





optaplanner
生产中跟踪/调试日志记录的成本是多少? 记录到文件的性能成本是多少? 在这些基准测试中,我比较了日志级别( error , warn , info , debug , trace )和日志附加程序(控制台附加程序,文件附加程序)在几种实际的OptaPlanner用例上对性能的影响。
基准方法
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="appender" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d [%t] %-5p %m%n</pattern>
</encoder>
</appender>
<logger name="org.optaplanner" level="info"/>
<root level="warn">
<appender-ref ref="appender"/>
</root>
</configuration>结果如下:
2015-02-23 08:07:35,310 [main] INFO Solving started: time spent (18), best score (uninitialized/0hard/0soft), environment mode (REPRODUCIBLE), random (JDK with seed 0).
2015-02-23 08:07:35,363 [main] INFO Construction Heuristic phase (0) ended: step total (6), time spent (71), best score (0hard/-5460soft).
2015-02-23 08:07:35,641 [main] INFO Local Search phase (1) ended: step total (1), time spent (349), best score (0hard/-5460soft).
2015-02-23 08:07:35,652 [main] INFO Solving ended: time spent (360), best score (0hard/-5460soft), average calculate count per second (905), environment mode (REPRODUCIBLE).- VM参数:
-Xmx1536M -server
软体:Linux 3.2.0-59-generic-pae
硬件:Intel® Xeon® CPU W3550 @ 3.07GHz - 每次运行都能使用OptaPlanner解决13个计划问题。 每个计划问题要运行5分钟。 它以30秒的JVM预热开始,该预热将被丢弃。
- 解决计划问题不涉及任何IO (启动期间要加载输入的几毫秒除外)。 一个CPU完全饱和。 它会不断创建许多短命的对象,然后GC会收集它们。
- 基准衡量每毫秒可以计算的分数数量。 越高越好。 为提议的规划解决方案计算分数并非易事:涉及许多计算,包括检查每个实体与每个其他实体之间的冲突。
要在本地重现这些基准, 请从源代码构建optaplanner并运行主类GeneralOptaPlannerBenchmarkApp 。
日志记录级别:
我使用不同的OptaPlanner日志记录级别多次运行了相同的基准测试集:
<logger name="org.optaplanner" level="error|warn|info|debug|trace"/>所有其他库(包括Drools )都设置为警告日志记录。 每个级别的OptaPlanner的日志记录详细程度差异很大:
-
error和warn: 0行 -
info:每个基准4行,因此每分钟少于1行 。 -
debug:每行1行,因此Tabu Search大约为每秒1行, 而后期接受则更多 -
trace线:每行1行,因此每秒1k至120k
这些是原始的基准数字,以每秒的平均分数计算计数来衡量(越高越好):
| 记录级别 | 云200c | 云800c | 机器B1 | 机器B10 | 课程c7 | 课程c8 | 考试s2 | 考试S3 | 护士m1 | 护士MH1 | 体育NL14 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 错误 | 66065 | 61866 | 119230 | 32759 | 6282 | 8370 | 10330 | 7121 | 4001 | 3718 | 1248 |
| 警告 | 66943 | 62191 | 122678 | 32688 | 6297 | 8303 | 10517 | 7182 | 3942 | 3660 | 1278 |
| 信息 | 67393 | 63192 | 123734 | 32461 | 6188 | 8299 | 10330 | 7108 | 3944 | 3654 | 1252 |
| 除错 | 60254 | 55938 | 118917 | 32735 | 6054 | 8062 | 10310 | 7104 | 3904 | 3586 | 1244 |
| 跟踪 | 25159 | 25214 | 40346 | 20629 | 5585 | 7347 | 9229 | 6642 | 3360 | 3138 | 1156 |
| 数据集规模 | 12万 | 1920k | 50万 | 250000k | 21.7万 | 14.5万 | 1705千 | 1613k | 18k | 12k | 4k |
| 算法 | 延迟验收 | 延迟验收 | 禁忌搜索 | 禁忌搜索 | 延迟验收 | 延迟验收 | 禁忌搜索 | 禁忌搜索 | 禁忌搜索 | 禁忌搜索 | 禁忌搜索 |
我将忽略错误,警告和信息日志记录之间的区别:区别最多为4%,运行可100%再现,并且在基准测试期间我没有使用计算机,因此我认为可以归咎于区别JIT热点编译或CPU运气不好。
启用“调试”或“跟踪”日志记录会给我们带来哪些性能损失(与“信息”日志记录相比)?
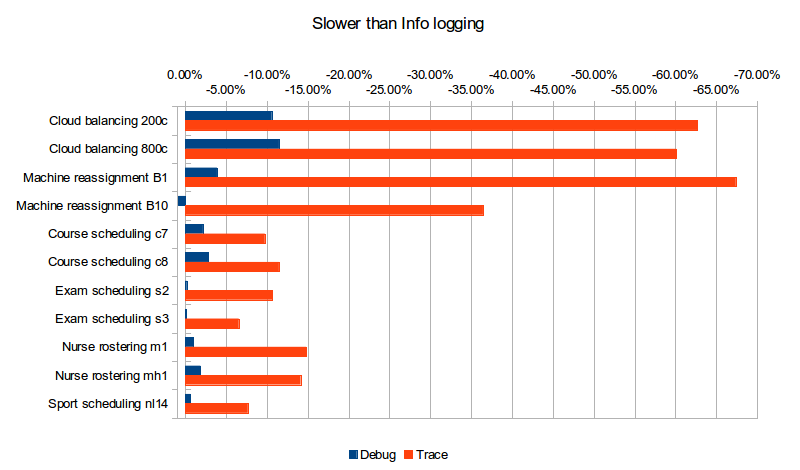
| 记录级别 | 云200c | 云800c | 机器B1 | 机器B10 | 课程c7 | 课程c8 | 考试s2 | 考试S3 | 护士m1 | 护士MH1 | 体育NL14 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 除错 | -10.59% | -11.48% | -3.89% | 0.84% | -2.17% | -2.86% | -0.19% | -0.06% | -1.01% | -1.86% | -0.64% |
| 跟踪 | -62.67% | -60.10% | -67.39% | -36.45% | -9.74% | -11.47% | -10.66% | -6.56% | -14.81% | -14.12% | -7.67% |
| 数据集规模 | 12万 | 1920k | 50万 | 250000k | 21.7万 | 14.5万 | 1705千 | 1613k | 18k | 12k | 4k |
| 算法 | 延迟验收 | 延迟验收 | 禁忌搜索 | 禁忌搜索 | 延迟验收 | 延迟验收 | 禁忌搜索 | 禁忌搜索 | 禁忌搜索 | 禁忌搜索 | 禁忌搜索 |
跟踪日志记录的速度降低了近4倍! 调试日志记录的影响要小得多,但在许多情况下仍然很明显。 使用后验收(云平衡和课程安排)的用例(因此进行更多的调试日志记录)似乎具有更高的性能损失(尽管在旁观者的眼中)。
但是请稍等! 这些基准使用控制台附加程序。 如果他们在生产中使用文件追加器怎么办?
记录附加程序:附加到控制台或文件
在生产服务器上,附加到控制台通常意味着将日志信息传递到/dev/null时会丢失。 同样在开发过程中,IDE的控制台缓冲区可能会溢出,从而导致日志行丢失。 避免这些问题的一种方法是配置文件附加器。 为了节省磁盘空间,我使用了滚动文件附加器,该附加器将旧的日志文件压缩为5MB的zip文件:
<appender name="appender" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>local/log/optaplanner.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.FixedWindowRollingPolicy">
<fileNamePattern>local/log/optaplanner.%i.log.zip</fileNamePattern>
<minIndex>1</minIndex>
<maxIndex>3</maxIndex>
</rollingPolicy>
<triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy">
<maxFileSize>5MB</maxFileSize>
</triggeringPolicy>
<encoder>
<pattern>%d [%t] %-5p %m%n</pattern>
</encoder>
</appender>这些是原始基准数字,以每秒的平均分数计算计数再次测量(越高越好):
| 记录附加程序和级别 | 云200c | 云800c | 机器B1 | 机器B10 | 课程c7 | 课程c8 | 考试s2 | 考试S3 | 护士m1 | 护士MH1 | 体育NL14 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 控制台信息 | 67393 | 63192 | 123734 | 32461 | 6188 | 8299 | 10330 | 7108 | 3944 | 3654 | 1252 |
| 文件信息 | 66497 | 63065 | 123758 | 33195 | 6302 | 8338 | 10467 | 7238 | 4022 | 3706 | 1256 |
| 控制台调试 | 60254 | 55938 | 118917 | 32735 | 6054 | 8062 | 10310 | 7104 | 3904 | 3586 | 1244 |
| 文件调试 | 55248 | 52261 | 122144 | 31220 | 6223 | 8241 | 10482 | 7118 | 3945 | 3589 | 1238 |
| 控制台跟踪 | 25159 | 25214 | 40346 | 20629 | 5585 | 7347 | 9229 | 6642 | 3360 | 3138 | 1156 |
| 档案追踪 | 10162 | 10708 | 12528 | 9555 | 4416 | 5167 | 6764 | 5532 | 2789 | 2678 | 1101 |
文件附加程序在性能上给我们带来了什么损失(相对于控制台附加程序)?
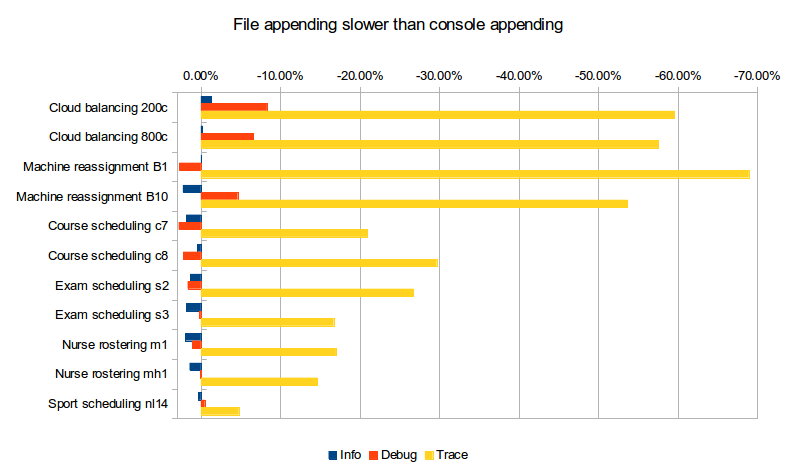
| 记录级别 | 云200c | 云800c | 机器B1 | 机器B10 | 课程c7 | 课程c8 | 考试s2 | 考试S3 | 护士m1 | 护士MH1 | 体育NL14 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 信息 | -1.33% | -0.20% | 0.02% | 2.26% | 1.84% | 0.47% | 1.33% | 1.83% | 1.98% | 1.42% | 0.32% |
| 除错 | -8.31% | -6.57% | 2.71% | -4.63% | 2.79% | 2.22% | 1.67% | 0.20% | 1.05% | 0.08% | -0.48% |
| 跟踪 | -59.61% | -57.53% | -68.95% | -53.68% | -20.93% | -29.67% | -26.71% | -16.71% | -16.99% | -14.66% | -4.76% |
对于信息记录,这并不重要。 对于调试日志记录,在少数情况下,速度会明显下降。 跟踪日志记录的速度最多慢了4倍! 而且它与我们以前的观察结果相吻合:在最坏的情况下(机器重新分配B1),跟踪记录到文件的速度比信息记录到控制台的速度慢90%。
结论
像所有诊断信息一样,日志记录会降低性能。 好的库会仔细选择每个语句的日志记录级别,以平衡诊断需求,详细程度和性能影响。
这是我对OptaPlanner用户的建议:在开发中,默认情况下,将debug (或trace )日志记录与控制台附加程序一起使用,以便您了解发生了什么。 在生产环境中,默认情况下,将warn (或info )记录与文件附加程序一起使用,因此您可以保留重要信息。
翻译自: https://www.javacodegeeks.com/2015/04/optaplanner-how-fast-is-logging.html
optaplanner















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









