





cassandra 集群
对于大多数承运人,我一直在法国快递的负责人Chronopost工作。 2013年,由于厌倦了RDBMS的扩展规模,我提出了一项使用C *进行实验的建议,以获取更快,可伸缩,更便宜且更具弹性的数据存储。 该项目非常成功,现在C *是我们IT战略的中心。 当我们需要对C *的JDBC访问时,我已经修改了旧版驱动程序以使其与C * 2.0+兼容,并在节点发现中使用了轮询连接方案。 最近,我几乎完全重写了JDBC驱动程序,将其包装在Datastax Java驱动程序周围,并获得了对异步查询,分页,UDT,负载平衡策略等的支持。我最近在2014年欧盟峰会上谈论Cassandra的时候,大数据巴黎2015和法国Devoxx。
Cassandra具有对多数据中心集群的著名内置支持,这使其在操作单个DC时一样透明。
通常采用多DC的原因有:
- 灾难恢复/增加弹性
- 与客户进行地域共处以降低延迟
- 添加高延迟数据中心以进行搜索或分析
无论出于何种动机,您都必须在构建应用程序之前预测哪种多DC模式将成为您的模式,否则可能会遇到麻烦,尤其是在出现故障的情况下。
正确选择多DC
Datastax网站上记录了将新DC添加到现有群集的过程 ,因此请按照以下说明操作。
尽管如此,在执行此操作之前,您必须了解一旦打开新的DC,您的应用程序/服务将如何运行。
请注意,新DC中的节点没有引导阶段,这意味着它们可以立即启动而没有数据,然后使用“ nodetool rebuild”命令进行追赶。
在重建完成之前(根据群集负载,要流式传输的数据量以及您正在使用vnode的事实,这可能需要几个小时),新的DC将无法返回之前插入的数据。它已打开。
如果您的负载平衡策略和一致性级别允许单独对查询使用新的DC答案,那么最终将导致查询结果不一致:如果不丢失,数据可能会不完整。
您必须做的是:
- 如果您的复制因素不允许新的DC自行到达,请至少使用QUORUM CL
- 或使用DCAwareRoundRobinPolicy + LOCAL_ * CL将流量隔离到您的历史DC
Datastax驱动程序(适用于所有受支持的语言)公开了负载平衡策略,这些策略用于选择查询的协调器节点。
其中,您会找到DCAwareRoundRobinPolicy,这是唯一允许基于协调器节点的数据中心过滤其策略。
过滤协调器只是本地化流量的第一步,因为一致性级别将决定所有DC中的哪些节点将参与查询执行。
本地CL(LOCAL_ONE,LOCAL_QUORUM,LOCAL_ALL等)将仅包含与协调器位于同一DC中的节点,而非本地CL(ONE,QUARUM,ALL等)可能涉及位于其他DC中的节点。
您的DC是同步的还是异步的?
使用本地CL意味着您的数据中心是异步的:即使遥远的DC尚未确认查询,查询也已完成。 在这种情况下,可以确保可以从同一DC读取成功插入到特定DC中的行(假设您使用的是LOCAL_QUORUM读/写或LOCAL_ONE / LOCAL_ALL的组合进行读/写)。
使用非本地CL意味着您的数据中心是同步的:查询可能涉及所有DC,并且鉴于您正在使用QUORUM进行读/写,因此可以通过任何DC立即读取通过任何DC插入的所有数据。
如何决定使用哪种模式?
具有同步DC的集群具有以下要求:
- DC之间的延迟低
- 集群中至少3个DC
- 集群中没有分析/搜索DC
如果您的DC通过高延迟网络链接进行通信,这将影响所有查询并影响其延迟。 您最终可能会在应用程序中表现不佳,并且偶尔会超时。 这里的一个示例是将不同的AWS区域用作不同的DC,以服务于来自欧洲数据中心的欧洲原始请求。
至少要有3个DC,因为如果您丢失了一个DC,剩下的DC仍然可以达到QUORUM。 如果只有2个DC,则丢失1个DC将阻止达到QUORUM,并且所有查询都将失败。
如果您需要使用SOLR(DSE)来创建搜索集群,或者使用Spark来创建分析集群,则当它们涉及可操作的单个分区查询时,负载下的延迟会破坏您的性能。 通过Spark访问Cassandra通常意味着读取给定表的所有SSTable,这会导致大量I / O和CPU负载。
在社区中众所周知,这种负载与Cassandra最初设计的负载不兼容:低延迟查询。
这为我们提供了具有异步DC的集群的以下特性列表:
- DC之间的高延迟
- 集群中恰好有2个DC
- 集群中至少有1个搜索/分析DC
在这两种情况下如何处理直流故障?
同步DC的故障转移非常简单:您(大多数情况下)无事可做。 使用QUORUM时,DC的丢失至少留下2个仍可达到CL的DC。
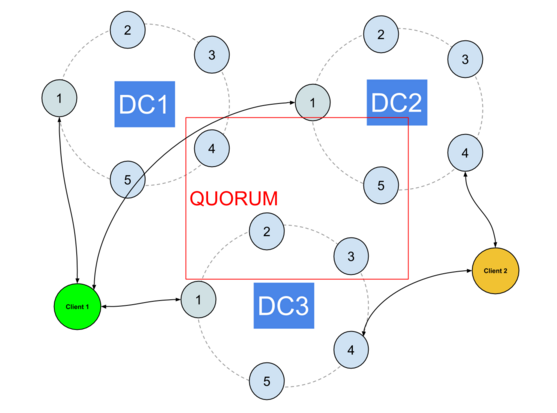
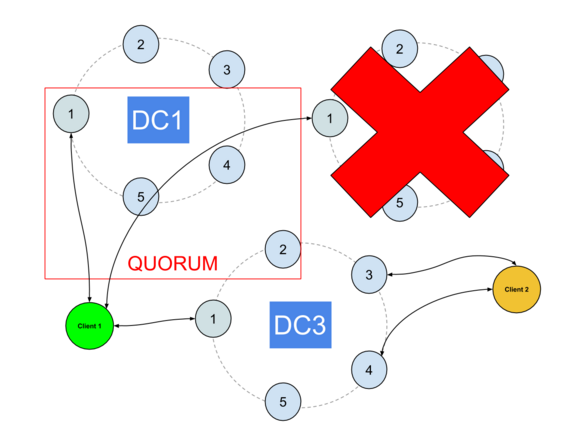
异步DC会使事情变得更加棘手。
默认情况下,DCAwareRoundRobinPolicy会阻止使用其他DC节点,以防本地DC发生故障,尽管可以通过允许某些远程节点用作协调器来覆盖它,但是如果您使用本地CL强制实施此操作,则可能会破坏一致性。
例如,假设您的本地DC在6小时内被关闭以进行维护。 这超出了默认的提示窗口,这意味着在恢复时有必要进行修复。 在此之前,其数据将与其他DC不一致。
如果驱动程序允许切换到另一个DC,一切正常,直到本地DC重新启动并再次用作主DC。
具有异步DC的故障转移方法
我选择了3种主要方法来处理DC之间的故障转移,它们都在基础架构的不同层上工作:
- 在请求路由级别
- 在应用程序/服务级别
- 在驾驶员级别
方法一
处理异步DC之间故障转移的最广为人知的方法也是需要更高水平的IT精通的方法。 服务和应用程序实例与Cassandra DC并置,并发布有关查询失败的指标。 这些指标用于确定DC是否仍在正常工作以及故障率是否达到某个阈值,服务请求将路由到另一个DC。
Netflix是实施此技术的一位著名Cassandra用户,它使用Zuul之类的工具将流量路由到AWS区域之间的微服务(这是其工作原理的简化视图,实际情况要复杂一些)。
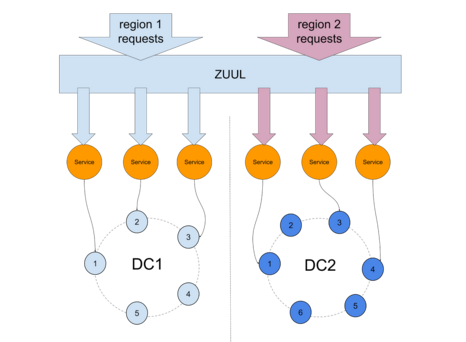
如果错误率达到DC1上定义的阈值,则将区域1请求路由到区域2,如Netflix的Flux所示 :
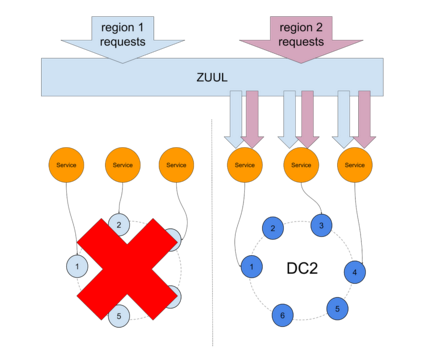
除其他外,这项技术使Netflix无需停机即可克服AWS重新启动的启示。
方法二
第二种方法是DIY,它假设您在每个应用程序中处理2个单独的Cassandra会话,并由您自己编写切换逻辑(请注意准备好的语句,每次切换会话时都需要重新准备它们)。
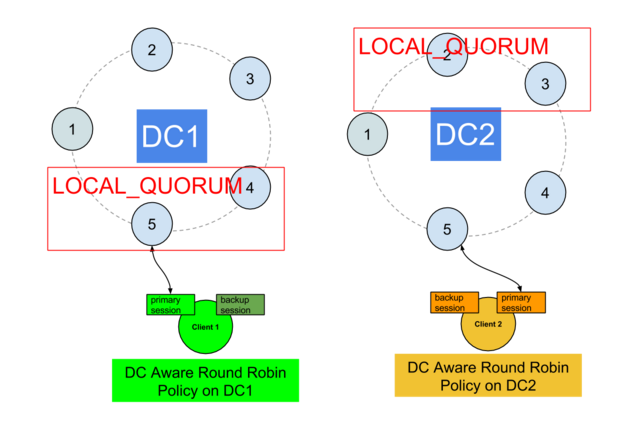
您必须处理检测故障率并切换到辅助连接。
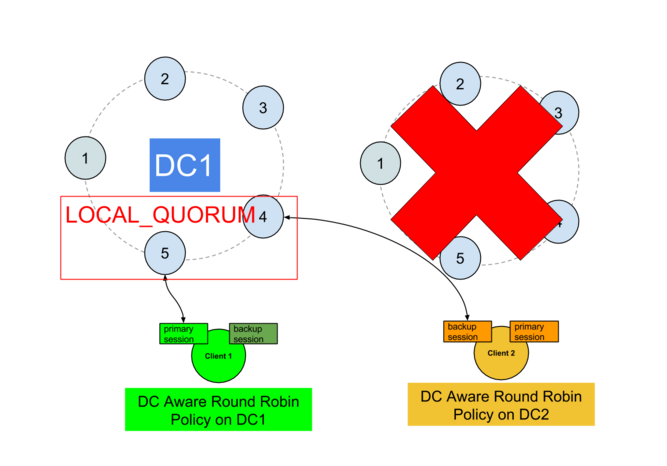
您还必须防止在恢复主DC时立即切换回主DC,因为这可能需要维修。
方法3
第三种方法是通过自定义负载平衡策略在驱动程序级别进行处理。
通过实施LoadBalancingPolicy接口,Datastax驱动程序有助于创建自己的负载平衡策略。
我已经在现有的DCAwareRoundRobinPolicy之上构建了这样的策略。 当前,它最适合于小型DC(<10个节点),但可以与较大的DC一起使用,我将其命名为DCAwareFailoverRoundRobinPolicy。
源代码可在GitHub上获得 ,编译后的包可从Maven中获取 。
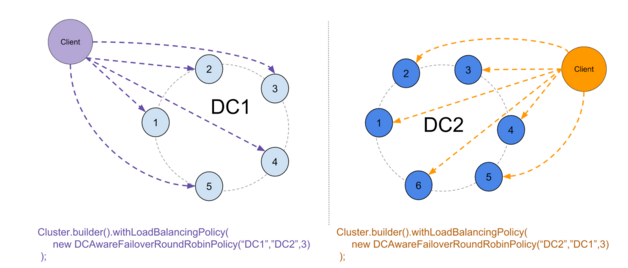
该策略采用3个参数:主DC,备用DC和将触发交换机的停机节点数。
它也可以纯粹防止切换后切换回初级DC,或者在认为安全的情况下允许这样做:
- 主DC下降的时间少于提示窗口
- 从主DC恢复起已经过去了足够的时间以允许对提示进行处理
一切就绪后,该策略的工作方式类似于标准DCAwareRR策略:
如果我们在主DC中丢失了太多节点,则策略将切换到备用DC:
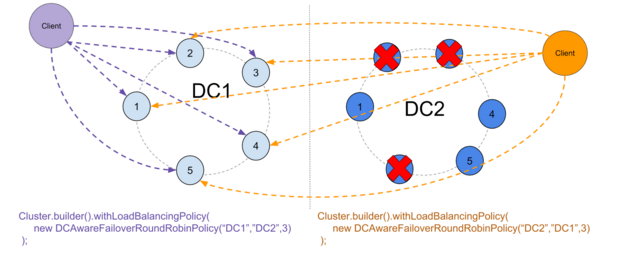
防止切换回去是为了防止不一致:
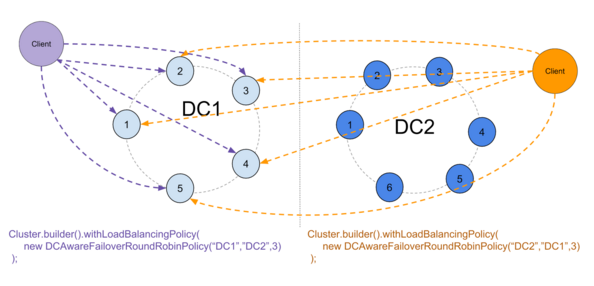
在小型DC中,复制因子为3,您可以合理地预期,丢失3个节点会使您在某些令牌范围内至少失去定额,而对于较大的DC则不是这种情况。
该策略的即将发布的版本将无法在关闭的节点上运行,但将在丢失的令牌范围上运行,因此仅当您在至少一个令牌范围上实际丢失了仲裁时才进行切换(如果数据正确分发,则应始终在其中存储数据)大多数范围)。
使用机架而不是数据中心
如果要至少有3个操作同步DC和1个或更多搜索/分析DC,则可能要使用机架而不是DC。
创建1个分成机架的可操作DC和1个分析DC,然后使用标准DCAware策略将所有流量定向到可操作DC,并使用本地CL避免将分析DC包含在低延迟请求中。
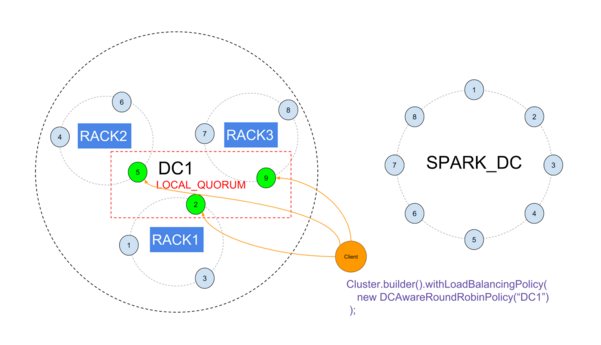
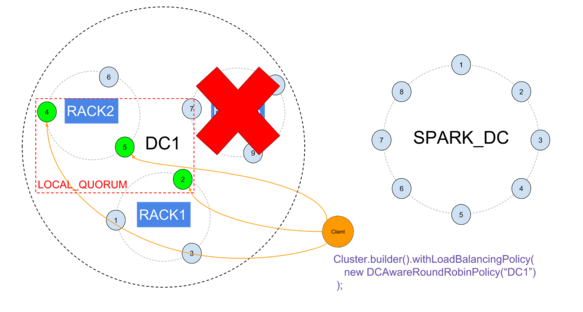
丢失一个机架不会影响LOCAL_QUORUM:
结论
Cassandra提供了支持多DC的强大功能,但请记住,虽然在集群设计中提供了更多灵活性,但它增加了故障转移过程的复杂性:您将不再只是在单个DC集群中选择正确的CL(提示:使用QUORUM),以跟踪应用级别的指标并适当地路由流量。
确定您的多DC群集的模式,然后选择最容易在您的应用中实现的故障转移方法。 另外,请检查您的应用程序是否都已“多DC准备就绪”,并了解新DC启动时会发生什么,以避免在重建阶段出现不一致。
翻译自: https://www.javacodegeeks.com/2016/04/going-multi-dc-cassandra-pattern-cluster.html
cassandra 集群















 1334
1334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









