





spark集群计算本地数据
在这篇文章中,我将提到介绍Spark的第一篇论文, Spark:具有工作集的集群计算 。 这篇文章将是有关我的GSoC项目的基础文章之一。 您可以从此处阅读有关我接受的建议的帖子: GSoC 2015 Apache GORA的接受 。
MapReduce及其变体已成功用于大规模计算。 但是,大多数这些变体基于非循环数据流模型,因此不适用于许多应用程序。 Spark提供了一种解决方案,可在多个并行操作之间重用工作数据集。 迭代机器学习应用程序和交互式数据分析就是这类任务。 Spark支持这些功能,同时保留了MapReduce的可伸缩性和容错能力。
当我们仔细观察这两个用例时:
- 迭代作业:许多机器学习算法使用相同的数据集,并反复应用相同的功能来优化参数。 将每个作业定义为MapReduce作业时,每个作业应从磁盘重新加载数据,这会导致性能问题。
- 交互式分析:使用Hadoop时,每个查询都是单个作业,并从磁盘读取数据。 因此,它也会引起另一个性能问题。
Spark集成到Scala中,Scala是Java VM的静态类型化高级编程语言。 开发人员编写了一个称为驱动程序的程序,以使用Spark并行运行操作。 Spark为并行编程提供了两种主要的抽象,它们是RDD (弹性分布式数据集)和并行操作 (传递函数以应用于数据集)。 此外,Spark具有两种受限类型的共享变量,可在群集上运行的函数内使用。
弹性分布式数据集(RDD)
RDD是Spark的主要区别之一。 它们是对象的只读集合,不需要存储在物理存储中,如果节点发生故障,则始终可以重建RDD。
每个RDD由一个Scala对象表示,程序员可以通过四种方式构造RDD:
- 从共享文件系统中的文件
- 通过并行化Scala集合
- 通过转换现有的RDD
- 通过更改现有RDD的持久性。
RDD的持久性可以通过两种方式进行更改。 第一个是高速缓存操作,它使数据集保持惰性,但让数据集在第一次计算后被缓存。 第二个是保存操作,它使数据集可以评估并写入分布式文件系统。 缓存操作的工作原理类似于虚拟内存。 当内存不足时,Spark将重新计算数据集的所有分区。
在RDD上可能应用了几种并行操作:减少,收集和预测。
共享变量
Spark共有两种受限类型的共享变量: 广播变量和累加器 。 广播适用于大型只读变量并希望分发它的变量。 累加器适用于添加任务。
实作
Spark基于Mesos构建, Mesos是一个集群操作系统,可以让多个并行应用程序共享一个集群。
Spark的核心是RDD。 这是RDD的用法示例:
val file = spark.textFile("hdfs://...")
val errs = file.filter(_.contains("ERROR"))
val cachedErrs = errs.cache()
val ones = cachedErrs.map(_ => 1)
val count = ones.reduce(_+_)关键是,这些数据集存储为捕获每个RDD 沿袭的对象链。 以下是给定示例的沿袭链:
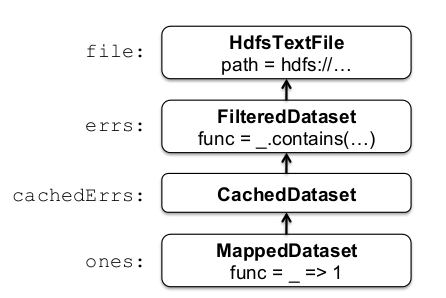
ERRS和那些懒惰RDDS。 当减少被调用时,输入块则是一个流媒体的方式来评估那些扫描,这些被添加到执行本地减少,且当地的计数发送到驱动程序。 此范例类似于MapReduce。
Spark的不同之处在于,它可以使某些中间数据集在整个操作中保持不变。 错误可以通过以下方式重用:
val cachedErrs = errs.cache()这会创建一个缓存的RDD,并且可以在其上运行并行操作。 首次计算后,它可以重用并有助于加快速度。
每个RDD对象都实现三个操作:
- getPartitions,返回分区ID的列表
- getIterator(partition),遍历一个分区
- getPreferredLocations(partition),用于任务调度以实现数据局部性。
不同类型的RDD在实现RDD接口方面的方式有所不同,例如HdfsTextFile, MappedDataset和CachedDataset。
性能
当在Spark和Hadoop上都实现逻辑回归时,这需要迭代的计算工作量,结果如下:
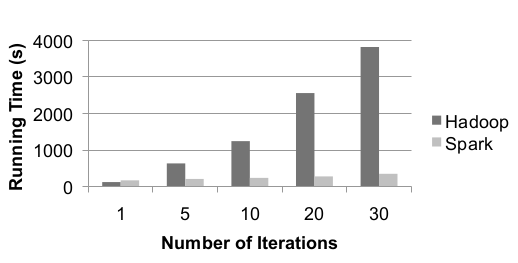
可以看出,由于使用Scala而不是Java,因此在第一次迭代时Hadoop的可能性更大。 但是,由于重复使用了缓存的数据,因此后续迭代仅需6秒。 与Hadoop相比,这代表了Spark的强大功能。
结论
这篇文章检查了Spark和集群计算。 人们认为Spark是第一个允许交互式使用高效通用编程语言来处理集群上大型数据集的系统。 它的核心功能是RDD,它还有另外两个抽象,它们是广播变量和累加器。 结果表明,由于其内部设计,Spark的运行速度比Hadoop快10倍。
翻译自: https://www.javacodegeeks.com/2015/05/spark-and-cluster-computing.html
spark集群计算本地数据















 386
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









