





postgres json
莎拉·梅(Sarah Mei)的文章“ 为什么不应该使用MongoDB ”讨论了在关系数据库要好得多的情况下尝试使用NoSQL数据库时会遇到的问题。 这样的一个例子是,当被认为位于筒仓中的数据需要跨越边界时(关系数据库最擅长的是什么)。 另一个示例是,当您将用户名存储在不同的位置以便于访问时,但是当用户更新其名称时,您将不得不查找所有这些位置以确保其信息是最新的。
我在制作网站方面的经验符合这样的观点:除非您的数据对象彼此之间处于完全的孤岛中(并且您确定在可预见的将来它们将以这种方式存在),否则使用关系型可能会更好像Postgres这样的数据库。
直到最近,您还必须在对数据进行建模时预先做出困难的决定: 文档还是关系数据库 ? 是的,您可以使用两个单独的数据库,并使用每种工具的最佳功能。 但是,您将增加应用程序以及开发和服务器环境的复杂性。
Postgres中的JSON支持
Postgres已经支持JSON已有一段时间了,但是说实话,由于缺少索引和键提取器方法,它的功能并不是那么好。 随着9.2版的发布,Postgres添加了本机JSON支持。 您最终可以将Postgres用作“ NoSQL”数据库。 在9.3版中,Postgres通过添加其他构造函数和提取器方法进行了改进。 9.4增加了将JSON存储为“二进制JSON”( 或JSONB )的功能,该功能去除了无关紧要的空格(没什么大不了),在插入数据时增加了一点点开销,但是在查询数据时提供了巨大的好处: 索引 。
随着版本9.4的发布,JSON支持尝试提出以下问题:“我使用文档还是关系数据库?” 不必要。 为什么没有两者?
我不会争辩说Postgres可以处理JSON以及MongoDB。 毕竟,MongoDB专门用作JSON文档存储,并具有一些非常好的功能,例如聚合管道 。 但事实是,Postgres现在可以很好地处理JSON。
为什么我什至要在我的数据库中使用JSON数据?
我仍然相信,大多数数据都是使用关系数据库建模的。 这样做的原因是因为网站数据趋向于相关。 用户进行购买并留下评论,电影中的演员可以在各种电影中扮演角色,等等。但是,在某些用例中,将JSON文档合并到模型中很有意义。 例如,当您需要:
- 避免对孤立或孤立的数据进行复杂的联接。 想想诸如Trello之类的东西,他们可以在其中将有关单张卡片的所有信息(评论,任务等)与卡片本身保持在一起。 对数据进行非规范化后 ,就可以通过一次查询来获取卡及其数据。
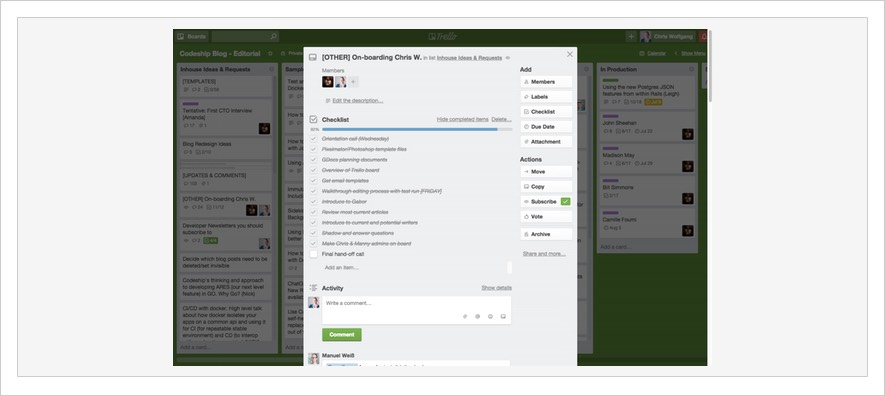
- 维护来自外部服务的数据,使其具有与到达您时相同的结构和格式(如JSON)。 最终在数据库中提供的正是API所提供的。 以Stripe的充电响应对象为例。 它是嵌套的,具有数组,依此类推。 您可以尝试按原样存储(并仍然针对它进行查询),而不用试图在五个或更多表之间标准化此数据。
- 通过JSON API返回数据之前,请避免转换数据。 查看来自FDA药品不良事件的令人讨厌的JSON响应 。 它是深层嵌套的,具有多个数组-在每个请求上实时构建此数据将对系统造成极大的负担。
如何在Postgres中使用JSONB
现在,我们已经了解了在Postgres中存储JSON数据的一些好处和用例,让我们看看它是如何实际完成的。
定义列
JSONB列与现在的任何其他数据类型一样。 这是一个创建cards表的示例,该表将其数据存储在称为“ data”的JSONB列中。
CREATE TABLE cards (
id integer NOT NULL,
board_id integer NOT NULL,
data jsonb
);插入JSON数据
要将JSON数据插入数据库,我们将整个JSON值作为字符串传递。
INSERT INTO cards VALUES (1, 1, '{"name": "Paint house", "tags": ["Improvements", "Office"], "finished": true}');
INSERT INTO cards VALUES (2, 1, '{"name": "Wash dishes", "tags": ["Clean", "Kitchen"], "finished": false}');
INSERT INTO cards VALUES (3, 1, '{"name": "Cook lunch", "tags": ["Cook", "Kitchen", "Tacos"], "ingredients": ["Tortillas", "Guacamole"], "finished": false}');
INSERT INTO cards VALUES (4, 1, '{"name": "Vacuum", "tags": ["Clean", "Bedroom", "Office"], "finished": false}');
INSERT INTO cards VALUES (5, 1, '{"name": "Hang paintings", "tags": ["Improvements", "Office"], "finished": false}');查询数据
您无法访问的数据毫无用处。 接下来,我们将研究如何查询我们先前插入到数据库中的内容。
SELECT data->>'name' AS name FROM cardsname
----------------
Paint house
Wash dishes
Cook lunch
Vacuum
Hang paintings
(5 rows)筛选结果
根据列过滤查询是很常见的,使用JSONB列,我们实际上可以进入JSON文档并根据其具有的不同属性过滤结果。 在下面的示例中,我们的“数据”列具有一个称为“完成”的属性,并且我们只需要finished为true的结果。
SELECT * FROM cards WHERE data->>'finished' = 'true';id | board_id | data
----+----------+--------------------------------------------------
1 | 1 | {"name": "Paint house", "tags": ["Improvements", "Office"], "finished": true}
(1 row)检查列是否存在
在这里,我们将找到记录的计数,其中data列包含名为“ ingredients”的属性。
SELECT count(*) FROM cards WHERE data ? 'ingredients';count
-------
1
(1 row)扩展数据
如果您使用关系数据库已有一段时间,那么您将非常熟悉聚合方法:count,avg,sum,min,max等。现在我们正在处理JSON数据,即数据库中的一条记录可能包含一个数组。 因此,我们现在可以扩大结果,而不是将结果缩小为一个汇总。
SELECT
jsonb_array_elements_text(data->'tags') as tag
FROM cards
WHERE id = 1;tag
--------------
Improvements
Office
(2 rows)关于以上示例,我想指出三点:
- 即使我们从数据库中查询了单行,也返回了两行。 这等于该行包含的标签数。
- 我使用了jsonb形式的方法,而不是json形式。 使用与您定义列的方式匹配的方式。
- 我像以前一样使用->而不是->>访问标签字段。 ->将以JSON对象的形式返回该属性,而->>将以整数或文本(该属性的解析形式)返回该属性。
JSONB的真正好处:索引
我们希望我们的应用程序更快。 如果没有索引,数据库将被迫在记录之间进行记录( 表扫描 ),以检查条件是否为真。 JSON数据没有什么不同。 实际上,由于Postgres也必须介入每个JSON文档,因此最有可能恶化。
我已经将测试数据从5条记录增加到10,000条。 这样,我们就可以开始在Postgres中处理JSON数据时看到一些性能影响,以及如何解决它们。
SELECT count(*) FROM cards WHERE data->>'finished' = 'true';count
-------
4937
(1 row)Aggregate (cost=335.12..335.13 rows=1 width=0) (actual time=4.421..4.421 rows=1 loops=1) -> Seq Scan on cards (cost=0.00..335.00 rows=50 width=0) (actual time=0.016..3.961 rows=4938 loops=1)
Filter: ((data ->> 'finished'::text) = 'true'::text)
Rows Removed by Filter: 5062
Planning time: 0.071 ms
Execution time: 4.465 ms现在,查询的速度并不是5ms那么慢,但是让我们看看是否可以改进它。
CREATE INDEX idxfinished ON cards ((data->>'finished'));如果我们运行相同的查询,但现在有了索引,则最终将时间缩短一半。
count
-------
4937
(1 row)Aggregate (cost=118.97..118.98 rows=1 width=0) (actual time=2.122..2.122 rows=1 loops=1) -> Bitmap Heap Scan on cards (cost=4.68..118.84 rows=50 width=0) (actual time=0.711..1.664 rows=4938 loops=1)
Recheck Cond: ((data ->> 'finished'::text) = 'true'::text)
Heap Blocks: exact=185
-> Bitmap Index Scan on idxfinished (cost=0.00..4.66 rows=50 width=0) (actual time=0.671..0.671 rows=4938 loops=1)
Index Cond: ((data ->> 'finished'::text) = 'true'::text)
Planning time: 0.084 ms
Execution time: 2.199 ms现在,我们的查询利用了我们创建的idxfinished索引的优势,查询时间大约减少了一半。
更复杂的索引
关于Postgres中JSON支持的很酷的事情之一就是您可以查询数组是否包含某个值。
SELECT count(*) FROM cards
WHERE
data->'tags' ? 'Clean'
AND data->'tags' ? 'Kitchen';count
-------
1537
(1 row)Aggregate (cost=385.00..385.01 rows=1 width=0) (actual time=6.673..6.673 rows=1 loops=1) -> Seq Scan on cards (cost=0.00..385.00 rows=1 width=0) (actual time=0.021..6.500 rows=1537 loops=1)
Filter: (((data -> 'tags'::text) ? 'Clean'::text) AND ((data -> 'tags'::text) ? 'Kitchen'::text))
Rows Removed by Filter: 8463
Planning time: 0.063 ms
Execution time: 6.710 ms
(6 rows)
Time: 7.314 ms从Postgres 9.4开始,GIN(通用反向索引)索引与JSONB数据类型一起出现。 使用GIN索引,我们可以使用JSON运算符@>,?,?&和?|快速查询数据。 有关运算符的详细信息,您可以访问Postgres文档 。
CREATE INDEX idxgintags ON cards USING gin ((data->'tags'));count
-------
1537
(1 row)Aggregate (cost=20.03..20.04 rows=1 width=0) (actual time=2.665..2.666 rows=1 loops=1) -> Bitmap Heap Scan on cards (cost=16.01..20.03 rows=1 width=0) (actual time=0.788..2.485 rows=1537 loops=1)
Recheck Cond: (((data -> 'tags'::text) ? 'Clean'::text) AND ((data -> 'tags'::text) ? 'Kitchen'::text))
Heap Blocks: exact=185
-> Bitmap Index Scan on idxgintags (cost=0.00..16.01 rows=1 width=0) (actual time=0.750..0.750 rows=1537 loops=1)
Index Cond: (((data -> 'tags'::text) ? 'Clean'::text) AND ((data -> 'tags'::text) ? 'Kitchen'::text))
Planning time: 0.088 ms
Execution time: 2.706 ms
(8 rows)
Time: 3.248 ms我们再次看到速度加倍。 如果我们的数据集大于10,000个记录,这将更加明显。 说明分析输出还向我们展示了它如何使用idxgintags索引。
最后,我们可以在整个数据字段上添加一个GIN索引,这将使我们在查询数据方面更具灵活性。
CREATE INDEX idxgindata ON cards USING gin (data);
SELECT count(*) FROM cards
WHERE
data @> '{"tags": ["Clean", "Kitchen"]}';count
-------
1537
(1 row)
Time: 2.837 ms如何在Rails中做到这一点?
让我们探讨一下如何在Rails中使用JSONB列创建表,以及如何查询这些JSONB列并更新数据。 有关更多信息,您可以参考关于此主题的Rails文档 。
定义JSONB列
首先,我们需要创建一个迁移,该迁移将创建一个表,该表具有指定为JSONB的列。
create_table :cards do |t|
t.integer :board_id, null: false
t.jsonb :data
end从Rails中查询JSON数据
让我们定义一个范围,以帮助我们找到“成品”卡。 应当注意,即使完成的列是JSON true值,在查询时我们也需要使用String true。 如果我们查看Rails中的完成列,我们将看到一个TrueClass值,并且在psql中查看数据时它也是一个JSON true值,但是尽管如此,仍需要使用String来查询它。
card.data["finished"].class
# TrueClass这是在Card类中添加:find范围的代码。 我们将无法使用惯用的常规where子句语法,但必须依赖于Postgres特定的语法。 应该注意的是,完成的列也需要用字符串包装,这就是在Postgres中引用JSON列的方式。
class Card < ActiveRecord::Base
scope :finished, -> {
where("cards.data->>'finished' = :true", true: "true")
}
endirb(main):001:0> Card.finished.count
(2.8ms) SELECT COUNT(*) FROM "cards" WHERE (cards.data->>'finished' = 'true')
=> 4937在Rails中处理JSON数据
定义为JSON或JSONB的任何列都将在Ruby中表示为Hash。
irb(main):001:0> card = Card.first
Card Load (0.9ms) SELECT "cards".* FROM "cards" ORDER BY "cards"."id" ASC LIMIT 1
=> #<Card id: 1, board_id: 1, data: {"name"=>"Organize Kitchen", "tags"=>["Fast", "Organize", "Carpet", "Cook", "Kitchen"], "finished"=>false}>
irb(main):002:0> card.data
=> {"name"=>"Organize Kitchen", "tags"=>["Fast", "Organize", "Carpet", "Cook", "Kitchen"], "finished"=>false}
irb(main):003:0> card.data.class
=> Hash在Rails中更新JSON数据
更新我们的JSON数据非常容易。 只需更改Hash值,然后在模型中调用save即可。 要将“完成”字段更新为true,我们将运行以下命令:
irb(main):004:0> card.data["finished"] = true
=> true
irb(main):005:0> card.save
(0.2ms) BEGIN
SQL (0.9ms) UPDATE "cards" SET "data" = $1 WHERE "cards"."id" = $2 [["data", "{\"name\":\"Organize Kitchen\",\"tags\":[\"Fast\",\"Organize\",\"Carpet\",\"Cook\",\"Kitchen\"],\"finished\":true}"], ["id", 1]]
(6.6ms) COMMIT
=> true您会注意到,Rails和Postgres都不能仅更新JSON数据中的单个“完成”值。 它实际上用整个新值替换了整个旧值。
结论
我们已经看到,Postgres现在包含一些非常强大的JSON构造。 将关系数据库的功能(简单的内部联接是一件很漂亮的事情,不是吗?)与JSONB数据类型的灵活性混合在一起,可以带来很多好处,而不必拥有两个独立的数据库。
您还可以避免文档数据库中有时会出现的妥协(如果您曾经不得不在五个不同的地方更新对用户名的引用,那么您会知道我在说什么。)尝试一下! 谁说你不能教老狗一些新花样?
翻译自: https://www.javacodegeeks.com/2015/07/unleash-the-power-of-storing-json-in-postgres.html
postgres json















 2905
2905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









