





 本文介绍了在数仓建模主题建模过程中如何确定最佳主题数量。通过使用Java库Mallet进行主题建模,作者通过尝试不同数量的主题和停用词设置,观察文档在主题上的分布,以寻找均匀分布。结果显示,较少的主题数量可能导致更均匀的分布,但也需要进一步研究以优化停用词的选择。代码和结果可在GitHub上找到。
本文介绍了在数仓建模主题建模过程中如何确定最佳主题数量。通过使用Java库Mallet进行主题建模,作者通过尝试不同数量的主题和停用词设置,观察文档在主题上的分布,以寻找均匀分布。结果显示,较少的主题数量可能导致更均匀的分布,但也需要进一步研究以优化停用词的选择。代码和结果可在GitHub上找到。
数仓建模主题划分
在我对主题建模的持续探索中,我遇到了The Programming Historian博客,以及一篇文章,展示了如何使用Java库槌 从语料库中获取主题 。
博客上的说明使安装和运行变得非常容易,但是与我使用的其他库一样,您必须指定文集包含多少个主题。 我不确定要选择什么值,但是作者提出以下建议:
您如何知道要搜索的主题数? 话题自然吗? 我们发现,必须运行带有不同数量主题的火车主题,以查看合成文件如何分解。 如果我们最终将大部分原始文本都包含在非常有限的主题中,那么我们认为这是我们需要增加主题数量的信号。 设置太粗糙了。
搜索的方法有很多,包括使用MALLETs hlda命令,但是对于本教程的读者来说,循环进行多次迭代可能会更快一些(但更多信息请参见Griffiths,TL,&Steyvers,M.( 2004)。 寻找科学主题 。国家科学院院刊,101,5228-5235)。
由于我还没有时间深入研究论文或探讨如何在短槌中使用适当的选项,所以我想我会对停用词和主题数量进行一些改动,看看结果如何。
据我了解,其想法是尝试使主题->文档均匀分布,即我们不希望所有文档都具有相同的主题,否则我们进行的任何主题相似度计算都不会那么有趣。
我试过用10、15、20和30个主题运行槌,还改变了所用的停用词。 我有一个版本只剥离了主要字符和“旁白”一词,而另一个版本中,我按出现次数和出现次数少于10次的词去掉了前20%的单词。
这样做的原因是,它应该比TF / IDF更好地识别情节中的有趣短语,而不仅仅是在整个语料库中选择最受欢迎的单词。
我从命令行使用了槌,并将其分为两个部分运行。
- 产生模型
- 根据超参数计算主题和文档的分配
我写了一个脚本来帮助我:
#!/bin/sh
train_model() {
./mallet-2.0.7/bin/mallet import-dir \
--input mallet-2.0.7/sample-data/himym \
--output ${2} \
--keep-sequence \
--remove-stopwords \
--extra-stopwords ${1}
}
extract_topics() {
./mallet-2.0.7/bin/mallet train-topics \
--input ${2} --num-topics ${1} \
--optimize-interval 20 \
--output-state himym-topic-state.gz \
--output-topic-keys output/himym_${1}_${3}_keys.txt \
--output-doc-topics output/himym_${1}_${3}_composition.txt
}
train_model "stop_words.txt" "output/himym.mallet"
train_model "main-words-stop.txt" "output/himym.main.words.stop.mallet"
extract_topics 10 "output/himym.mallet" "all.stop.words"
extract_topics 15 "output/himym.mallet" "all.stop.words"
extract_topics 20 "output/himym.mallet" "all.stop.words"
extract_topics 30 "output/himym.mallet" "all.stop.words"
extract_topics 10 "output/himym.main.words.stop.mallet" "main.stop.words"
extract_topics 15 "output/himym.main.words.stop.mallet" "main.stop.words"
extract_topics 20 "output/himym.main.words.stop.mallet" "main.stop.words"
extract_topics 30 "output/himym.main.words.stop.mallet" "main.stop.words"如您所见,此脚本首先从“ mallet-2.0.7 / sample-data / himym”中的文本文件生成一堆模型-HIMYM的每个情节都有一个文件。 然后,我们使用该模型生成大小不同的主题模型。
输出是两个文件。 一个包含一个主题列表,另一个描述每个文档中单词的百分比来自每个主题。
$ cat output/himym_10_all.stop.words_keys.txt
0 0.08929 back brad natalie loretta monkey show call classroom mitch put brunch betty give shelly tyler interview cigarette mc laren
1 0.05256 zoey jerry arthur back randy arcadian gael simon blauman blitz call boats becky appartment amy gary made steve boat
2 0.06338 back claudia trudy doug int abby call carl stuart voix rachel stacy jenkins cindy vo katie waitress holly front
3 0.06792 tony wendy royce back jersey jed waitress bluntly lucy made subtitle film curt mosley put laura baggage officer bell
4 0.21609 back give patrice put find show made bilson nick call sam shannon appartment fire robots top basketball wrestlers jinx
5 0.07385 blah bob back thanksgiving ericksen maggie judy pj valentine amanda made call mickey marcus give put dishes juice int
6 0.04638 druthers karen back jen punchy jeanette lewis show jim give pr dah made cougar call jessica sparkles find glitter
7 0.05751 nora mike pete scooter back magazine tiffany cootes garrison kevin halloween henrietta pumpkin slutty made call bottles gruber give
8 0.07321 ranjit back sandy mary burger call find mall moby heather give goat truck made put duck found stangel penelope
9 0.31692 back give call made find put move found quinn part ten original side ellen chicago italy locket mine show$ head -n 10 output/himym_10_all.stop.words_composition.txt
#doc name topic proportion ...
0 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/1.txt 0 0.70961794636687 9 0.1294699168584466 8 0.07950442338871108 2 0.07192178481473664 4 0.008360809510263838 5 2.7862560133367015E-4 3 2.562409242784946E-4 7 2.1697378721335337E-4 1 1.982849604752168E-4 6 1.749937876710496E-4
1 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/10.txt 2 0.9811551470820473 9 0.016716882136209997 4 6.794128563082893E-4 0 2.807350575301132E-4 5 2.3219634098530471E-4 8 2.3018997315244256E-4 3 2.1354177341696056E-4 7 1.8081798384467614E-4 1 1.6524340216541808E-4 6 1.4583339433951297E-4
2 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/100.txt 2 0.724061485807234 4 0.13624729774423758 0 0.13546964196228636 9 0.0019436342339785994 5 4.5291919356563914E-4 8 4.490055982996677E-4 3 4.1653183421485213E-4 7 3.5270123154213927E-4 1 3.2232165301666123E-4 6 2.8446074162457316E-4
3 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/101.txt 2 0.7815231689893246 0 0.14798271520316794 9 0.023582384458063092 8 0.022251052243582908 1 0.022138209217973336 4 0.0011804626661380394 5 4.0343527385745457E-4 3 3.7102343418895774E-4 7 3.1416667687862693E-4 6 2.533818368250992E-
4 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/102.txt 6 0.6448245189567259 4 0.18612146979166502 3 0.16624873439661025 9 0.0012233726722317548 0 3.4467218590717303E-4 5 2.850788252495599E-4 8 2.8261550915084904E-4 2 2.446611421432842E-4 7 2.2199909869250053E-4 1 2.028774216237081E-
5 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/103.txt 8 0.7531586740033047 5 0.17839539108961253 0 0.06512376460651902 9 0.001282794040111701 4 8.746645156304241E-4 3 2.749100345664577E-4 2 2.5654476523149865E-4 7 2.327819863700214E-4 1 2.1273153572848481E-4 6 1.8774342292520802E-4
6 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/104.txt 7 0.9489502365148181 8 0.030091466847852504 4 0.017936457663121977 9 0.0013482824985091328 0 3.7986419553884905E-4 5 3.141861834124008E-4 3 2.889445824352445E-4 2 2.6964174000656E-4 1 2.2359178288566958E-4 6 1.9732799141958482E-4
7 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/105.txt 8 0.7339694064061175 7 0.1237041841318045 9 0.11889696041555338 0 0.02005288536233353 4 0.0014026751618923005 5 4.793786828705149E-4 3 4.408655780020889E-4 2 4.1141370625324785E-4 1 3.411516484151411E-4 6 3.0107890675777946E-4
8 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/106.txt 5 0.37064909999661005 9 0.3613559917055785 0 0.14857567731040344 6 0.09545466082502917 4 0.022300625744661403 8 3.8725629469313333E-4 3 3.592484711785775E-4 2 3.3524900189121E-4 7 3.041961449432886E-4 1 2.779945050112539E-4输出本身很难理解,因此我使用了pandas进行了一些后期处理,然后通过matplotlib运行了该结果,以查看具有不同停用词的不同主题大小的文档的分布。 您可以在此处查看脚本 。
我得到了以下图表:
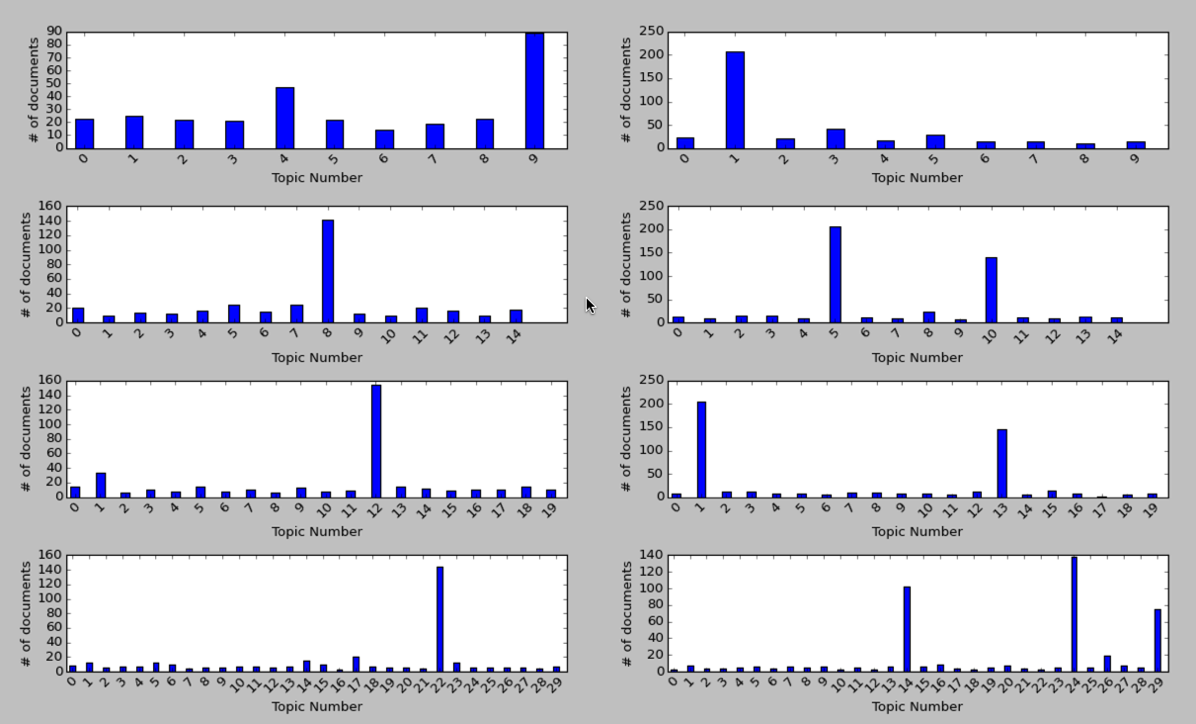
在左侧,我们使用了更多停用词,而在右侧,主要是停用词。 对于大多数变体,大多数文档都属于一个或两个主题,但是有趣的是,最统一的分布似乎是当我们只有几个主题时。
这些是左侧最受欢迎的主题的关键词:
15个主题
8 0.50732 back give call made put find found part move show side ten mine top abby front fire full fianc20题
12 0.61545 back give call made put find show found part move side mine top front ten full cry fire fianc30个主题
22 0.713 back call give made put find show part found side move front ten full top mine fire cry bottom乍一看,它们都包含或多或少相同的词,这些词看起来很普通,所以令我惊讶的是它们没有被排除。
在右侧,我们没有删除很多单词,因此我们希望英语中的常见单词占主导。 让我们看看他们是否这样做:
10个主题
1 3.79451 don yeah ll hey ve back time guys good gonna love god night wait uh thing guy great make15个主题
5 2.81543 good time love ll great man guy ve night make girl day back wait god life yeah years thing
10 1.52295 don yeah hey gonna uh guys didn back ve ll um kids give wow doesn thing totally god fine20题
1 3.06732 good time love wait great man make day back ve god life years thought big give apartment people work
13 1.68795 don yeah hey gonna ll uh guys night didn back ve girl um kids wow guy kind thing baby 30个主题
14 1.42509 don yeah hey gonna uh guys didn back ve um thing ll kids wow time doesn totally kind wasn
24 2.19053 guy love man girl wait god ll back great yeah day call night people guys years home room phone
29 1.84685 good make ve ll stop time made nice put feel love friends big long talk baby thought things happy再次,我们在每次运行中都有相似的词,并且正如预期的那样,它们都是非常通用的词。
我从这项探索中脱颖而出的是,我也应该改变停用词的百分比,看看是否能改善分布。
尽管我需要弄清楚为什么每组中只有一个离群值,但是像我们使用左侧图一样去掉非常常见的词似乎很有意义。
作者建议,将大部分文章放在少数主题中意味着我们需要创建更多文章,因此我也将对此进行调查。
翻译自: https://www.javacodegeeks.com/2015/03/topic-modelling-working-out-the-optimal-number-of-topics.html
数仓建模主题划分















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









