





xp故障恢复控制台修复系统
面对现实吧。 我们正在创建的系统并不完美。 迟早,我们的一个应用程序将失败,我们的服务之一将无法处理增加的负载,我们的提交中的一个将引入致命的错误,一部分硬件将损坏,或者完全出乎意料的事情发生。
我们如何应对意外情况? 我们大多数人都在尝试开发防弹系统。 我们正在尝试创造前所未有的方式。 我们追求最终的完美,希望结果将是一个没有任何错误,可以在永不中断的硬件上运行并且可以处理任何负载的系统。 这是一个提示。 没有完美的东西。 没有人是完美的,没有什么是没有错的。 这并不意味着我们不应该追求完美。 我们应该在提供时间和资源的情况下。 但是,我们还应该接受不可避免的情况,并设计出并非完美的系统,而是能够从故障中恢复过来并能够预测可能的未来。 我们应该希望最好,但要为最坏的事情做好准备。
除了软件工程之外,还有很多弹性系统的例子,没有一个比生活本身更好。 我们可以以人类为例。 我们是基于一项长期的实验的结果,该实验基于数百万年的小规模和渐进式的改进。 我们可以从人体中学到很多东西,并将这些知识应用到我们的软件和硬件中。 我们(人类)拥有的令人着迷的能力之一就是自我修复的能力。
人体具有惊人的自我修复能力。 人体最基本的单位是细胞。 在我们的一生中,体内的细胞正在努力使我们回到平衡状态。 每个细胞都是一个动态的,活跃的单元,它不断地监视和调整自己的过程,并根据创建时所用的原始DNA密码恢复自身状态,并保持体内平衡。 细胞具有自我修复的能力,并能够制造新的细胞来替代已永久性损坏或破坏的细胞。 即使当大量细胞被破坏时,周围的细胞也会复制以形成新细胞,从而Swift替换被破坏的细胞。 这种能力不能使我们个人免疫死亡,但可以使我们非常有韧性。 我们不断受到病毒的攻击。 我们屈服于疾病,但是在大多数情况下,我们都是胜利的。 但是,将我们视为个人会意味着我们错过了全局。 即使当我们自己的生命结束时,生命本身不仅可以生存,还可以蓬勃发展,不断发展和适应。
我们可以将计算机系统视为由各种类型的细胞组成的人体。 它们可以是硬件或软件。 当它们是软件单元时,它们越小,它们就越容易自我修复,从故障中恢复,繁衍甚至在需要时被破坏。 我们称这些小型单位为微服务,实际上它们的行为类似于在人体中观察到的行为。 我们正在构建的基于微服务的系统可以自我修复的方式进行构建。 这并不是说我们将要探索的自我修复仅适用于微服务。 它不是。 但是,就像我们探索的大多数其他技术一样,自我修复可以应用于几乎任何类型的体系结构,但与微服务结合使用时可以提供最佳效果。 就像由组成整个生态系统的个体组成的生活一样,每个计算机系统都是更大事物的一部分。 它可以通信,协作并适应形成更大整体的其他系统。
自我修复的水平和类型
在软件系统中,自我修复术语描述了任何可以发现其无法正常工作并且无需任何人工干预即可进行必要更改以使其自身恢复到正常或设计状态的应用程序,服务或系统。 自我修复是指使系统能够通过不断检查和优化其状态并自动适应变化的条件来做出决策。 目的是使容错和响应系统能够响应需求的变化和故障恢复。
自我修复系统可以分为三个级别,具体取决于我们正在监控并采取行动的资源的大小和类型。 这些级别如下。
- 应用等级
- 系统级
- 硬件等级
我们将分别探讨这三种类型。
应用程序级别的自我修复
应用程序级别修复是应用程序或服务在内部进行自我修复的能力。 传统上,我们习惯于通过异常捕获问题,并且在大多数情况下,将其记录下来以进行进一步检查。 当发生这样的异常时,我们倾向于忽略它并继续(在记录之后),好像什么也没发生一样,希望将来能达到最佳。 在其他情况下,如果发生某种类型的异常,我们倾向于停止应用程序。 一个示例是与数据库的连接。 如果在应用程序启动时未建立连接,我们通常会停止整个过程。 如果我们比较有经验,则可以尝试重复尝试连接数据库。 希望这些尝试是有限的,否则我们可能很容易进入永无止境的循环,除非数据库连接失败是暂时的并且DB随后很快恢复联机。 随着时间的流逝,我们有了更好的方法来处理应用程序内部的问题。 其中之一是Akka 。 它使用管理程序及其所推广的设计模式,使我们能够创建内部自我修复的应用程序和服务。
Akka不是唯一的。 许多其他库和框架使我们能够创建能够从潜在灾难性情况中恢复的容错应用程序。 既然我们试图与编程语言无关,那么亲爱的读者,我将把它交给您,研究如何在内部自我修复应用程序。 请记住,这种情况下的自我修复是指内部过程,并且不提供例如从失败的过程中恢复。 此外,如果我们采用微服务架构,那么我们可以快速结束使用不同语言,使用不同框架等编写的服务。 真正由每种服务的开发人员来设计服务,使其能够自我修复并从故障中恢复过来。
让我们跳到第二层。
系统级别的自我修复
与依赖于我们内部应用的编程语言和设计模式的应用程序级别修复不同,系统级别的自我修复可以被概括并应用于所有服务和应用程序,而与它们的内部无关。 这是我们可以在整个系统级别上设计的自我修复类型。 尽管在系统级别可能发生许多事情,但是最经常监视的两个方面是流程失败和响应时间。 如果某个过程失败,则需要重新部署服务或重新启动该过程。 另一方面,如果响应时间不足,则需要缩放或缩放,这取决于我们达到了响应时间的上限还是下限。
从过程故障中恢复通常是不够的。 尽管此类操作可能会使我们的系统恢复到理想状态,但仍然经常需要人工干预。 我们需要调查失败的原因,更正服务的设计或修复错误。 也就是说,自我修复通常与调查失败原因密切相关。 系统会自动恢复健康,我们(人类)会尝试从这些故障中学习,并改善整个系统。 因此,还需要某种通知。 在这两种情况下(故障和流量增加),系统都需要进行自我监控并采取某些措施。
系统如何自我监控? 它如何检查其组件的状态? 有很多方法,但是最常用的两种是TTL和ping。
生存时间(TTL)
生存时间(TTL)检查要求服务或应用程序定期确认其可运行。 接收TTL信号的系统会跟踪给定TTL的最新已知报告状态。 如果未在预定时间内更新该状态,则监视系统将假定服务失败,需要将其还原到其设计状态。 例如,运行状况良好的服务可以发送HTTP请求,宣布其仍处于活动状态。 如果服务运行所在的进程失败,则将无法发送请求,TTL将过期,并且将执行响应措施。
TTL的主要问题是耦合。 应用程序和服务需要与监视系统绑定。 实现TTL将是微服务反模式之一,因为我们正在尝试以尽可能自治的方式设计它们。 此外,微服务应具有明确的功能和单一的目的。 在其中实现TTL请求将增加其他功能并使开发复杂化。
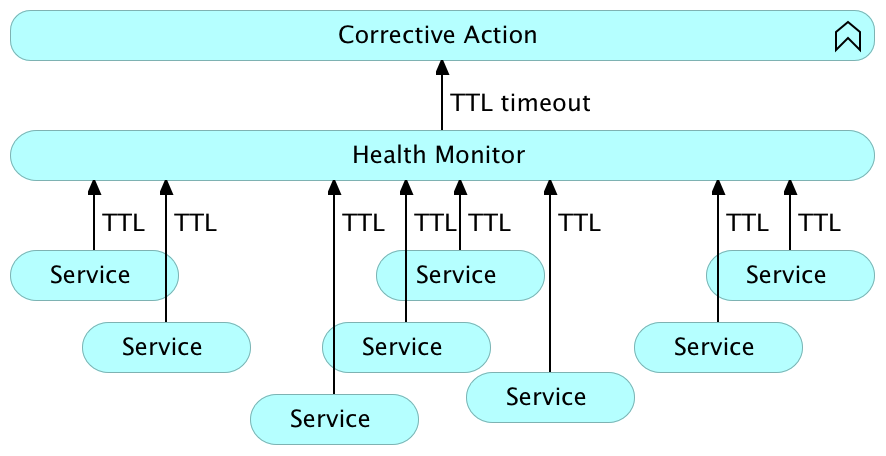
具有生存时间(TTL)的系统级自我修复
平
ping背后的想法是从外部检查应用程序或服务的状态。 监视系统应定期对每个服务执行ping操作,如果未收到响应或响应的内容不足,请执行修复措施。 ping有多种形式。 如果服务公开HTTP API,则通常是一个简单的请求,所需的响应应为2XX范围内的HTTP状态。 在其他情况下,当不公开HTTP API时,可以使用脚本或任何其他可以验证服务状态的方法来执行ping操作。
Ping与TTL相反,在可能的情况下,Ping是检查系统各个部分状态的首选方法。 它消除了在每个服务中实施TTL时可能发生的重复,耦合和复杂性。
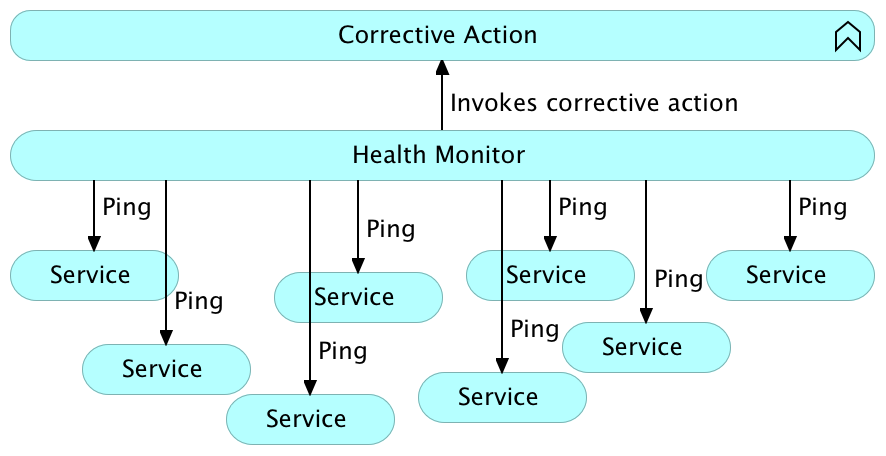
使用ping进行系统级自我修复
硬件级别的自我修复
实话实说,没有硬件自我修复之类的东西。 我们没有能够自动修复故障内存,重新修复损坏的硬盘,修复发生故障的CPU等的进程。 在此级别上进行恢复的真正含义是将服务从不健康的节点重新部署到健康的节点之一。 与系统级别一样,我们需要定期检查不同硬件组件的状态,并采取相应的措施。 实际上,大多数由硬件级别引起的修复将在系统级别发生。 如果硬件无法正常工作,则该服务很可能会失败,因此可以通过系统级修复来修复。 硬件级别修复与我们将在稍后讨论的预防性检查类型更多相关。
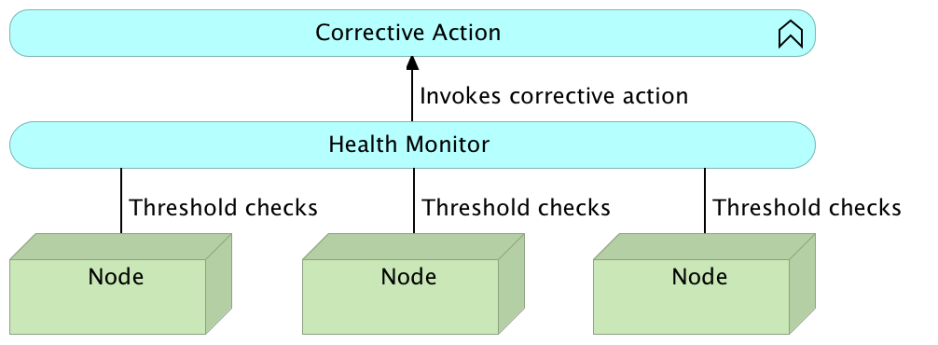
硬件级自我修复
除了根据检查级别进行划分外,我们还可以根据采取措施的时间进行划分。 我们可以对失败做出React,或者我们可以尝试防止失败。
React性愈合
实施了某种自我修复系统的大多数组织都将重点放在React性康复上。 检测到故障后,系统会做出React并将自身恢复到设计状态。 服务进程已死,ping返回代码404(未找到),采取了纠正措施,服务再次正常运行。 无论服务是由于其进程失败而失败,还是整个节点都停止运行(假设我们有一个可以重新部署到正常节点的系统),这都行得通。 这是最重要的治疗方法,同时也是最容易实现的治疗方法。 只要我们已完成所有检查以及在发生故障时应执行的操作,并且我们已将每个服务扩展到至少两个分布在单独的物理节点上的实例,我们(几乎)永远都不会停机。 我说几乎从来没有说过,例如,整个数据中心可能会失去电源,从而停止所有节点。 一切都是关于评估风险与防范风险的成本。 有时,值得在不同位置拥有两个数据中心,而在其他情况下则不然。 目标是努力实现零停机时间,同时承认有些情况下不值得尝试进行预防。
无论我们是在争取零宕机时间还是几乎零宕机时间,对于最小的设置,无功自愈应该是必不可少的,尤其是因为它不需要大量的投资。 您可能投资了备用硬件,或者投资了单独的数据中心。 这些决定与自我修复没有直接关系,但是与给定用例可接受的风险级别有关。 被动式自我修复投资主要在于知识,方法和实施时间。 尽管时间本身就是一种投资,但我们可以明智地花费时间,并创建一个适用于(几乎)所有情况的通用解决方案,从而减少了我们花费在实施这种系统上的时间。
预防性康复
预防性治疗背后的想法是预测我们将来可能遇到的问题,并采取避免这些问题的方式行事。 我们如何预测未来? 更准确地说,我们使用什么数据来预测未来?
相对简单但不太可靠的预测未来的方法是基于(近)实时数据进行假设。 例如,如果我们用来检查服务运行状况的HTTP请求之一在500毫秒内响应,我们可能想要扩展该服务。 我们甚至可以做相反的事情。 遵循相同的示例,如果接收响应的时间少于100毫秒,我们可能希望缩减服务规模,然后将这些资源重新分配给可能需要更多资源的资源。 在预测未来时考虑当前状态的问题是可变性。 如果在请求和响应之间花费了很长时间,则可能确实是需要扩展的信号,但这也可能是流量的暂时增加,而下一次检查(在流量峰值消失之后)将得出以下结论:需要除垢。 如果应用了微服务架构,这可能是一个小问题,因为它们很小且易于移动。 它们易于缩放和除垢。 如果选择此策略,单片应用程序通常会出现更多问题。
如果考虑到历史数据,预防性康复将变得更加可靠,但同时实施起来也将更加复杂。 信息(响应时间,CPU,内存等)需要存储在某个地方,并且通常很复杂,需要使用算法来评估趋势并得出结论。 例如,我们可能会观察到,在过去的一个小时中,内存使用量一直在稳定增长,并且达到了90%的临界点。 这将清楚地表明导致这种增加的服务需要扩展。 该系统还可以考虑更长的时间,并推断每个星期一流量都会突然增加,并提前扩展服务以防止长响应。 例如,从部署服务开始就不断增加内存使用量,而在发布新版本时突然减少内存使用量意味着什么呢? 可能是内存泄漏,在这种情况下,达到特定阈值时,系统将需要重新启动应用程序,并希望开发人员可以解决此问题(因此需要通知)。
DevOps 2.0工具包
这篇文章是《 DevOps 2.0工具箱:使用容器化微服务自动执行连续部署管道的自动 修复系统》一章开头的副本。 本章继续探讨自我修复架构 。 提供使用Docker,Consul Watches和Jenkins设置自愈功能以监控硬件和已部署服务的实际示例。 接下来是讨论和通过计划的缩放和除垢设置预防性修复的示例。 此外,本章只是本主题研究的第一部分,在探索集中记录以及收集和存储更高级的自愈用例所需的历史数据之后,该章节将继续。
本书介绍了不同的技术,这些技术可以帮助我们更好,更高效地构建软件,并将微服务包装成不可变的容器 ,并进行测试并连续部署到由配置管理工具自动 配置的服务器上。 它是关于零停机时间和回滚能力的快速,可靠和连续的部署。 它涉及到可扩展到任意数量的服务器,能够从硬件和软件故障中恢复的自我修复系统的设计以及群集的集中式日志记录和监视 。
换句话说,这本书使用一些最新和最好的实践和工具来涵盖整个微服务开发和部署生命周期 。 我们将使用Docker,Kubernetes,Ansible,Ubuntu,Docker Swarm和Docker Compose,Consul,etcd,Registrator,confd,Jenkins等。 我们将介绍许多实践,甚至更多的工具。
试试看,让我知道你的想法。
翻译自: https://www.javacodegeeks.com/2016/01/self-healing-systems.html
xp故障恢复控制台修复系统















 205
205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









