







hive和SparkSQL区别
hive将SQL转为MapReduce SparkSql可以简单理解将SQL转为RDD+优化在执行
spark处理数据类型
Spark 的 RDD 主要用于处理 非结构化数据 和 半结构化数据 结构化
SparkSQL中的SQL 主要用于处理 结构化数据(较为规范的半结构化数据也可以处理)
DataFrame
DataFrame 是一种以RDD为基础的分布式数据集,类似传统数据库的二维表,DataFrame带有Schema元信息(列名和类型)
即DataFrame所表示的二维表数据集的每一列都带有名称和类型 DataFrame可以从很多数据源构建
总结:DataFrame = RDD —泛型 +Schem+SQL+优化
DataSet
DataSet 可以通过哦JVM的对象进行构建,可以用函数式的转换 (map \flatmap\filter)进行多种操作
DataFrame 就是DataSet[Row]
总结: DataSet =DataFrame+泛型
RDD、DataFrame、DataSet的区别

1.RDD[Person]

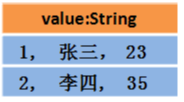
2.那么DataFrame中的数据长这样
DataFrame = DataSet[Row] = RDD[Person] - 泛型 + Schema + SQL操作 + 优化

3.那么Dataset中的数据长这样(每行数据是个Object):
Dataset[Person] = DataFrame + 泛型

或者长这样:Dataset[Row]
总结:
DataFrame = RDD - 泛型 + Schema + SQL + 优化
DataSet = DataFrame + 泛型
DataSet = RDD + Schema + SQL + 优化
DataFrame = DataSet[Row]
创建DataFrame(以读取TXT为例)
//创建RDD
val lineRDD =sc.textFile("hdfs://node01:8020//test/input/person.txt").map(_.split(" "))
// 定义case class 样例类 相当于schema
case class (id:Int,name:String,age:Int)
//关联schema和RDD
val personDD =lineRDD.map(x =>Person(x(0).toInt,x(1),x(2).toInt))
//将RDD转换成DataFrame
val person =personRDD.toDFS创建DataSet
1.通过Spark.createDataSet 创建
val fileRDD =sc.textFile("hdfs://node01:8020/test/input/person.txt")
val ds=spark.createDataset(fileRdd)
ds.show
2.通RDD.toDS生成DataSet
case class Person(name:String, age:Int)
val data = List(Person("zhangsan",20),Person("lisi",30)) //List[Person]
val dataRDD = sc.makeRDD(data)
val ds2 = dataRDD.toDS //Dataset[Person]
ds2.show
3.通过DataFrame.as[泛型]转化生成DataSet
case class Person(name:String, age:Long)
val jsonDF= spark.read.json("file:///export/servers/spark/examples/src/main/resources/people.json")
val jsonDS = jsonDF.as[Person] //DataSet[Person]
jsonDS.show两种风格
(1)DSL风格
personDF.select(personDF.col("name")).show
personDF.select(personDF("name")).show
personDF.select(col("name")).show
personDF.select("name").show(2)SQL风格
personDF.createOrReplaceTempView("t_person")
spark.sql("select * from t_person").show















 5735
5735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









