







https://community.arm.com/cn/b/blog/posts/ne10-fft
September 3, 2014
1 简介
最近,我们更新了Ne10库里面的FFT算法。不管是ARMv7还是ARMv8平台,我们都利用NEON技术充分优化了FFT算法。现在Ne10库里的FFT算法,比大部分现有的FFT实现都要更快一些,比如FFTW,OpenMax DL。本文着重介绍Ne10库里的FFT的最新变化。
2 性能对比
下面图表描述了Ne10的32位浮点复数FFT,FFTW和OpenMax DL FFT的性能测试结果。测试平台是ARM Cortex A9。X轴代表FFT的输入长度,Y轴代表了FFT算法运行时间,时间越短越好。
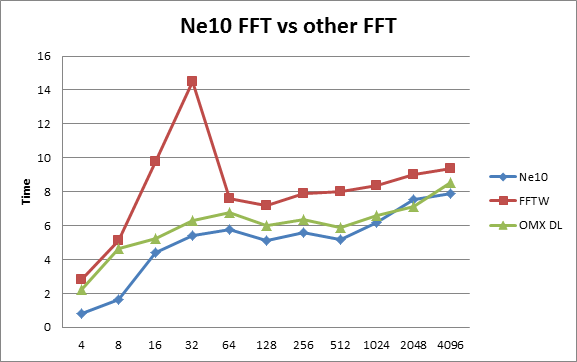
从图上我们可以看出来,在大部分情况下,Ne10里的FFT 比FFTW和OpenMax DL具有更好的性能。
3 ARM v7/v8平台的FFT
3.1 NEON使用
想要利用NEON技术,我们通常有两种选择:
- NEON 汇编
- NEON intrinsic指令
下表阐述了汇编和intrinsic各自的优缺点。
| NEON 汇编 | NEON intrinsic | |
| 性能 | 对于指定平台,汇编总是呈现最好性能 | 极大地依赖于编译器 |
| 可移植性 | ARM v7-A/v8-A平台 具有不同的汇编格式。即使在ARM v7-A平台,汇编程序也需要针对Cortex A9/A7/A15微架构做出不同调整,才能呈现最好性能。 | 选择合适的编译器选项,一次编程即可以很容易实现跨平台并针对该平台微架构调整性能,例如ARM v7-A Cortex A9/A7/A15和ARM v8-A Cortex A53/A57。 |
| 可维护性 | 相比C语言,较难编程,可读性较差 | 跟C语言类似,比较容易编程与维护 |
3.2 ARM v7-A/v8-A FFT实现
在上一节里面,我们已经分析了NEON汇编/intrinsic的优缺点。对于 Ne10项目来讲,我们首选 intrinsic指令,这样我们可以只维护一套代码。
但是,对于FFT算法来说,由于算法实现和硬件资源的关系,我们必须有不同代码去适应ARM v7/v8平台。原因如下所述:
| // radix 4 butterfly with twiddles scratch[0].r = scratch_in[0].r; scratch[0].i = scratch_in[0].i; scratch[1].r = scratch_in[1].r * scratch_tw[0].r - scratch_in[1].i * scratch_tw[0].i; scratch[1].i = scratch_in[1].i * scratch_tw[0].r + scratch_in[1].r * scratch_tw[0].i; scratch[2].r = scratch_in[2].r * scratch_tw[1].r - scratch_in[2].i * scratch_tw[1].i; scratch[2].i = scratch_in[2].i * scratch_tw[1].r + scratch_in[2].r * scratch_tw[1].i; scratch[3].r = scratch_in[3].r * scratch_tw[2].r - scratch_in[3].i * scratch_tw[2].i; scratch[3].i = scratch_in[3].i * scratch_tw[2].r + scratch_in[3].r * scratch_tw[2].i; |
上述代码描述了32位浮点复数FFT算法的基本元——基4蝶形运算。从代码中我们可以总结如下:
- 如果在一次循环中,两个基4蝶形运算并行,我们需要20个 64位寄存器。
- 如果在一次循环中,四个基4蝶形运算并行,我们需要20个 128位寄存器。
- ARM v7-A 平台仅有32个64位或者16个128位寄存器。
- ARM v8-A 平台有32个128位寄存器。
由于以上原因,目前我们利用汇编来实现ARM v7-A的FFT,该实现仅能实现一次循环两个基4蝶形运算并行。我们利用Intrinsic来实现ARM v8-A的FFT,该实现能实现一次循环四个基4蝶形运算并行。
3.3 C/NEON性能对比
下图描述了v7/v8平台的FFT性能增益。柱状越大越好。
蓝色柱状描述了在Cortex-A53(ARM v8) 32位模式下C和NEON运行时间的对比。源码采用了C语言和ARM v7 NEON汇编。工具链是gcc 4.9。
红色柱状描述了在Cortex-A53(ARM v8) 64位模式下C和NEON运行时间的对比。源码采用了C语言和ARM intrinsic。intrinsic的性能极大地依赖编译器。经过测试,我们发现llvm3.5使FFT具有最好的性能。因此我们使用llvm3.5来编译64位模式下的代码。
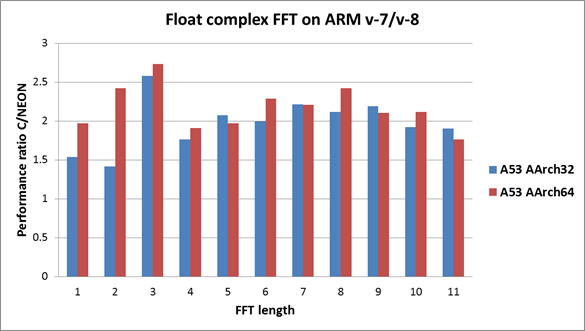
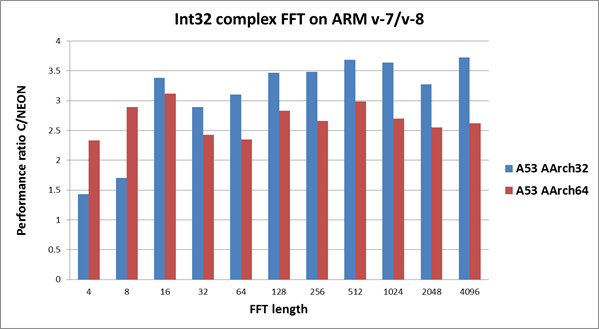
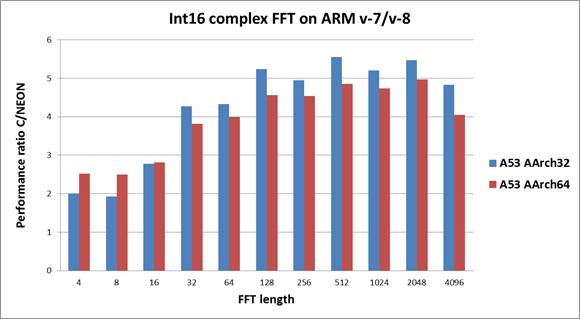
从上图我们可以看出,对比32位模式和64位模式,浮点型复数FFT总是表现出相似或更好的性能增益。但是对于整数型复数FFT, 32位模式下的性能增益总是好于64位模式。(但是这并不代表32位模式下的整数型复数FFT优于64位模式!更多性能数据请参考下文。)
这些实验数据和优化经验对于以后我们正确分析ARM v8 64模式的性能增益有极大的借鉴作用。但是我们还需要更多的数据去完善和补充我们的经验。
3.4 32位模式/64位模式性能对比
下列图表都是以32位C实现的性能作为基准来描述32位模式NEON和64位模式C和NEON的性能。柱状越大越好。
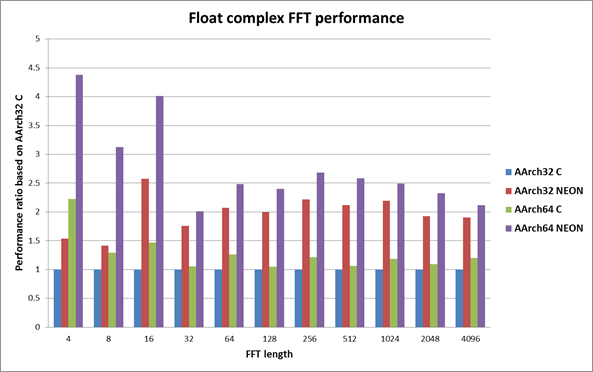
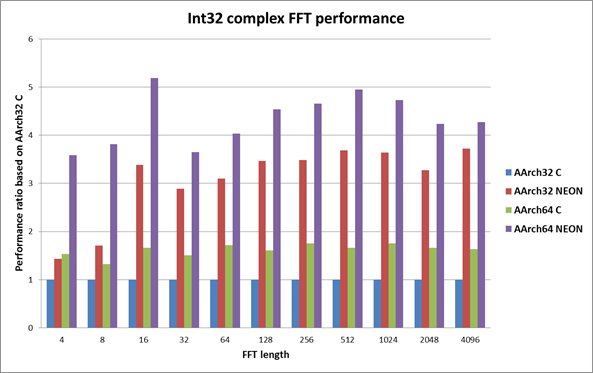
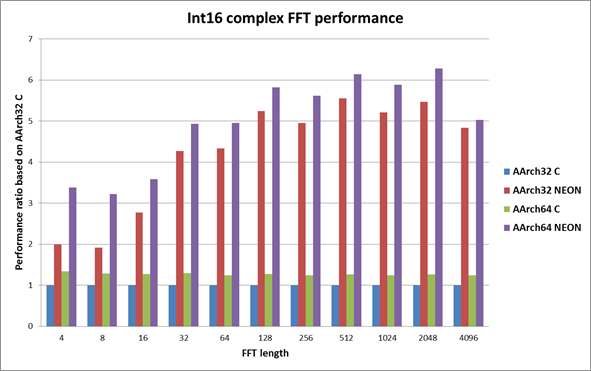
从上述图表我们可以看出,无论是C实现还是NEON实现,64模式下FFT性能总是优于32为模式。
4 FFT使用
4.1 APIs
现在,Ne10里面的FFT依然支持下列的数据类型和特性:
| 变换类型 | 数据类型 | FFT长度 |
| c2c FFT/IFFT | float/int32/int16 | 2^N (N is 2, 3….) |
| r2c FFT | float/int32/int16 | 2^N (N is 3, 4….) |
| c2r IFFT | float/int32/int16 | 2^N (N is 3, 4….) |
但是现在的API有了一些改变。老用户最好更新到 v1.1.2 版本或者 master分支。
更多API细节:http://projectne10.github.io/Ne10/doc/group__C2C__FFT__IFFT.html。
4.2 实例
以浮点 c2c FFT/IFFT为例, 现在的API的使用方法如下 .
#include "NE10.h"
……
{
fftSize = 2^N; //N is 2, 3, 4, 5, 6....
in = (ne10_fft_cpx_float32_t*) NE10_MALLOC (fftSize * sizeof (ne10_fft_cpx_float32_t));
out = (ne10_fft_cpx_float32_t*) NE10_MALLOC (fftSize * sizeof (ne10_fft_cpx_float32_t));
ne10_fft_cfg_float32_t cfg;
cfg = ne10_fft_alloc_c2c_float32 (fftSize);
……
//FFT
ne10_fft_c2c_1d_float32_neon (out, in, cfg, 0);
……
//IFFT
ne10_fft_c2c_1d_float32_neon (out, in, cfg, 1);
……
NE10_FREE (in);
NE10_FREE (out);
NE10_FREE (cfg);
}5 结论
通过FFT算法,我们可以知道,ARM v8可以帮助用户得到更大的性能提升。在不久的将来,希望我们可以找到更多的ARMv8应用。
更多信息,请访问 https://github.com/projectNe10/Ne10

















 4749
4749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









