





hadoop伪分布与全分布
图形引擎有两种常见的类型。 一种类型专注于在单台服务器上表示的链表上提供基于遍历的实时算法。 这种引擎通常称为图数据库 ,一些供应商包括Neo4j , OrientDB , DEX和InfiniteGraph 。 图引擎的另一种类型专注于使用以顶点为中心的消息传递,该消息以跨机器集群表示的图为单位进行批处理。 这种形式的图形引擎包括Hama , Golden Orb , Giraph和Pregel 。
这篇文章的目的是演示如何表达两个基本图形统计数据的计算-每个图形统计遍历和MapReduce算法。 为此目的探索的图形引擎是Neo4j和Hadoop 。 但是,就Hadoop而言,其结果不是通过特定的基于顶点为中心的基于BSP的图形处理程序包(例如Hama或Giraph),而是通过本机Hadoop(HDFS + MapReduce)提供。 而且,不是使用Java开发MapReduce算法,而是使用R编程语言 。 RHadoop是Revolution Analytics开发的小型开源程序包,它将R绑定到Hadoop,并允许使用本机R表示MapReduce算法。
两种图算法提供了计算度统计信息 : 顶点度和图度分布 。 两者都是相关的,实际上,第一个的结果可用作第二个的输入。 也就是说,图形入度分布是顶点入度的函数。 这两个基本统计数据一起为更量化图论和网络科学领域中开发的统计数据奠定了基础。
- 顶点度数 :顶点X有多少个传入边?
- 图的度数分布 :多少个顶点的X边数为X ?

这两种算法是在包含100,000个顶点和704,002条边的人工生成的图形上计算的。 子集显示在左侧。 用于生成图的算法称为优先附件 。 优先附着会产生具有“自然统计”的图,其度分布类似于真实世界的图/网络。 下面提供了相应的iGraph R代码。 一旦构造和简化(即,任意两个顶点之间不超过一个边且没有自环),就计算顶点和边。 接下来,迭代并显示前五个边缘。 第一条边显示为“顶点2连接到顶点0。” 最后,图形作为GraphML文件保存到磁盘。
~$ r
R version 2.13.1 (2011-07-08)
Copyright (C) 2011 The R Foundation for Statistical Computing
> g <- simplify(barabasi.game(100000, m=10))
> length(V(g))
[1] 100000
> length(E(g))
[1] 704002
> E(g)[1:5]
Edge sequence:
[1] 2 -> 0
[2] 2 -> 1
[3] 3 -> 0
[4] 4 -> 0
[5] 4 -> 1
> write.graph(g, '/tmp/barabasi.xml', format='graphml')使用Neo4j进行图统计
 当图的数量级为100亿个元素(顶点+边)时,单服务器图数据库就足以执行图分析。 附带说明一下,当这些分析/算法是“以自我为中心”的(即,遍历从单个顶点或一小组顶点发出)时,通常可以实时评估它们(例如,<1000 ms)。 为了计算这些度数统计,使用了Gremlin 。 Gremlin是TinkerPop开发的一种图形遍历语言,与Neo4j,OrientDB,DEX,InfiniteGraph和RDF引擎Stardog一起分发 。 下面的Gremlin代码将R中在上一节中创建的GraphML文件加载到Neo4j中。 然后,它对图形中的顶点和边进行计数。
当图的数量级为100亿个元素(顶点+边)时,单服务器图数据库就足以执行图分析。 附带说明一下,当这些分析/算法是“以自我为中心”的(即,遍历从单个顶点或一小组顶点发出)时,通常可以实时评估它们(例如,<1000 ms)。 为了计算这些度数统计,使用了Gremlin 。 Gremlin是TinkerPop开发的一种图形遍历语言,与Neo4j,OrientDB,DEX,InfiniteGraph和RDF引擎Stardog一起分发 。 下面的Gremlin代码将R中在上一节中创建的GraphML文件加载到Neo4j中。 然后,它对图形中的顶点和边进行计数。
~$ gremlin
\,,,/
(o o)
-----oOOo-(_)-oOOo-----
gremlin> g = new Neo4jGraph('/tmp/barabasi')
==>neo4jgraph[EmbeddedGraphDatabase [/tmp/barabasi]]
gremlin> g.loadGraphML('/tmp/barabasi.xml')
==>null
gremlin> g.V.count()
==>100000
gremlin> g.E.count()
==>704002下面提供了用于计算顶点度数的Gremlin代码。 第一行遍历所有顶点,并输出顶点及其入度。 第二行提供一个范围过滤器,以便仅显示前五个顶点及其入度计数。 请注意,澄清图说明了玩具图上的转换,而不是实验中使用的100,000个顶点图。
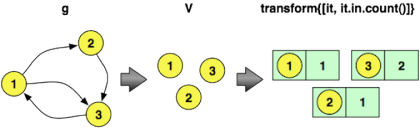
gremlin> g.V.transform{[it, it.in.count()]}
...
gremlin> g.V.transform{[it, it.in.count()]}[0..4]
==>[v[1], 99104]
==>[v[2], 26432]
==>[v[3], 20896]
==>[v[4], 5685]
==>[v[5], 2194] 接下来,要计算图形的度内分布,可以评估以下Gremlin遍历。 此表达式遍历图中的所有顶点,发出它们的度数,然后计算遇到特定度数的次数。 这些计数将保存到由groupCount维护的内部映射中。 最后的cap步骤产生内部groupCount映射。 为了仅显示前五个计数,将应用范围过滤器。 发出的第一行说:“有52,611个顶点没有任何传入边。” 第二行说:“有16,758个顶点具有一个传入边。”
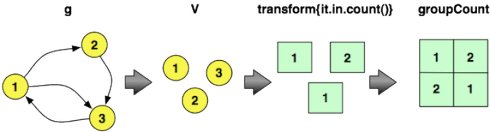
gremlin> g.V.transform{it.in.count()}.groupCount.cap
...
gremlin> g.V.transform{it.in.count()}.groupCount.cap.next()[0..4]
==>0=52611
==>1=16758
==>2=8216
==>3=4805
==>4=3191为了通过使用后者的前一个计算结果来计算两个统计量,可以执行以下遍历。 此表示形式与使用MapReduce计算顶点度和图形度分布的方式直接相关(在下一节中演示)。
gremlin> degreeV = [:]
gremlin> degreeG = [:]
gremlin> g.V.transform{[it, it.in.count()]}.sideEffect{degreeV[it[0]] = it[1]}.transform{it[1]}.groupCount(degreeG)
...
gremlin> degreeV[0..4]
==>v[1]=99104
==>v[2]=26432
==>v[3]=20896
==>v[4]=5685
==>v[5]=2194
gremlin> degreeG.sort{a,b -> b.value <=> a.value}[0..4]
==>0=52611
==>1=16758
==>2=8216
==>3=4805
==>4=3191使用Hadoop进行图统计
当图的数量级超过100+十亿个元素(顶点+边)时,单服务器图数据库将无法表示或处理该图。 需要多计算机图形引擎。 虽然本机Hadoop不是图形引擎,但是图形可以在其分布式HDFS文件系统中表示,并可以使用其分布式处理MapReduce框架进行处理。 先前生成的图被加载到R中,并对其顶点和边进行计数。 接下来,将图形表示为边缘列表。 边列表(用于单关系图)是成对的列表,其中每个对是有序的,表示边的尾顶点ID和头顶点ID。 边缘列表可以使用RHadoop推送到HDFS。 变量edge.list表示一个指向该HDFS文件的指针。
> g <- read.graph('/tmp/barabasi.xml', format='graphml')
> length(V(g))
[1] 100000
> length(E(g))
[1] 704002
> edge.list <- to.dfs(get.edgelist(g))
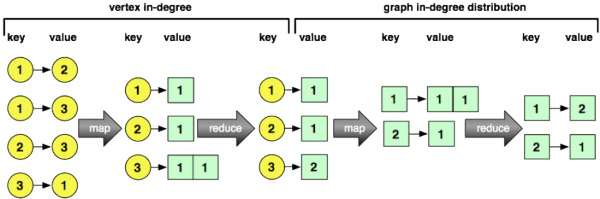
为了计算顶点的度数,在edge.list上评估MapReduce作业。 向地图函数提供了键/值对,其中键是边缘ID,值是边缘的尾部和头部顶点的ID(表示为列表)。 对于每个键/值输入,都会发送头顶点(即,传入的顶点)以及数字1。减少功能会被馈送键/值对,其中键是顶点,值是1的列表。 reduce作业的输出是顶点id和1s列表的长度(即,该顶点被视为边的传入/头部顶点的次数)。 该MapReduce作业的结果将保存到HDFS,而degree.V是指向该文件的指针。 下面代码块中的最终表达式从degree.V读取第一个键/值对-顶点10030的度数为5。
> degree.V <- mapreduce(edge.list,
map=function(k,v) keyval(v[2],1),
reduce=function(k,v) keyval(k,length(v)))
> from.dfs(degree.V)[[1]]
$key
[1] 10030
$val
[1] 5
attr(,"rmr.keyval")
[1] TRUE 为了计算图形的度数分布,需要对degree.V评估MapReduce作业。 映射函数会degree.V存储在degree.V的键/值结果。 该函数以数字1作为其值发出顶点的度数。 例如,如果顶点6的入度为100,则map函数将发射键/值[100,1]。 接下来,为reduce函数提供代表度数的键,这些键的值是该度数被视为1的列表的次数。 reduce函数的输出是键以及1s列表的长度(即遇到特定次数的次数的键)。 下面的最终代码片段从degree.g了第一个键/值对-遇到1354次。
> degree.g <- mapreduce(degree.V,
map=function(k,v) keyval(v,1),
reduce=function(k,v) keyval(k,length(v)))
> from.dfs(degree.g)[[1]]
$key
[1] 1354
$val
[1] 1
attr(,"rmr.keyval")
[1] TRUE总之,这两个计算可以组成一个MapReduce表达式。
> degree.g <- mapreduce(mapreduce(edge.list,
map=function(k,v) keyval(v[2],1),
reduce=function(k,v) keyval(k,length(v))),
map=function(k,v) keyval(v,1),
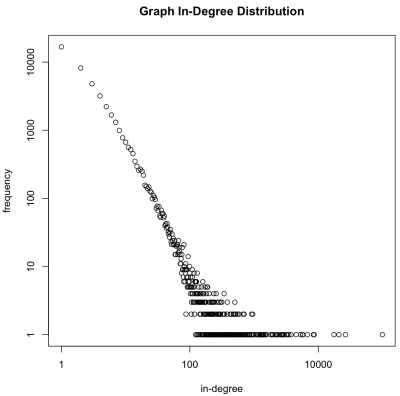
reduce=function(k,v) keyval(k,length(v))) 请注意,虽然图可以在100+十亿个元素的数量级上,但是度分布要小得多,通常可以放入内存中。 通常, edge.list > degree.V > degree.g 。 由于这个事实,可以将degree.g文件从HDFS中拉出,将其放置到主存储器中,然后绘制存储在其中的结果。 degree.g分布在对数/对数图上绘制。 令人怀疑的是,优先依附算法生成的图形具有自然的“无标度 ”统计数据-大多数顶点的度数较小,很少有大的度数。
> degree.g.memory <- from.dfs(degree.g)
> plot(keys(degree.g.memory), values(degree.g.memory), log='xy', main='Graph In-Degree Distribution', xlab='in-degree', ylab='frequency')
相关资料
- Cohen,J。,“ MapReduce世界中的图缠绕 ”,科学与工程计算,IEEE,11(4),第29-41页,2009年7月。
翻译自: https://www.javacodegeeks.com/2014/06/graph-degree-distributions-using-r-over-hadoop.html
hadoop伪分布与全分布















 2485
2485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









