





本地缓存 分布式缓存
缓存是一个可以神奇地存储数据的组件,因此将来对同一数据的请求不会发送到远程服务器,因此可以显着更快地提高应用程序的性能。
我们正在一个网站上工作,该网站将通过使用API与现有应用程序集成,并且为了更紧密地集成,我们决定将XML形式的数据作为工件存储在该工具中,作为跟踪器项目–而不是RDBMS。 就像在臀部运行两个应用程序一样。
当我将它们与Ms-Excel集成在一起时,我在使用SourceForge平台API方面积累了丰富的经验,现在我们将使用相同的API在ALM空间上构建整个应用程序。 我们最大的挑战将是性能,因为针对位于不同地理位置的远程服务器使用了API。 Cache将会帮助我们解决该问题。
我们刚刚决定实施直写式高速缓存,该高速缓存可以帮助我们构建一个系统,该系统的速度大大提高,任何人都可以想到。 从那时起,这是我在各种系统上工作时都会使用的一种模式(如果可能)。 出乎意料的是,当使用这种模式可以解决系统的基本问题时,曾经使用过高速缓存的人们中从未听说过这种高速缓存实现模式(对于为什么不这样做,我还是很困惑)。
在深入探讨之前,我想遍历本文中将要使用的一些定义:
- 缓存命中是指对数据的请求并在缓存中找到它
- 高速缓存未命中是指对数据的请求,但未在高速缓存中找到它
- 如果脏数据与原始数据不同,则表示脏数据
- 如果不是实时执行的,而是仅在需要时执行,则延迟是指一项操作
以最简单的形式,缓存实现将类似于下图。
正如您已经看到的那样,这只是缓存实现的一部分,仅实现此工作流程就意味着一旦缓存中有数据,它就只会始终从本地缓存位置获取数据并返回原始数据。仅当高速缓存数据为Dirty时,才提供源。 我们必须通过多种方法将数据标记为脏数据–这可以是我们在系统中配置的操作,例如–“如果要更新数据源中的记录,我们将尝试查找密钥并将其标记为脏数据”。 另一种方法是确定缓存应在其后自动过期的时间。
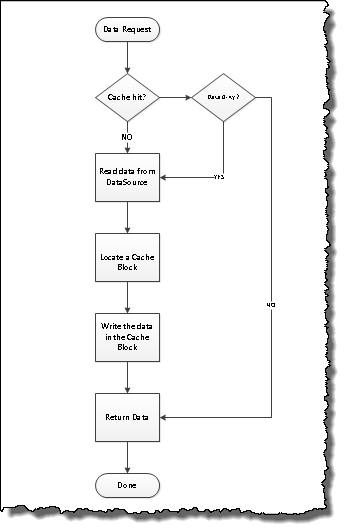 |
| 缓存–工作流程 |
尽管这种方法非常简单,但这确实带来了一个独特的“问题”(并且可能不是每个人都遇到的问题)。 让我们回顾一下我们决定实现缓存的原因。
缓存是一个可以神奇地存储数据的组件,这样将来对同一数据的请求就不会发送到远程服务器,因此它将大大提高我们应用程序的性能。
这意味着“在数据加载方面,与我们的数据源相比,缓存是一种更快的机制”。 我已经观察到针对RDBMS的高速缓存实现,该RDBMS位于Application Server旁边,这意味着从RDBMS加载数据仍然更快,因此,实际上没有必要像先前定义的那样临时使用高速缓存。
在我们的例子中,我们正在处理一个外部系统,该系统通过HTTPS从中获取XML,然后将XML转换为对象。 整个过程很耗时-一个物体要花3秒钟,而减少运输时间我们无能为力。 这也意味着我们的经典工作流程也不起作用,尤其是如果用户将更新特定记录,并且如果将缓存标记为脏,则下一个请求将意味着大量的延迟时间。
我们即兴创作,然后我们使用了直写式高速缓存逻辑,该逻辑允许我们使用数据源实时管理高速缓存中的数据。 工作流程已更改为以下工作流程:
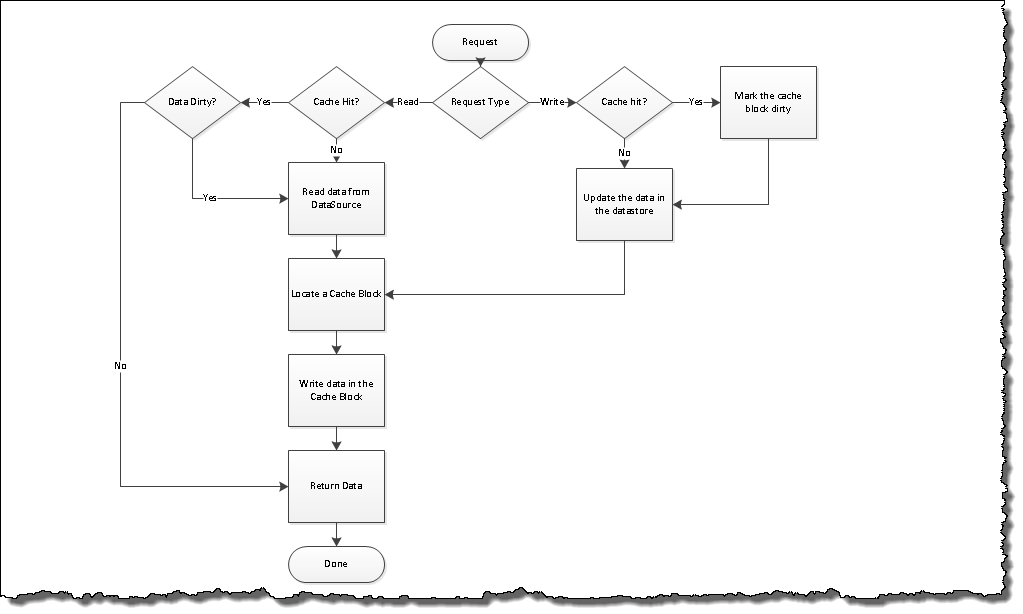
看起来并不那么简单。 首先让我们看看我们做了什么。 我们在代码中添加了一个挂钩,该代码将数据保存到DataSource中需要执行以下两项操作:
- 查找高速缓存条目,如果命中,将其标记为脏,并且;
- 成功更新数据存储后更新缓存
这使我们能够使高速缓存与DataSource保持同步,因此不需要花费额外的时间来再次加载数据。
但是,据我所知,每个解决方案都会带来挑战,这个解决方案也同样具有挑战性,尤其是当我们决定扩展并迁移到应用服务器集群时。 这意味着本地缓存根本无法工作,因为这意味着对DataSource的更新意味着其他应用程序服务器上的缓存已过期,并且用户将无法获得最新的数据,从而使其无法工作。 我们确实使用版本记录来管理并发检查,并且不保持高速缓存的同步意味着其他用户将看到他们的更新失败,因为这种故障保护非常安全。 最终,我们不得不找到一个可以在集群中扩展的缓存,这只会使事情变得更加复杂。
我在开发青春期学习的一种模式,已被证明是一种强大的技术,可用于构建在给定场景下可以正常工作的解决方案。
参考: Scratch Pad博客上来自我们JCG合作伙伴 Kapil Viren Ahuja的直写式高速缓存 。
翻译自: https://www.javacodegeeks.com/2012/01/write-through-cache.html
本地缓存 分布式缓存















 512
512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









