







Java 基础篇之 ConcurrentHashMap
-
jdk1.7和jdk1.8的ConcurrentHashMap底层数据结构
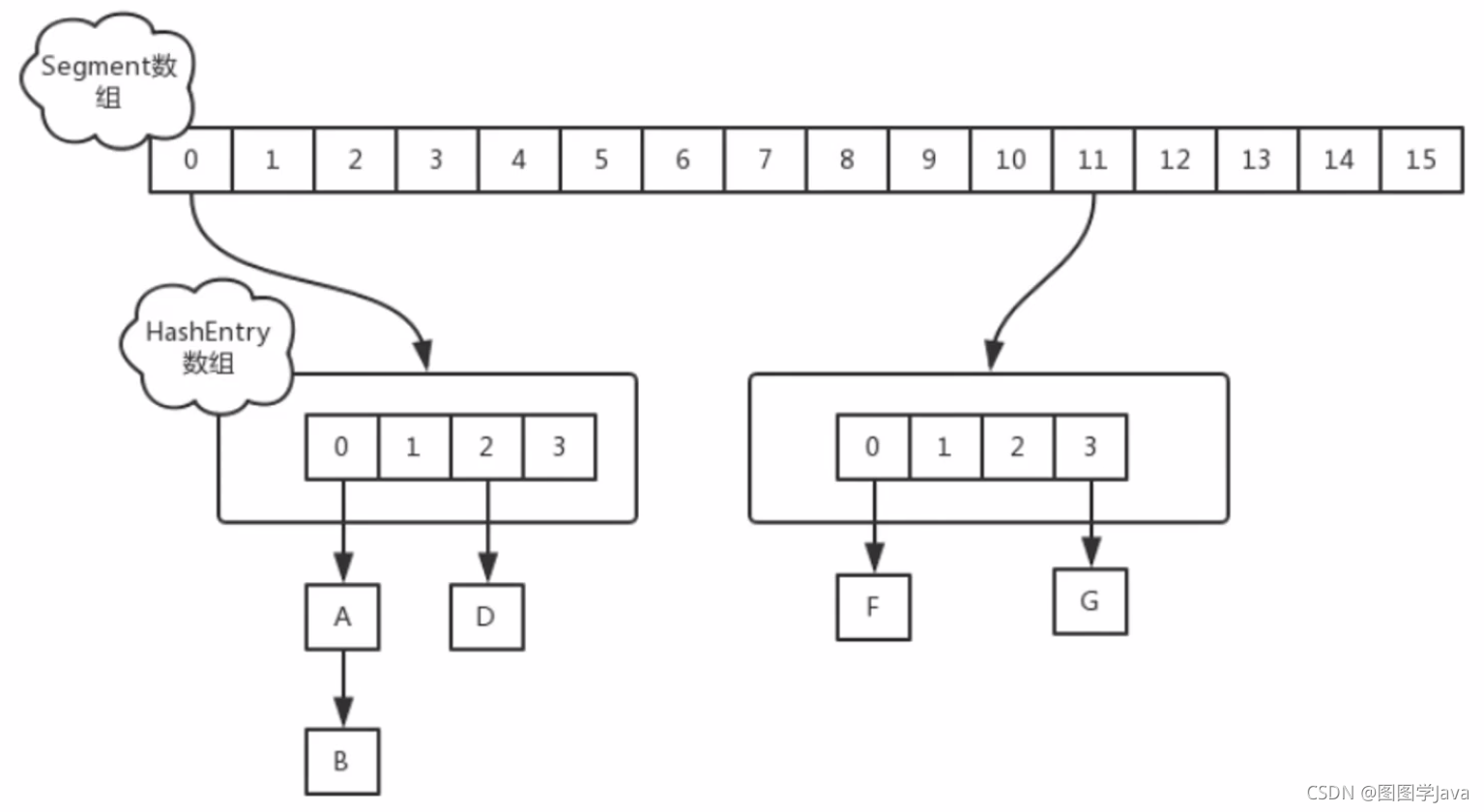
jdk1.7:由一个Segment数组和多个HashEntry组成
Segment数组就是将一个大的table分割成多个小的table来进行加锁(分段锁思想,继承ReentrantLock),而每一个Segment元素存储的时HashEntry数组。
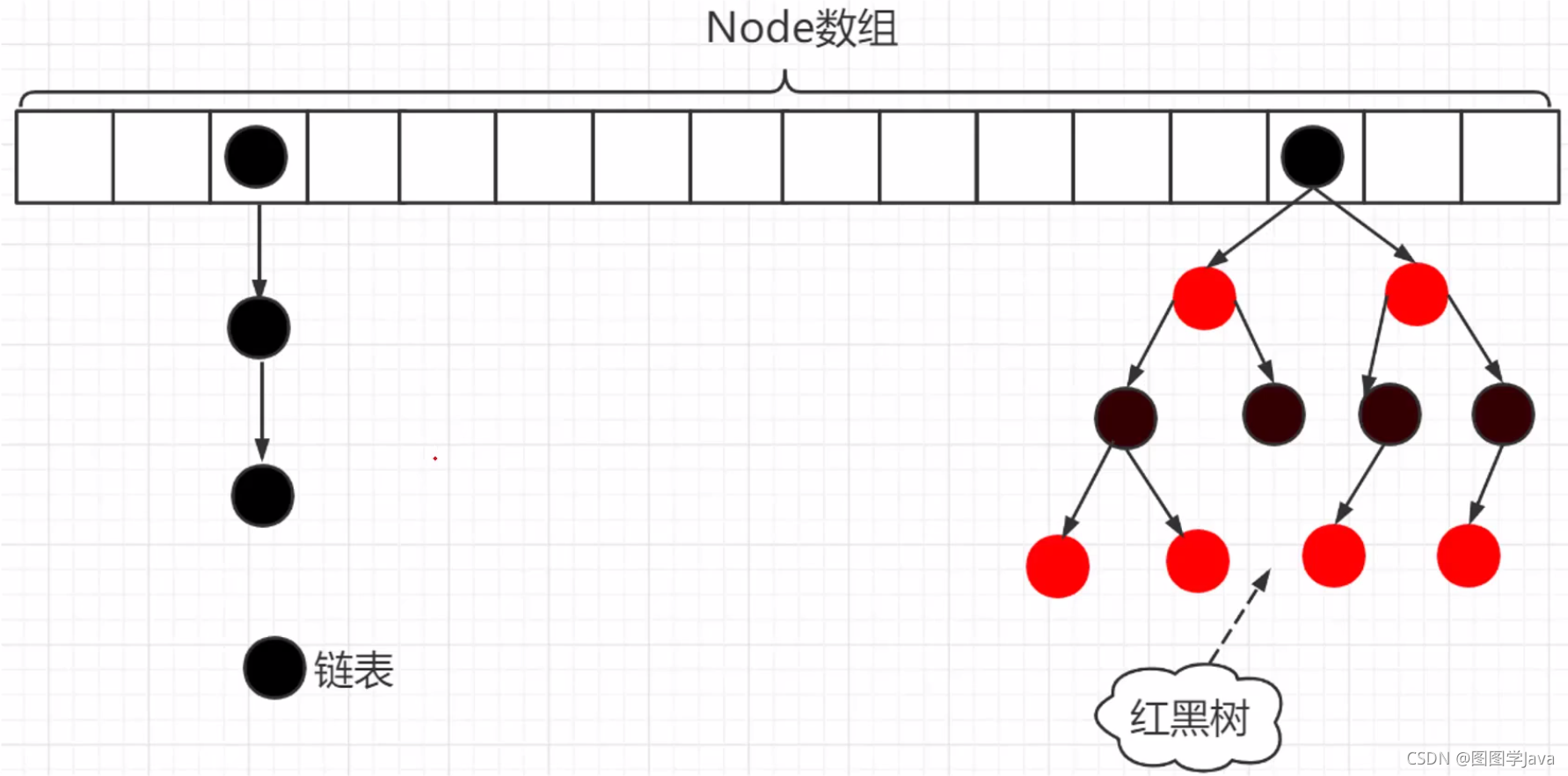
jdk1.8:废弃了Segment,采用Node数组+链表+红黑树的数据结构来实现
-
jdk1.7和jdk1.8的ConcurrentHashMap的区别
① 数据结构不同
jdk1.7是Segment+HashEntry,jdk1.8是Node数组+链表+红黑树
② 线程安全机制不同
jdk1.7是ReentrantLock,jdk1.8是CAS、synchronized
③ 锁的粒度不同
jdk1.7是对进行数据操作的Segment加锁,jdk1.8是对数组元素加锁 (头节点)
注:获取数据两个版本都是通过volatile来保证数据的可见性。
-
jdk1.8 ConcurrentHashMap 的put方法流程
① 计算hash值
② 如果没有初始化就先调用initTable方法进行初始化过程(CAS)
③ 如果没有hash冲突就直接CAS插入
④ 如果还在进行扩容操作就先进行扩容
⑤ 如果由hash冲突,则加锁来保证线程安全(synchronized)
⑥ 如果链表数量大于等于8,且数组长度大于64,则转为红黑树
⑦ 如果成功添加就调用addCount方法统计size,并检查是否需要扩容
-
jdk1.8 ConcurrentHashMap 的get方法流程
① 计算hash值,定位到该table位置,如果首节点符合就直接返回② 如果遇到扩容,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回
③ 以上都不符合,就往下遍历节点,匹配就返回,否则最后返回null
-
jdk1.8中为啥用synchronized代替ReentrantLock
jdk1.7版本及以前:使用Segment,初始化为容量为16,而每个Segment都继承了ReentrantLock类,这样每个Segment类本身就是一 个锁,之后Segment内部又是一个HashEntry数组,每个HashEntry里面对应着一个Node链表。 那么当put元素时,对其key进行hash,然后对16取模得到对应的Segment的下标,之后调用对应Segment的lock()上锁,也就是每个Segment的锁是分开的,并发量为Segment的个数。
jdk1.8版本:使用synchronized锁住的是链表的头节点,即锁住的是hash冲突的那条链表,锁的粒度细化了。
🤔如果使用ReentrantLock其实也可以,只要让Node类继承ReentrantLock就行了,这样f.lock()就能做到synchronized(f)同样的效果,但是为什么不这样做?
原因:
① 锁已经被细化到hash冲突的情况了,这种情况下并发争抢的可能性就很低了,哪怕出现了挣抢情况,只要线程可以在自旋30~50次里拿到锁,那么synchronized就不会升级为重量级锁,而等待的线程也就不用被挂起,不用有挂起和唤醒操作所带来的上下文切换性能消耗。
② 但是ReentrantLock,只要有线程没有争抢到锁,就会新建Node节点后再尝试一次,而不是自旋,而是直接挂起,这样一来就会出现挂起和唤醒所带来的上下文切换性能消耗。
-
ConcurrentHashMap 迭代器是强一致性还是弱一致性?HashMap呢?
ConcurrentHashMap 迭代器使用的是弱一致性。
java.utl 包中的集合类都使用fail-fast(快速失败)迭代器,所以HashMap也是这种迭代器。
这种迭代器意味着有线程在集合内容进行迭代时,其集合不能更改它的内容,如果有检测到在迭代过程中进行了更改操作,那么它会抛出ConcurrentModificationException,这是不可控的异常。在迭代过程中不可变更集合的情况对并发应用不便。弱一致性:当迭代器创建或者调用 next 方法时,都会调用 Traverser 中的 advance 方法来获取下一个有效结点。这个方法会根据当前 table 中 index 桶的状态来返回有效结点,如果桶是处于正常状态,那么就返回桶中的结点;如果 index 桶处于扩容状态,那么就根据 nextTable 中的 index 和 index+table.length 桶的状态来返回有效结点。在 nextTable 中访问完目标结点之后,返回到 table 再次向 ++index 桶的状态进行判断并返回,直到 table 中的桶被遍历完。在 advance 方法中通过不断循环遍历,其中考虑到table的大小发生变化,并且节点的组织方式可能是链表也可能是红黑树,遍历的过程中可能会有部分数据遍历不到,此为弱一致性的表现。
















 2656
2656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











