感器设备的数据变得越来越普遍,并且有很多开源解决方案可供选择。 这是我在Strata + Hadoop World 上所做的演示 ,在这里我比较了三个流行的Apache项目,它们允许您执行流处理:Apache Storm,Apache Spark和Apache Samza。 此博客文章是此演示文稿的摘要。 
总的来说,流处理从根本上来说是简单的……除了它实际上根本不简单之外! 优化是使这些流处理系统正常工作的关键,以及如何处理这些系统的反压力。 Kafka是这些流处理引擎的常见组件之一,它们确实有助于提供最大程度的功能。
如果您问三个不同的人,“哪个流媒体平台最快?” 您将得到三个不同的答案。 另外,如果仔细查看用例是什么,您将开始注意到,根据用例,技术和实现方式的不同,性能和里程也会有所不同。
您可能认为Storm是自切面包以来最伟大的事情,或者您可能认为这是自切面包以来最糟糕的事情。 您可能在任何一种实施上都有丰富的经验,或者您在其他任何一种实施上都具有可怕的经验。 因此,很难就这些平台之间的真实事实进行良好的对话。
让我们看一下交付模式。 你有:
- 最多一次 ,您有可能会丢失数据,您可以接受它,这没什么大不了的。
- 至少一次 ,可以重新发送邮件(不会丢失,但是您会重复)。 如果您的数据是幂等的,那么您就很好。 这是您应该使用的模型,永远不要考虑一次。
- 恰好一次 :每封邮件仅发送一次,并且一次(无损失,无重复)。 如果您的用例需要一次执行,请非常小心,因为无论您执行什么操作或如何处理它,当您开始在分布式系统中处理一次执行的语义时,复杂性水平就到了顶点。 这就是为什么我对在那里的流处理系统上工作的人们表示敬意的原因,因为他们知道这一点,并且他们并不在乎这些平台的功能。 告诉您一次准确的操作很容易的人可能会给您打个电话。 这很难做到,而且当您要转换为一次精确的模型时,需要做出很大的权衡。 您应该意识到这一点,并认真考虑如何在用例中利用流处理引擎来满足业务需求。
今日选项– Apache风格
这里要注意的基本事情是这三个都是实时计算系统,它们是开源的,低延迟的,分布式的,可伸缩的并且具有容错能力。
阿帕奇·萨姆扎(Apache Samza)
Apache Samza可能是最鲜为人知的,并且在其中存在的开源流引擎中,它的通话时间最少。 我认为这可能是最被低估的。 这项技术汇集了一些东西,使其非常简单。 我对简单的架构非常感激,因为您在架构中拥有的部件越多,事情就越复杂。
流和分区
- 流:不可变的消息
- 每个流包含一个或多个分区
- 分区:消息的完全有序序列
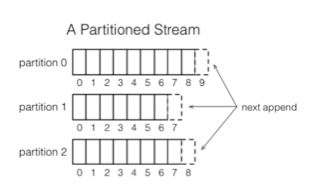
在处理流媒体时,我们希望有一种并行化工作的方法。 这是Samza破坏工作的方式-您定义密钥,对数据进行分区并获得所需的性能。 Samza使用的线程模型与Storm中使用的线程模型不同。 如果您关心的是资源利用,管理,能够适当地计划这些作业的资源消耗,那么您可能应该注意这一点。 这里重要的一点是,一切总是有序的。
工作与任务
我们拥有的下一个概念是工作和任务。 这实际上是工作程序代码,这就是要部署和分发的代码。 这是您的业务逻辑有效地发挥作用的地方。
对于熟悉Storm中拓扑的人来说,这与数据流图的概念相似。 它们在功能上相似,但是在实现方面它们甚至还不接近。 Samza带来的简便性意味着您将在此之前使用Kafka,因此,Samza将把所有东西放回这些舞台闸门之间的Kafka中。
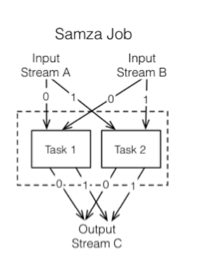
萨姆扎建筑
在部署和运行Samza方面,您可以将其他资源管理器插入YARN之外。 当前没有其他人插入。您可以在Samza前面插入其他排队系统,因为目前没有其他实现。
您实际上如何管理此处部署的容器? 我会再次考虑这点优势,因为您的工作被划分为多个部分,很容易预测,而且您知道事情将在何处着陆。 从根本上讲,这是Samza的核心。 我什至无法涵盖很多非常重要的实现细节,因此请查看下面列出的资源。
Apache Samza资源
阿帕奇风暴
Apache Storm在某些方面做得很好,而在其他方面则做得很痛苦。 风暴基于元组和流。 元组基本上就是您的数据以及数据的结构。 与Spark Streaming相比,我经常听到Storm。 两者之间最大的根本区别之一是,Storm像Samza一样处理单个事件,Spark Streaming则处理微型批次。
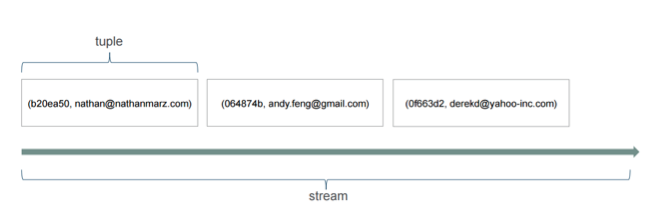
上图显示了外观。 在Spark Streaming方面,从概念上讲,您可以从概念上认为这些元组的所有概念都只是一个事件。
喷口
展望未来,我们已经有了Storm的喷口概念。 如果您熟悉Flume,我认为这是Flume中的资源。 喷口可以与队列(Kafka,Kestrel等),Web日志,API调用,文件系统(MapR-FS / HDFS)等对话。
螺栓
螺栓用于处理元组并创建新的流。 您可以通过“转换”,“过滤”,“聚合”和“联接”来实现业务逻辑。 您可以访问数据存储,数据库和API。 要了解的重要一点是,您不应将所有功能混为一谈,因为以后您将无法混合和匹配这些功能。 您应该将它们分开,并将它们链接在一起成为拓扑。
拓扑结构
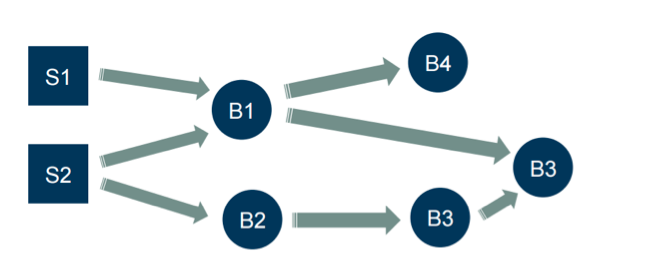
拓扑基本上是喷嘴和螺栓的有向图,如上所示。 像Samza一样,如果您想将代码绑定在一起,那么您就有一个模型。
流分组
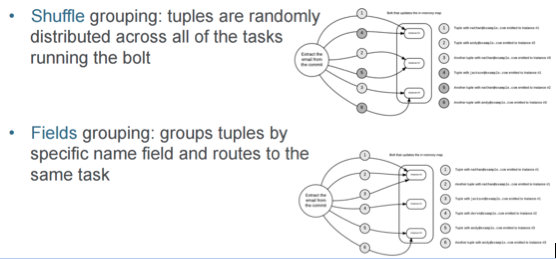
我们得到的下一个概念是流分组概念。 上图显示了两个示例-随机播放和字段。 实际上,您可以在Storm中使用七种不同的分组模型。 它具有良好的灵活性,并且事情已经被合理地考虑了。 从概念上讲,您需要确定消息的处理方式,消息的去向以及使用的工作人员。 在查看此模型以了解如何管理正在发生的事件时,您确实应该通读所有描述,以确保满足您的期望。 您可以很容易地选择错误的一个,并通过向每个螺栓发送相同的消息来轰炸您的系统。
任务和工人
从概念上讲,任务和工作人员与Samza的处理方式根本没有太大不同。 对于一项任务,每个喷口/螺栓在整个集群中执行的执行线程数相同。 工作程序是物理JVM,它执行拓扑所有任务的子集。 基于Samza与YARN的原生构建,它略有不同。
这就是Storm开始变得有趣的地方-我听到很多人谈论Trident,Trident在Storm上提供了一系列功能,这些功能使它与其他框架相比更具竞争力,逐个功能。
三叉戟-风暴的“级联”
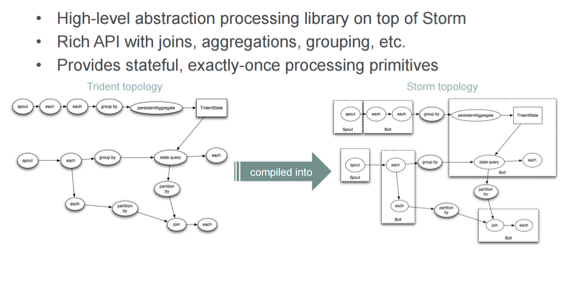
这里最大的好处是,您实际上使用Trident获得了一次精确的语义。 如果那对您很重要,那就很好。 从概念上讲,发生的事情是将这些Trident拓扑编译为Storm拓扑。 就我个人而言,我不一定总是喜欢那种必须从一个过渡到另一个的模型。
执行
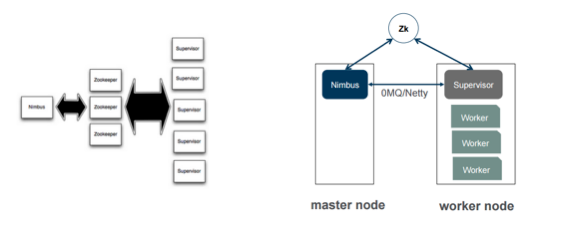
在执行方面,要注意的一件事是Storm中的Nimbus概念。 您可能会说Nimbus是单点故障。 从技术上讲是这样,但是由于它的运行方式,它并不是真正有害的单点故障。 如果崩溃,它可以非常快地旋转回去,并且对已经运行的任何内容都没有任何下游影响。 尽管这是单点故障,但对我来说并不是一个大问题。 如果在我的组织中实施它,那可能是我对实施Storm的最低关注之一。
请仔细阅读下面列出的Apache Storm资源,因为这里没有很多与Storm相关的细节。
Apache Storm资源
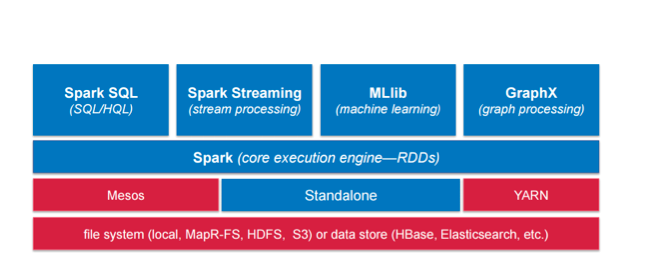
Apache Spark
Spark Streaming获得了一些出色的采用,部分原因是它与Spark框架的其余部分一起使用。 它可以访问属于Spark的所有组件,并且还具有一些强大功能。 如果您已经在使用Spark做其他事情,这可能会影响您决定使用哪种流框架。
让我们看一下集群管理器。 从顶部开始,您已经有了一个Spark驱动程序。 如果该驱动程序崩溃,则需要重新启动它。 以前的发行版中已经完成了许多工作,这使它更具弹性和高度可用性。
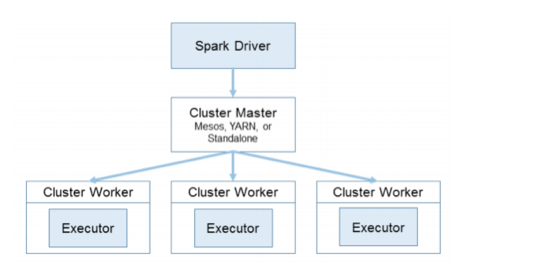
这是人们真正关注此框架的地方。 从独立的角度来看,您可以运行它,可以在EC2上运行,可以在YARN上运行,也可以在Mesos上运行。 对于每种功能,您的里程可能会有所不同,具体取决于您的需求和要求。 根据我的经验,Mesos可能会获得最佳性能,因为它是所有这些产品的第一款产品。 但是,如果您不使用Mesos,它也会与其余所有功能一起使用。
RDD操作
此处火花流的区别在于RDD(即弹性分布式数据集)。 这是这些流进入的地方。 然后将数据放入RDD,您将拥有Spark在此框架中提供的所有功能和计算能力。 同样,如果您对Spark有任何倾向,则可能会选择它; 您应该真正地对自己掌握的其他一切进行自我教育。 转换是这里的优势。 从RDD向您提供所有这些功能,您将看到该框架的最大好处。
火花流

- 用于流数据的高级语言运算符
- 容错语义
- 支持将流数据与历史数据合并
在分布式系统中,一次很难做到。 使其完美几乎是不可能的。 有许多不同的公司以不同的方式构建分布式系统,每个公司都会告诉您它有多复杂。 话虽这么说,这里的某些部分可以很好地工作,但这并不一定意味着您在所有用例中都可以百分百地保证不会丢失数据。 您需要弄清楚什么是用例,以及它们对实现的意义。
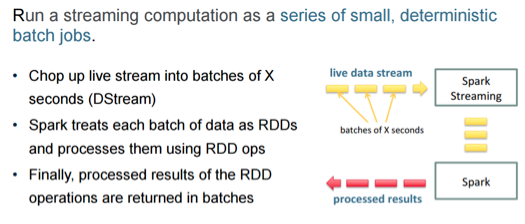
这里的原始概念实际上是DStream。 您的数据进入DStream,您可以访问它,执行数据处理,获得结果,并且可能会立即获得相当好的性能。
在这里重要的是,与单记录相反,使用微批处理时,您将具有一定的延迟和可操作的最小窗口时间。 例如,如果您在一天中的某些时间流非常慢,但是在一天中的其他时间流非常快,那么分批处理这些时间的窗口时间可能会对您产生很大的影响。 例如,如果您在一天中的高峰时段在一个窗口中结束了500个事件,但是每个窗口中只有一个事件,那么当您将RDD与一个对象一起使用时,您可能不会在结尾时感到高兴可能会对性能产生负面影响。 您必须考虑所用数据的用例以及它们如何协同工作。 开始测试时,请考虑一下。 了解您的实际使用模式非常重要。
Spark流:转换
- 无状态转换
- 有状态的转换
- 检查点
无状态和有状态转换-您是否在两次迭代之间保持状态? 如果必须重新启动过程,检查点将非常宝贵。 如果您要进行一系列的操作,则需要定期检查点,以便驱动程序崩溃时,可以从检查点重播它。
Spark流:执行
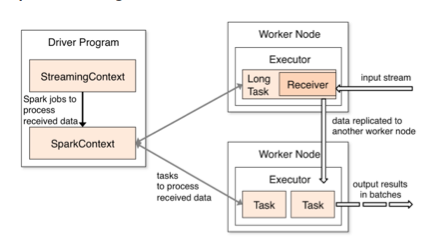
这里的接收器将类似于Storm中的喷口。 由于接收器很大,因此这被认为比在Storm中看到的要运行的代码重得多。 您最终要消耗大量内存才能运行接收器。 但是,我在社区中没有听到很多关于Spark的负面评论。
Apache Spark资源
- Apache Spark基础
- Learning Spark:闪电般的快速大数据分析
- Spark开发人员资源
- Apache Spark开发人员认证
- Apache Spark堆栈
- MapR Sandbox上Spark入门
比较方式
萨姆萨vs风暴vs星火
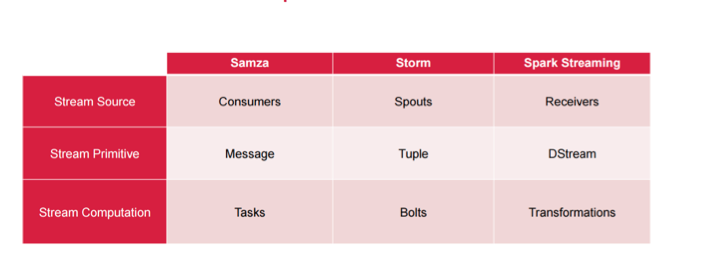
在术语方面,这些是每个框架之间的大致等效。 当您查看原语(消息,元组和DStream)时,它并不是很复杂。 如果您想对最适合您的方法进行全面评估,则可以将其用作复选框指南,以查看这些特定组件中的任何一个是否比其他组件更适合您的实现模型。 当然,那是在您确定了确切的语义要求之后,并且至少一次就足够了。
vs Storm vs Spark
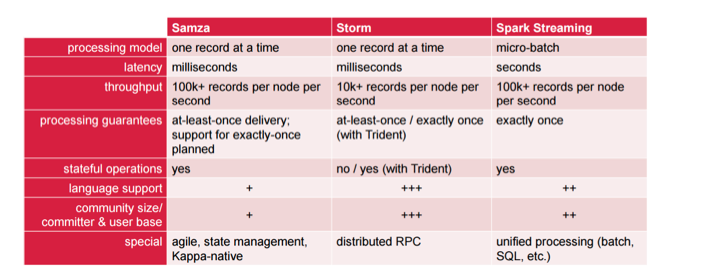
这个网格有点复杂。 处理模型选项是一次记录与微批处理的记录。 这对性能的可能性有很大的影响,并且直接导致延迟,这对于Spark Streaming来说是几秒钟。 对于吞吐量,它实际上取决于特定用例的需求。 在处理保证方面,Samza已经计划了一次准确的支持,但是目前还没有。 如果您只需要使用Storm一次,则可以使用Trident。
语言支持很可能是一个重要的决定因素。 如果您需要多种语言进行交互,那么使用Samza将会非常困难,因为您只能使用基于Java虚拟机的语言。 如果您对Python和Python都很满意,那么Spark Streaming就是很不错的选择。 如果您需要一堆其他语言,则几乎将您锁定在这两个选项之外,并且您将需要选择Storm。
什么时候使用什么?
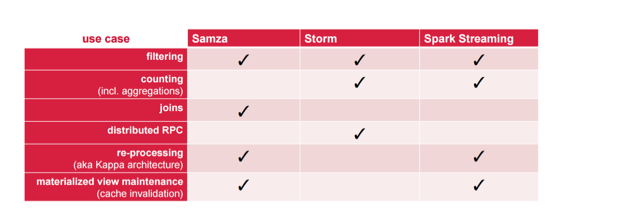
对我而言,最大的是Kappa-native的概念。 这是后处理的概念。 在我看来,重新处理是任何这些流框架中最重要的事情之一。 如果将来要更改代码,并且想要重新处理已发生的事件,则需要能够进行重新处理。 我认为这是一个很大的特色,太多人忽略了。
现在,这是否意味着其他区域中没有复选框表示他们没有该复选框? 否。请注意,此表的目的是显示每个项目的优势领域。 例如,如果您想进行计数,那么在大多数情况下,Samza不仅是最佳选择。
在这篇博客中,我回顾了三个开源流处理框架:Apache Storm,Apache Spark和Apache Samza。
自从提供此演示文稿以来, Apache Flink也已成为一种可行的选择,因为它是具有一流性能的流式处理优先处理引擎,且处理模型仅一次。
Apache Flink资源
请查看以下深入资源,以帮助您进行决策,并随时在下面的评论部分中提出任何问题。
翻译自: https://www.javacodegeeks.com/2016/02/stream-processing-everywhere-use.html
使用流式处理上传大文件















 508
508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









