







二分查找是一种效率很高的查找方法,但是二分查找要求数据结构必须是顺序表,也就是类似于数组的连续存储,因为只有这样才能一下定位出数组的中间位置(直接使用类似a[len / 2]),然后就可以把数组一分为二,进行后面的操作。
但是对于链表,由于存储是离散的,不能像数组一样,快速定位中间位置,来把链表一分为二,所以一般的二分查找不能直接应用于链表。
本文要说的跳跃表其实也可以算是一种新的数据结构,采用空间换时间的方式来达到近似二分查找的效率。
其中存放的数据也是有序的。
平衡二叉树也是一种查找方式,但是这种查找方式为了维持树的平衡,需要进行复杂的操作(旋转等),学习和使用难度很大。
而本文要说的跳跃表就是一种较为简单的方式来达到替代平衡二叉树的效果。
对于平衡二叉树不多做介绍。
先复习一下二分查找的过程,一个简单的顺序表如下:
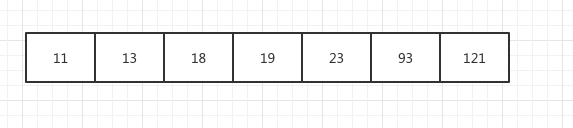
如何查找93这个元素呢?(当然这是没有什么意义的,只讨论算法)
先取数组中间元素比较,如果比中间元素大,就与右边比较,重复本步骤,直到取出。
分析:
那么对于离散存放的数据怎么办呢?我们无法直接取出中间元素。

不能直接找到19的位置(除非从头遍历,但是时间复杂度达不到要求)
这简单,我们找个变量把中间的位置存起来不就行了吗?如下:

但是还是有问题,当比较完一次后,要进行第二次比较时(左:11-18或右23-121)比较时,怎么取出它们的中间元素呢? 答案是跟上边一样,再找变量存起来他们的位置。

很明显第一次查找时与19 copy比较,第二次查找时与13 copy或19copy比较,那么怎么知道第一次要与19 copy,而不是13 copy?也就是如何区分19 copy与13 copy, 93 copy, 其实从图中也可以看出来了–分层。
把19 copy放在第一层, 13 copy, 93 copy放在第二层,那么在比较时先取第一层的元素比较,然后跟第二层中某个元素比较就,来确定最终位置就可以了。

还需要把同一层的元素链接起来(不然怎么说是同一层呢),如果与本层第一个元素比较后,大于第一个元素,那么就可以取后面的元素来继续比较。
最终情况类似:

实现:
根据上面的描述,我们先分析一下跳跃表节点需要哪些成员,存放数据的区域(value,可以是需要的数据类型,这里使用int方便演示), 一个分值(score, 用于排序),还需要一个向右指的指针(right,来寻找本层下一个元素),还需要一个向下的指针(down,确定本元素在下一层的位置,在下一层查询过程中,直接以本元素的位置为基准)。
有一些实现是使用上面这几个成员,但是这里我们直接采用论文中节点的形式:

可以看到,跟我们上面的描述还是有区别的,value, score域肯定是相同的,但是并不是一个节点只有一个right域,而是一个节点可能有多个right, 如6节点就有4个right, 而且这四个right是以数组的方式放在数据后面的,这样也有好像,就是不需要down节点来指向下一层对应自己的元素的。
比如上上图中的19 copy2要根据down来找到19 copy1, 然后19copy1根据down来找到19.
但是这里就不需要down指针了,因为只有一个节点。
所以这里我们需要的成员有value, score, 还有一堆right, 如下
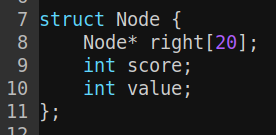
为了简单,所有节点都有20个right, 而不动态伸缩。
跳跃表本身的结构直接给出:
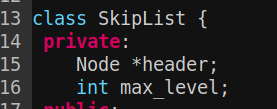
header就是最左侧的节点,他的right指向本层第一个数据节点,max_level表示当前已使用的最大层数。
初始化:
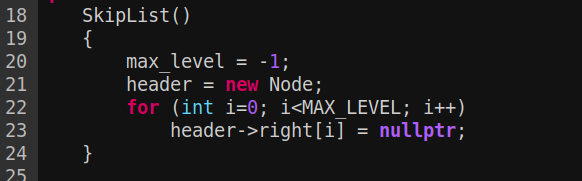
比较简单,初始化完成后如下图:

right0-right19就表示level0-level19, 共20层。
查找
伪代码如下:

先取header, 主要是为了使用right域(也就是伪代码中的forward),
x = list->header, 然后取x->forward[i], 相当于我们的x->right[i], 就是取第i层(right0-19表示了level0-19层)
先看外层循环,是从list->level,相当于我们代码中的list->max_level, 由最外层开始,这个双重循环我们直接看个例子来解释。
还是这个图
比如我们查找12这个元素,外层循环第一次(i=最外层),然后内层while循环x->forward[i]->key, 其实就是取了 6这个元素节点的score来与要查找的score比较(原文中叫key), 6比12小,x=x->forward[i], 这个时候x就指向了6节点(刚才指向header),那个外层循环i就递减第第二层, 再比较时就是x->forward[i], 这个时候i为第二层,x为节点6,那么就是比较25节点了(6的forward在第二层的指向),依次进行。
经过上面双重循环后x应该指向的是9这个结点,这个时候已经到最下边一层了。
然后下一行代码 x = x->forward[1], 就是把最后一层的下一元素(大于等于待查找数值的,当前元素是小于待查找数值的),赋值给x,进行最后的比较。
可以看到这种查找是类似于二分查找的过程的。
C++代码如下:尽可能与伪代码描述符合。

插入:
伪代码:

只解释两个地方:
1.使用与查找算法相同的方式找到每一层要更新的位置,记录到update数组中,最下边的循环会一起处理。
2. randomLevel()可以说是算法最重要的地方了,上面例图中的6有4层,9有2层是怎么确定的呢?答案是随机确定的,也正是由于使用这个概率的方式,查询操作的时间复杂度可以达到O(logN)。所以说中间的节点不一定是最高层(最先被查找(顺序表是中间的最先被查找)),而是完全随机的。

删除:
没有看,如果读者想实现的话,可以参考文末的论文链接,自行实现。
主要是光写查询,插入就花了很长时间,还有bug,实在是没精力去研究删除了。
本文代码:
#include <iostream>
#include <cstdlib>
#include <ctime>
#define MAX_LEVEL 20
struct Node {
Node* right[20];
int score;
int value;
};
class SkipList {
private:
Node *header;
int max_level;
public:
SkipList()
{
max_level = -1;
header = new Node;
for (int i=0; i<MAX_LEVEL; i++)
header->right[i] = nullptr;
}
Node* search(int score_search)
{
std::cout << "search path is ";
Node *x = header;
for (int i=max_level; i>=0; i--) {
while (x->right[i]->score < score_search) {
std::cout << " " << x->right[i]->score;
if ((nullptr == x->right[i]) || (nullptr == x->right[i]->right[i]))
break;
x = x->right[i];
}
std::cout << std::endl;
}
if (nullptr != x->right[0])
x = x->right[0];
if (x->score == score_search)
return x;
return nullptr;
}
void insert(int score, int value)
{
Node *update[MAX_LEVEL];
int new_level = random_level();
Node *x = header;
for (int i=max_level; i>=0; i--) {
while ((nullptr != x->right[i]) && (x->right[i]->score < score))
x = x->right[i];
update[i] = x;
}
if (nullptr != x)
x = x->right[0];
if (nullptr != x) {
if ((x->score == score)) {
x->value = value;
return;
}
}
if (new_level > max_level) {
for (int i=max_level; i<=new_level; i++)
update[i] = header;
max_level = new_level;
}
x = new Node;
x->value = value;
x->score = score;
for (int i=0; i<=new_level; i++) {
x->right[i] = update[i]->right[i];
update[i]->right[i] = x;
}
}
int random_level()
{
/* srand不能放在这里 */
int r = 0;
while (rand() % 2)
++r;
return r;
}
void traverse()
{
Node *t = nullptr;
for (int i=max_level; i>=0; i--) {
t = header->right[i];
if (nullptr != t) {
std::cout << "level" << i << ": ";
while (t) {
std::cout << t->score << " ";
t = t->right[i];
}
std::cout << std::endl;
}
}
}
};
int main()
{
srand((unsigned int)time(0));
SkipList *skip_list = new SkipList;
skip_list->insert(9, 99);
skip_list->insert(7, 77);
skip_list->insert(8, 88);
skip_list->insert(6, 66);
skip_list->insert(3, 33);
skip_list->traverse();
Node *f = skip_list->search(8);
std::cout << "find element is " << f->value << std::endl;
return 0;
}
注:本文中代码有bug, 可用于学习算法,不能在生产环境中直接使用。
参考:
论文链接:https://www.cl.cam.ac.uk/teaching/0506/Algorithms/skiplists.pdf















 621
621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









