





c:foreach中计数
这篇文章是基于我在圣何塞岩/的Hadoop World大会上介绍了2016年3月31日,您可以在幻灯片组的谈话在这里 ,你还可以找到这对dataArtisans博客在这里 。
连续计数
在这篇文章中,我们关注实践中看似简单,极为广泛,但出乎意料的困难(实际上是未解决)的问题:在流中计数。 本质上,我们有连续的事件流 (例如访问,点击,指标,传感器读数,推文等),并且我们希望按某个键对流进行划分,并在一段时间内产生滚动计数(例如,计算每个国家/地区过去1小时的访问者数量)。
首先,让我们看一下如何使用经典的批处理体系结构(即使用对有限数据集进行操作的工具)解决此问题。 在下图中,想象时间从左到右流动。 在批处理体系结构中,连续计数包含一个连续摄取阶段(例如,通过使用Apache Flume),该阶段会产生周期性文件(例如,在HDFS中 )。 例如,如果我们每小时计数,那么我们每小时都会生成一个文件。 然后,可以在诸如Oozie之类的调度程序的帮助下,在这些文件上调度周期性的批处理作业(使用任何类型的批处理处理器,例如MapReduce或Spark )。
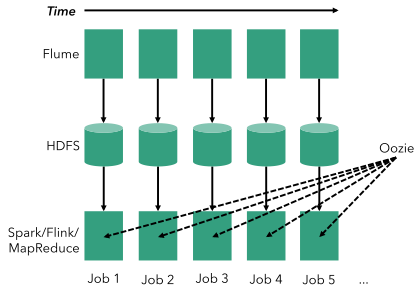
尽管可以使这种体系结构正常工作,但它也可能非常脆弱,并遇到许多问题:
- 高延迟:系统基于批处理,因此没有直接的方法可以对低延迟的事件做出React(例如,尽早获取近似值或滚动计数)。
- 活动部件过多:我们使用了三种不同的系统来计数传入数据中的事件。 所有这些都伴随着学习和管理成本以及所有不同程序中的错误。
- 隐式处理时间:假设我们要每30分钟而不是一个小时进行计数。 该逻辑是工作流调度(而非应用程序代码)逻辑的一部分,该逻辑将devops的关注点与业务需求混合在一起。 进行更改将意味着除了更改YARN群集中的负载特性(更小,更频繁的作业)以外,还需要更改Flume作业,Oozie逻辑以及批处理作业。
- 乱序事件处理:大多数现实流都是乱序到达的,即事件在现实世界中发生的顺序(如事件产生时附加到事件的时间戳所指示的,例如测量的时间)用户登录应用程序时通过智能手机访问)与在数据中心中观察事件的顺序不同。 这意味着属于前一个小时批次的事件在当前批次中被错误地计数。 确实,没有使用该体系结构解决此问题的简单方法。 大多数人只是选择忽略这一现实的存在。
- 批生产边界不清楚:“每小时”的含义在该体系结构中有点模棱两可,因为它实际上取决于不同系统之间的交互。 每小时的批次最多为近似值,批次边缘的事件最终在当前或下一个批次中结束,几乎没有保证。 实际上,将数据流分成每小时的批处理是最简单的时间划分方式。 假设我们不希望针对简单的每小时批次而是针对活动会话(例如,从登录到注销或不活动)生成聚合。 对于上述架构,没有直接的方法可以做到这一点。
为了解决第一个问题(高延迟),大数据社区(尤其是Storm社区)提出了Lambda体系结构的想法,将流处理器与批处理体系结构结合使用以提供早期结果。 该体系结构如下所示:

图的下部是我们之前看到的相同的批处理体系结构。 除了以前的工具之外,我们还添加了Kafka (用于流式接收)和Storm,以提供早期的近似结果。 虽然这解决了延迟问题,但其余问题仍然存在,并且引入了两个以上的系统以及代码重复:需要在Storm和批处理程序中使用两个截然不同的编程API表示相同的业务逻辑,并引入了两个不同的代码库来维护两组不同的错误。 回顾一下,Lambda存在一些问题:
- 活动部件过多(以前和更糟)
- 代码重复:相同的应用程序逻辑需要用两种不同的API(批处理处理器和Storm)来表达,几乎可以肯定会导致两组不同的错误
- 隐式处理时间(与以前一样)
- 乱序事件处理(与以前一样)
- 批次边界不清楚(与以前一样)
流式体系结构是解决所有这些问题的一种优雅而简单的解决方案。 在那里,将流处理器(在我们的示例中为Flink,但可以是具有特定功能集的任何流处理器)与消息队列(例如,Kafka)结合使用以提供计数:

使用Flink,这样的应用程序变得微不足道。 以下是用于连续计数的Flink程序的代码模板,该模板不会遇到任何上述问题:
DataStream<LogEvent> stream = env
.addSource(new FlinkKafkaConsumer(...)) // create stream from Kafka
.keyBy("country") // group by country
.timeWindow(Time.minutes(60)) // window of size 1 hour
.apply(new CountPerWindowFunction()); // do operations per window值得注意的是,流式处理与批处理方法之间的根本区别在于计数的粒度(此处为1小时)是应用程序代码本身的一部分,而不是系统之间总体布线的一部分。 我们将在本文的后面再讨论这一点,但是现在,要点是,将粒度从1小时更改为5分钟只需要在Flink程序中进行一次细微的更改(更改window函数的参数)。
计算需求层次
马斯洛的需求等级描述了人类需求的“金字塔”,即人类需求从简单的生理需求演变为自我实现。 受此启发(以及马丁·克莱普曼 ( Martin Kleppmann)在数据管理中使用同一个抛物线 ),我们将描述计数用例的需求层次:
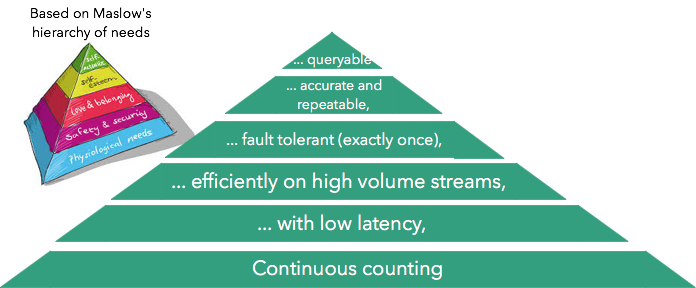
让我们从底层开始研究这些需求:
- 连续计数是指简单地连续计数的能力
- 低延迟意味着以低(通常为亚秒级)的延迟获得结果
- 效率和可伸缩性意味着可以充分利用硬件资源并扩展到较大的输入量(通常每秒处理数百万个事件)
- 容错是指在故障情况下正确完成计算的能力
- 准确性和可重复性是指能够重复提供确定性结果的能力
- 查询能力是指查询流处理器内部的计数的能力
现在,让我们遍历需求的层次结构,看看如何使用开源中的最新技术满足需求。 我们已经确定,进行连续计数必须使用流送体系结构(因此需要流处理系统),因此我们将忽略批处理系统,而将重点放在流处理器上。 我们将考虑最受欢迎的开源系统:Spark Streaming,Storm,Samza和Flink,所有这些系统都可以连续计数。 以下序列显示了如何在金字塔的每个步骤中消除某些流处理器:
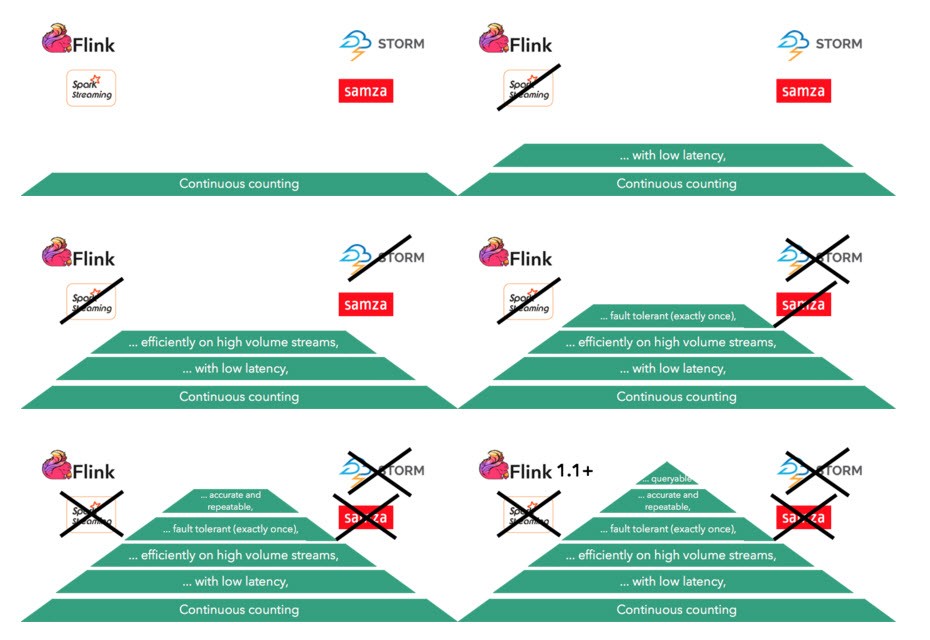
在金字塔中,我们看到了更复杂的计数需求如何消除了使用某些流框架的能力。 对低延迟的需求消除了Spark Streaming(由于其微批处理架构)。 有效处理大量流量的需求消除了Storm。 提供严格的容错保证(仅一次)的需要消除了Samza(和Storm),提供准确且可重复的结果的需要消除了Flink之外的所有框架。 现在,任何一个流处理器(包括Flink)都不满足最终需求,即在流处理器内部查询结果而不将其导出到外部数据库中,但这是Flink中即将推出的功能。
接下来,我们将详细进入所有这些阶段,并了解如何在每个阶段消除某些框架。
潜伏
为了测量流处理器的延迟,Yahoo!的Storm团队 去年12月发布了一篇博客文章和一个基准,比较了Apache Storm,Apache Spark和Apache Flink。 这对于空间来说是非常重要的一步,因为这是根据Yahoo!的实际用例建模的第一个流基准测试。 实际上,基准测试任务实际上在进行计数,这也是我们在本博文中重点介绍的用例。 尤其是,此工作执行以下操作(来自原始博客文章):
“基准是一个简单的广告应用程序。 有许多广告活动,每个活动有许多广告。 基准测试的工作是从Kafka读取各种JSON事件,识别相关事件,并将每个广告系列的相关事件的窗口计数存储到Redis中。 这些步骤试图探究对数据流执行的一些常见操作。”
雅虎获得的结果! 团队表明,“ Storm 0.10.0、0.11.0-SNAPSHOT和Flink 0.10.1在相对较高的吞吐量下显示出亚秒级的延迟,而Storm的延迟百分率最低,为99%。 Spark流1.5.1支持高吞吐量,但延迟相对较高。” 如下图所示:
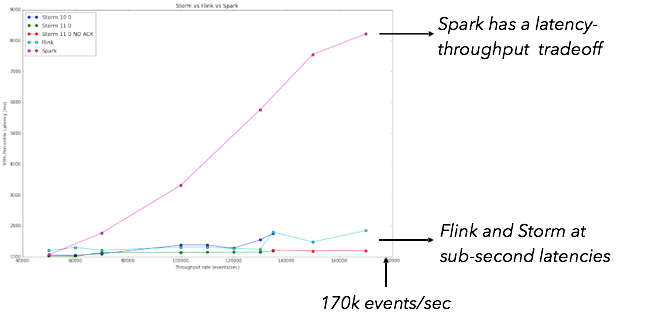
本质上,在使用Spark Streaming时,需要进行延迟吞吐量的权衡,而Storm和Flink都不会显示这种权衡。
效率和可扩展性
而雅虎! 基准测试是比较流处理器性能的绝佳起点,它在两个方面受到限制:
- 基准测试停止于非常低的吞吐量(每秒总计170,000个事件)。
- 基准测试中的所有作业(针对Storm,Spark和Flink)都不是容错的。
知道Flink可以实现更高的吞吐量后 ,我们决定对基准进行如下扩展 :
- 我们重新实现了Flink作业,以使用Flink的本机窗口机制,以便提供一次准确的保证(原始Yahoo!基准测试中的Flink作业未使用Flink的本机状态,而是在Storm作业之后建模)。
- 我们试图通过重新实现数据生成器来更快地输出事件,从而进一步提高吞吐量。
- 我们专注于Flink和Storm,因为它们是唯一可以在原始基准测试中提供可接受的延迟的框架。
使用与原始基准相似的群集(相同数量的计算机,但互连速度更快),我们得到以下结果:
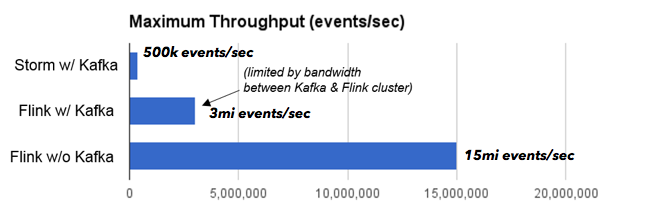
由于互连速度更快,我们设法将Storm扩展到比原始基准更高的吞吐量(每秒50万个事件)。 在相同的设置下,Flink扩展到每秒3百万个事件。 Storm作业在CPU上处于瓶颈,而Flink作业在运行Kafka的计算机与运行Flink的计算机之间的网络带宽上处于瓶颈。 为了消除瓶颈(与Kafka无关,而仅仅是可用的集群设置),我们将数据生成器移至Flink集群内部。 在这种情况下,Flink可以扩展到每秒1500万个事件。
尽管可以使用更多机器将Storm扩展到更大的数量,但值得注意的是,效率(有效使用硬件) 与可伸缩性同等重要 ,尤其是在硬件预算有限的情况下。
容错和可重复性
在谈论容错时,经常使用以下术语:
- 至少一次:在我们的计数示例中,这意味着在失败后可能会过度计数
- 恰好一次:这意味着无论有无故障,计数都是相同的
- 端到端仅一次:这意味着发布到外部接收器的计数将相同,无论是否失败
Flink对选定的源(例如,Kafka)仅保证一次,而端对端对选定的源和接收器(例如,Kafka→Flink→HDFS,又将要出现更多信息)仅进行一次端到端的保证。 这篇文章中检查的唯一可以保证一次匹配的框架是Flink和Spark。
与容忍故障同等重要的是,支持在生产中部署应用程序并使这些应用程序可重复的操作需求。 Flink通过称为检查点的机制在内部提供容错能力,该机制本质上可以定期获取一致的计算快照,而无需停止计算。 最近,我们引入了一个称为保存点的功能,该功能实质上使该检查点机制直接对用户可用。 保存点是Flink检查点,由用户在外部触发,是持久的,并且永不过期。 通过在明确定义的时间点获取状态的一致快照,然后重新运行应用程序(或与该时间点不同的应用程序代码版本),保存点使“版本”应用程序成为可能。 实际上,保存点对于生产使用至关重要,可以轻松进行调试,代码升级(即应用程序或Flink本身),假设分析和A / B测试。 您可以在此处阅读有关保存点的更多信息。
明确处理时间
除了能够从明确定义的时间点重播流式应用程序之外,流处理中的可重复性还需要支持所谓的事件时间。 解释事件时间的一种简单方法是“星球大战”系列:电影本身(事件发生时)的时间称为事件时间,而电影在影院上映的时间称为处理时间:
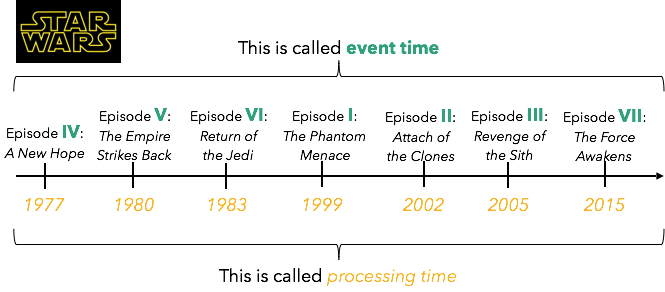
在流处理的上下文中,事件时间由记录本身中嵌入的时间戳来衡量,而执行计算的计算机(当我们看到记录时)所测量的时间称为处理时间。 当事件时间顺序与处理时间顺序不同(例如《星球大战》系列)时,流不按顺序排列。
事件时间支持在许多设置中都是必不可少的,包括在乱序流中提供正确的结果,以及在重播计算时(例如,如我们之前所见,在时间旅行场景中)提供一致的结果。 简而言之,事件时间支持使计算可重复且具有确定性,因为结果不依赖于一天中运行计算的时间。
在本文中讨论的所有框架中,只有Flink支持事件时间(其他人现在正在建立部分支持)。
可查询状态以及Flink中发生的事情
层次结构金字塔的技巧是能够在流处理器中查询计数。 使用此功能的动机如下:我们看到Flink在计数和相关应用程序中可以支持很高的吞吐量。 但是,这些计数需要以某种方式呈现给外部世界,即,我们需要能够实时查询特定计数器的值。 这样做的典型方法是将计数导出到数据库或键值存储中,然后在其中查询。 但是,这可能会成为处理管道的瓶颈。 由于Flink已经将这些计数保持在其内部状态,为什么不直接在Flink中查询这些计数呢? 现在可以使用自定义Flink运算符(请参阅Jamie Grier的内存中状态流处理,以内存速度运行 ),但本机不支持。 我们正在努力将此功能本身引入Flink。
我们正在积极研究的其他功能包括:
- 使用Apache Calcite的 Flink上SQL用于静态数据集和数据流
- 动态缩放Flink程序:这使用户能够在Flink程序运行时调整其并行度
- 支持Apache Mesos
- 更多的流媒体源和接收器(例如Amazon Kinesis和Apache Cassandra )
闭幕
我们看到,当涉及性能和生产使用时,即使是看似简单的流使用案例(计数)也具有更大的“深度”。 基于“需求层次结构”,我们了解了Flink如何在开源空间中将功能和性能进行独特的组合,以在实践中很好地支持这些用例。 ![]()
翻译自: https://www.javacodegeeks.com/2016/04/counting-streams-hierarchy-needs.html
c:foreach中计数















 1588
1588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









