





c#程序 数据库死锁
数据库不是队列。
尽管那里存在无处不在的排队技术(ActiveMQ,MSMQ,MSSQL Service Broker,Oracle Advanced Queuing),但仍有很多时候我们要求关系弟兄假装成队列。 这是一个愚蠢的故事,在整个过程中,我们将深入研究死锁,锁升级,执行计划和涵盖索引的一些有趣子图,噢,我的天! 希望我们会笑,我们会哭,最后得到坏人(原来我是坏人)。
这是一个多部分组成的系列描述整个事件的一部分之一 。 在这一部分中,我列出了问题,最初的症状以及用来找出问题所在的工具和命令。
这样就开始了……
我将为我们的讨论打下基础,向您介绍问题,并确定涉及我们悲剧的人物。 假设此系统将音乐CD组织到带标签的存储桶中。 CD一次只能位于一个存储桶中,并且存储桶以总计级别跟踪其中包含多少CD(例如,存储桶“大小”)。 您可以形象地看到一堆CD和两个存储桶:“好CD”和“坏CD”。 有时您会决定自己不喜欢存储桶的选择,并且想要将CD重新分发到新的存储桶中-也许要十年后才能发行:“ 1980年代音乐”,“ 1990年代音乐”,“所有其他(劣等)音乐” 。 以后,您可能会再次改变主意,并提出了一种组织CD等的新方法。我们将每个“组”存储桶称为“一代”。 因此,在第0代,您有2个存储区“好CD”和“坏CD”,在第1代,您有“ 1980s CD”,依此类推,依此类推。 当您将CD从上一代存储桶重新分配到下一代存储桶时,这一代总是随着时间的推移而增加。
最后,虽然我可能以某种存储方案来组织音乐收藏,但也许我的朋友杰里有自己的收藏和存储方案。 因此,可以将几代人的全部存储桶归为音乐收藏 。 收藏完全独立:我和Jerry不共享CD,也不共享存储桶。 我们恰好能够使用同一系统来管理我们的音乐收藏。
因此,我们有:
- CD-存储在存储桶中的东西,我们为每一代重新分发
- 存储桶-按代分组的组织单位,其中包含CD。 每个存储桶上都有一个便签,上面有存储桶中当前的CD数量。
- 生成-在特定时间点的一组存储桶。
- 收藏品-独立的CD和存储桶集
即使我们将CD从一个世代的存储桶中重新分配到下一个存储桶,一次CD也仅位于一个存储桶中。 可视化地将CD从“好CD”(第0代)移动到“ 1980年代音乐”(第1代)。
注意:我们的实际系统与CD和存储桶无关,我只是发现将系统映射到这种易于可视化的隐喻中比较容易。
在这个系统中,我们有数百万个CD,数千个存储桶以及许多CPU,它们将CD从新一代的存储箱中移动到下一代(并行但未分发)。 每个存储桶的大小在任何时间点都必须保持一致。
因此,假设数据库模型如下所示:
- 斗表
- bucketId (例如1,2,3,4) – 主键丛集
- CDS表
- cdId (例如1,2,3,4) – 主键集中
请注意,两个表都由它们的主键聚集–这意味着实际的记录数据本身存储在主索引的叶节点中。 即表本身是一个索引。 此外,可以通过“音乐收集”来查找存储桶而无需扫描(请参见collectionId上的二级非聚集索引),而可以通过bucketId来查找Cds而无需进行扫描(请参见Cds上的二级非聚集索引)。 bucketId)。
算法
因此,我编写了具有一些设计目标的重新分发过程:(1)它需要在线工作。 我可以在重新分发的同时将新的CD添加到当前的垃圾箱中。 (2)我总是可以找到CD,也就是说,我永远不会错误地报告某些CD丢失是因为我恰好在重新分配阶段进行搜索。 (3)如果我们中断重新分配过程,我们可以稍后再进行。 (4)它必须是平行的。 我想用有限的阻塞时间来完成(1)和(2),所以无论我需要做什么阻塞工作,我都希望它尽可能短以增加并发性。
我使用了一个简单的并发抽象,该抽象托管了一群共享工作供应商的工人。 工作的提供者将继续提供“大块”的物品,从一个桶搬到另一个桶。 我们一次只能重新分发一个音乐收藏 。 该供应商由所有工作人员共享,但是为了安全的多线程访问而对其进行了同步。
每个工人的算法如下:
(I) Get next chunk of work
(II) For each CD decide the new generation bucket in which it belongs
(accumulating the size deltas for old buckets and new buckets)
(III) Begin database transaction
(IV) Flush accumulated size deltas for buckets
(V) Flush foreign key updates for CDs to put them in new buckets
(VI) Commit database transaction 将为每个工作人员提供大量CD,用于重新分发当前的音乐收藏(I)。 工人会做一些工作来决定哪些桶在新一代应该得到的CD(II)。 工人将累积计数的增量:从原始存储桶中减少,并为新存储桶中增加计数。 然后,工作人员将在相关更新中刷新(IV)这些增量,例如UPDATE Buckets SET size = size + 123 WHERE bucketId = 1 。 刷新大小更新后,它将刷新(V)所有单个更新到外键字段,以引用新一代存储桶,例如UPDATE Cds SET bucketId = 123 WHERE bucketId = 101 。 这两个操作发生在同一数据库事务中。 , 让工作给工人的供应商是典型的“队列”像SELECT查询-我们要遍历所有老一代的音乐收藏中的项目。 这是在单独的连接中发生的,与工作人员无关的数据库事务(稍后讨论)。 将使用工作线程(具有线程安全同步)读取下一个块。 这个单独的“阅读器”连接没有自己的线程或任何东西。
麻烦的第一个迹象–完全静止
因此,我们在不那么快的硬件上进行了一些大容量测试,突然之间……系统突然停顿了。 我们似乎正处于将CD移到新存储桶的中间,而CD只是停止了进步。
找出Java应用程序在做什么
因此,第一步是查看Java应用程序在做什么:
c:\>jps
1234 BucketRedistributionMain
3456 jps
c:\>jstack 1234 > threaddump.outJps找到Java进程ID,然后运行jstack为Java程序中的每个线程输出一个堆栈跟踪。 JDK和Jstack包含在JDK中。
生成的堆栈跟踪显示所有工作人员都在socketRead中等待以完成数据库更新以刷新存储桶大小更新(上述步骤IV)。
这是其中一个工作程序的部分堆栈跟踪(为简便起见,省略了一些无趣的框架):
"container-lowpool-3" daemon prio=2 tid=0x0000000007b0e000 nid=0x4fb0 runnable [0x000000000950e000]
java.lang.Thread.State: RUNNABLE
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.read(Unknown Source)
...
at net.sourceforge.jtds.jdbc.SharedSocket.readPacket(Unknown)
at net.sourceforge.jtds.jdbc.SharedSocket.getNetPacket(Unknown)
...
at org.hibernate.jdbc.BatchingBatcher.doExecuteBatch(Unknown)
...
at org.hibernate.impl.SessionImpl.flush(SessionImpl.java:1216)
...
at com.mycompany.BucketRedistributor$Worker.updateBucketSizeDeltas()
...
at java.util.concurrent.FutureTask$Sync.innerRun(Unknown Source)
...
at java.lang.Thread.run(Unknown Source)如您所见,我们的工作人员正在更新存储桶的大小,这导致了Hibernate的“刷新”(实际上是将数据库查询通过网络推送到数据库引擎),然后在语句完成后等待来自MSSQL的响应数据包。 请注意,我们正在使用jtds MSSQL驱动程序(如堆栈跟踪中的net.sourceforge.jtds所示。
那么下一个问题是, 为什么数据库只是闲逛无所事事?
找出数据库在做什么……
MSSQL提供了许多简单的方法来深入了解数据库的工作。 首先,让我们看一下所有连接的状态。 打开SQL Server Management Studio(SSMS),单击“新建查询”,然后键入exec sp_who2
这将返回如下所示的输出:
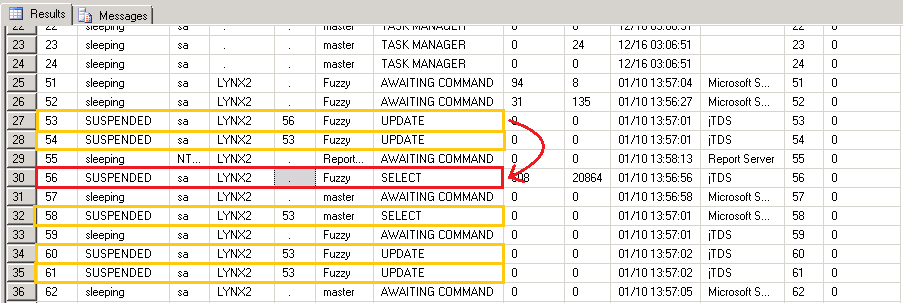
您可以看到数据库会话的所有spid 。 我们应该有五个感兴趣的地方:一个是“工作队列”查询,另外四个是工作人员执行更新。 sp_who2输出包括一个blkBy列,该列显示在给定spid被暂挂的情况下阻止给定spid的spid。
我们可以看到spid 56是“工作队列” SELECT查询(红色突出显示)。 请注意,没有人阻止它……然后,我们看到53、54、60和61(以黄色突出显示)的spid正在等待56(或彼此等待)。 无视58 –如您所见,其应用程序源是Management Studio。
真好奇! 阅读器查询阻止了所有更新工作者,并阻止他们推送其大小更新。 读者的“工作队列”查询如下所示:
SELECT c.cdId, c.bucketId FROM Buckets b INNER JOIN Cds c ON b.bucketId = c.bucketId WHERE b.collection = 'Steves Collection' and b.generation = 23投资阻塞和锁定问题…
我看到spid 56阻止了其他所有人。 那么56持有什么锁呢? 在一个新的查询窗口中,我运行了exec sp_lock 56和exec sp_lock 53以查看每个持有的锁以及谁在等待什么。
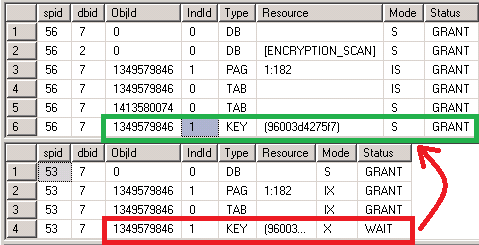
您可以看到56持有对象1349579846的键资源(键=索引上的行锁)上的S(共享)锁 ,该对象对应于Buckets表。
我想针对引擎的执行计划为读者提供“工作队列”查询。 为了做到这一点,我执行了我之前创建的一个查询,以尽可能多地转储有关系统中当前会话的详细信息–将其视为“ super who2”:
select es.session_id, es.host_name, es.status as session_status, sr.blocking_session_id as req_blocked_by,
datediff(ss, es.last_request_start_time, getdate()) as last_req_submit_secs,
st.transaction_id as current_xaction_id,
datediff(ss, dt.transaction_begin_time, getdate()) as xaction_start_secs,
case dt.transaction_type
when 1 then 'read_write'
when 2 then 'read_only'
when 3 then 'system'
when 4 then 'distributed'
else 'unknown'
end as trx_type,
sr.status as current_req_status,
sr.wait_type as current_req_wait,
sr.wait_time as current_req_wait_time, sr.last_wait_type as current_req_last_wait,
sr.wait_resource as current_req_wait_rsc,
es.cpu_time as session_cpu, es.reads as session_reads, es.writes as session_writes,
es.logical_reads as session_logical_reads, es.memory_usage as session_mem_usage,
es.last_request_start_time, es.last_request_end_time, es.transaction_isolation_level,
sc.text as last_cnx_sql, sr.text as current_sql, sr.query_plan as current_plan
from sys.dm_exec_sessions es
left outer join sys.dm_tran_session_transactions st on es.session_id = st.session_id
left outer join sys.dm_tran_active_transactions dt on st.transaction_id = dt.transaction_id
left outer join
(select srr.session_id, srr.start_time, srr.status, srr.blocking_session_id,
srr.wait_type, srr.wait_time, srr.last_wait_type, srr.wait_resource, stt.text, qp.query_plan
from sys.dm_exec_requests srr
cross apply sys.dm_exec_sql_text(srr.sql_handle) as stt
cross apply sys.dm_exec_query_plan(srr.plan_handle) as qp) as sr on es.session_id = sr.session_id
left outer join
(select scc.session_id, sct.text
from sys.dm_exec_connections scc
cross apply sys.dm_exec_sql_text(scc.most_recent_sql_handle) as sct) as sc on sc.session_id = es.session_id
where
es.session_id >= 50在上面的输出中,最后一列是SQL XML执行计划。 对于spid 56,我证实了自己的怀疑:为“工作队列”查询服务的计划是在buckets表上查找“ Steves collection”的“ music collection”索引,然后寻求聚集索引以确认“ generation” = 23',然后在Cds表上查找bucketId索引。 因此,为了在“工作队列”查询中提供WHERE子句,引擎必须同时使用Bucket上的非聚集索引和聚集索引(对于版本谓词)。
当以READ COMMITTED隔离级别连接和读取行时,引擎将在从索引遍历到索引时获取锁,以确保读取一致。 因此,要读取Buckets表中的生成值,它必须获取共享锁。 它有!
当竞争会话试图更新Bucket表的同一记录上的大小时,就会出现问题。 它需要在该行(用红色突出显示)上锁一个X(独占 ),然后注意! 它无法获取,因为该阅读器查询具有冲突的S锁
已授予 (以绿色突出显示)。
好的,这一切都说得通,但是为什么要持有S锁? 在READ COMMITTED上,您通常仅在读取记录时才持有锁(有一些例外,我们将在第2部分中介绍)。 一旦读取该值,它们就会被释放。 因此,如果您在单个语句执行中读取10行,则引擎将:在第1行获取锁,在第1行读取锁,在第1行获取锁,在第2行获取锁,读取第2行,在第2行释放锁,获取锁因此,这四名工作人员目前都没有在读书-他们在写作-或至少是在尝试让讨厌的阅读器连接没有阻止他们。
为了找到这个,我很好奇为什么读者查询处于SUSPENDED状态(请参见上面的原始sp_who2输出)。 在上面的“ super who2”输出中,“工作队列”读取查询的current_req_wait值为ASYNC_Network_IO 。
ASYNC_Network_IO等待以及数据库如何返回结果
ASYNC_Network_IO是一个有趣的等待。 让我们讨论远程应用程序如何执行和使用数据库中的SELECT查询。
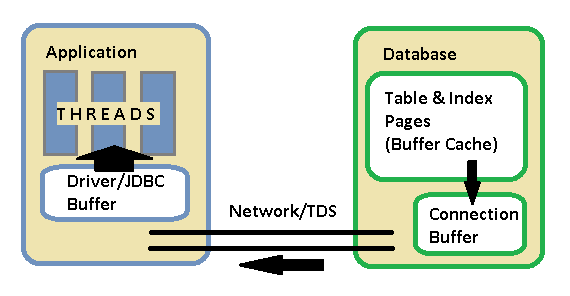
该图被简化了很多,但是在数据库中有两个要讨论的内存块: 缓冲区高速缓存和连接网络缓冲区 。 缓冲区高速缓存是内存的共享块,表和索引的实际页面将保留在其中以用于查询。 因此,在执行“工作队列”查询时,Buckets和Cds表的一部分将位于内存中。 执行引擎执行计划,在缓冲区高速缓存之外工作,获取锁,并生成输出记录发送给客户端。 在准备这些输出记录时,会将它们放入特定于连接的网络缓冲区中 。 当应用程序从结果集中读取记录时,它实际上是从数据库中的网络缓冲区提供的。 应用程序驱动程序通常也具有自己的缓冲区。
当您仅执行一个简单SQL SELECT查询而没有显式声明数据库游标时,MSSQL会为您提供所谓的“默认结果集”(仍然是各种游标),您可以将其视为一个游标。一堆记录,您只能沿向前方向迭代一次。 当您的应用程序线程遍历结果集时,驱动程序代表您从数据库请求更多的行块,从而耗尽了网络缓冲区。
但是,对于非常大的结果集,整个结果无法容纳在连接的网络缓冲区中。 如果应用程序读取它们的速度不够快,那么最终网络缓冲区将被填满,执行引擎必须停止生成新的结果记录以发送给客户端应用程序。 发生这种情况时,必须暂停spid,并使用等待事件ASYNC_Network_IO将其暂停。 这是一个稍带误导性的等待名称,因为它使您认为可能存在网络性能问题,但通常是应用程序设计或性能问题。 请注意,当spid暂停时(与其他任何暂停一样), 当前保持的锁将保持保持状态,直到spid恢复 。
在我们的案例中,我们知道我们有数百万张CD,并且无法一次将它们全部放入应用程序内存中。 根据设计,我们希望利用这样一个事实,即我们可以从数据库中流式传输结果并按块进行处理。 不幸的是,如果在读取器查询挂起时碰巧持有一个冲突的锁(Bucket记录上的S锁),那么我们将观察到我们创建了一个多层应用程序死锁,整个系统陷入瘫痪。
那么该怎么办呢? 我将在第2部分和第3部分中讨论一些选项以及我们最终的决定。请注意,当我谈到“覆盖索引”时,在第一次尝试时给出了一个提示,然后上面还有另一个提示,我们没有涉及到发表有关“锁定升级”的信息。
c#程序 数据库死锁















 2682
2682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









