







教你几招网盘下载不限速
今天给大家安利几招可以给百度网盘提速的方法,不用开会员也可以快速下载你需要的大文件,逃离百度网盘几十kb的魔爪!
话不多说先看效果,有图为证
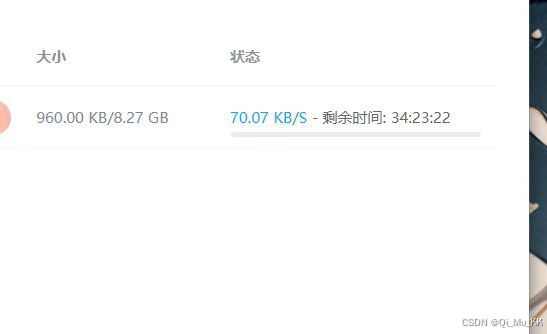
百度网盘下载速度(同一文件下载速度是KB/s):
根据每人网速不同下载速度不同,博主这里用的是手机热点,宽带好的老爷们理论上可以跑满宽带,到达几百MB/s
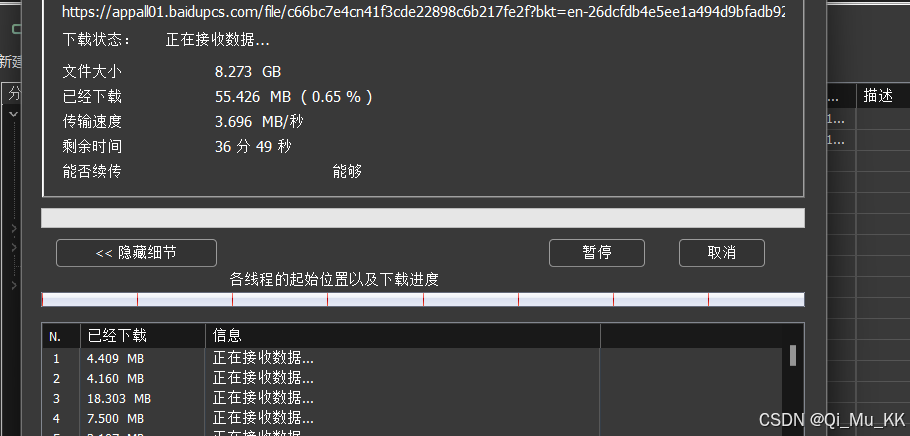
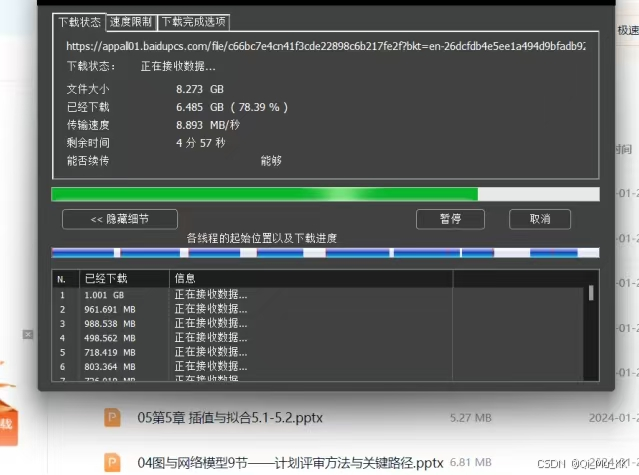
跟着博主教程成功配置后(一开始稳定速度4MB/s,后面速度飙升,最高9MB/s下载,原本28h下载时间,不花钱只要不到20分钟,太香了!):
方法一(简单免费,适合部分小文件但还是受限于网盘)
1. 启动百度网盘客户端,打开设置。
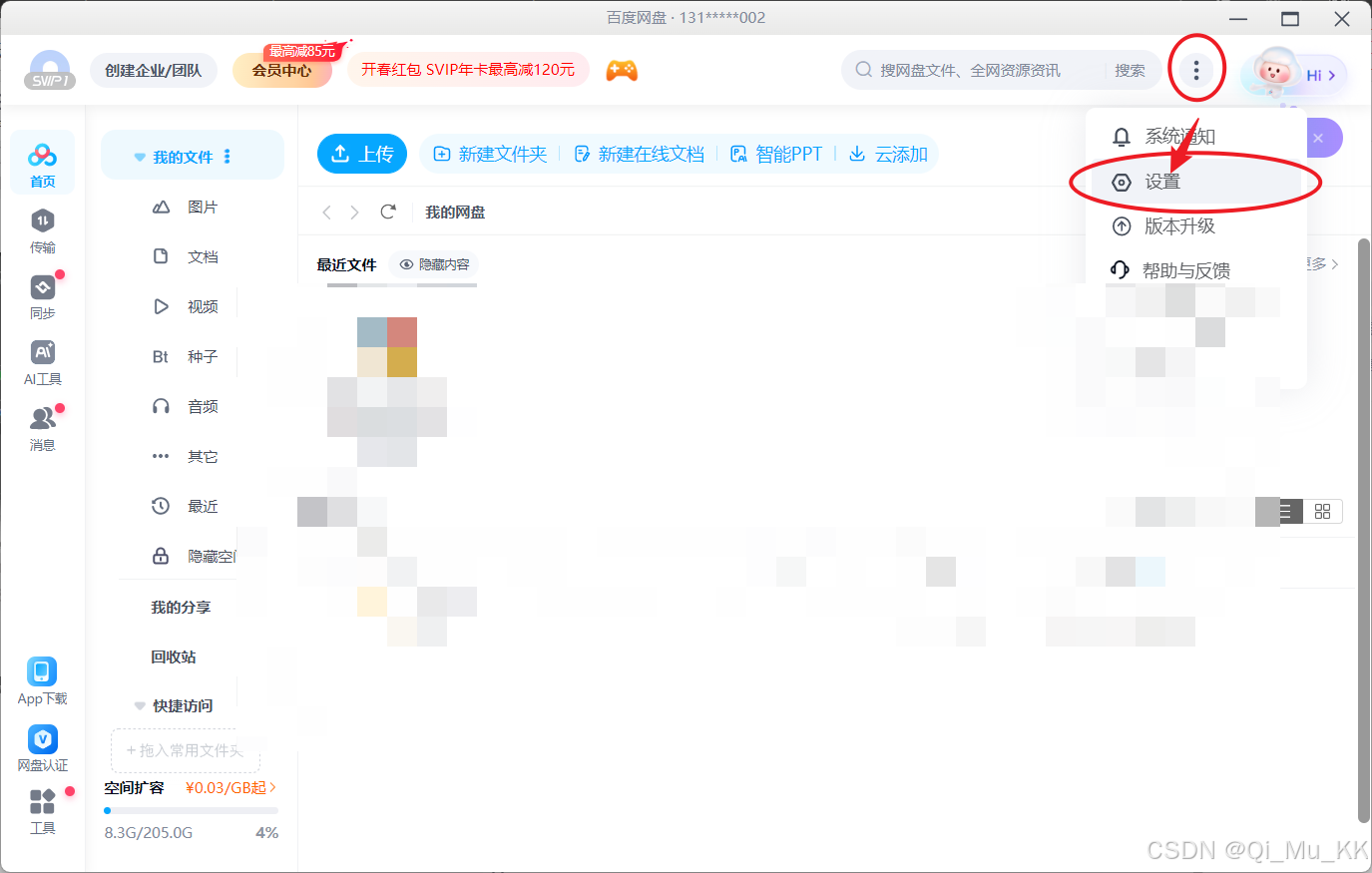
2. 找到传输设置,按图更改设置。
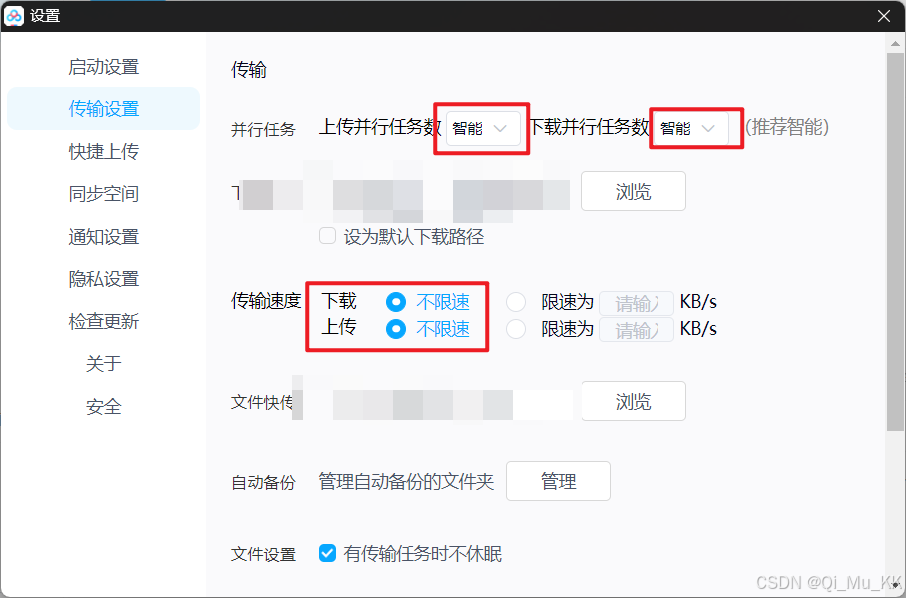
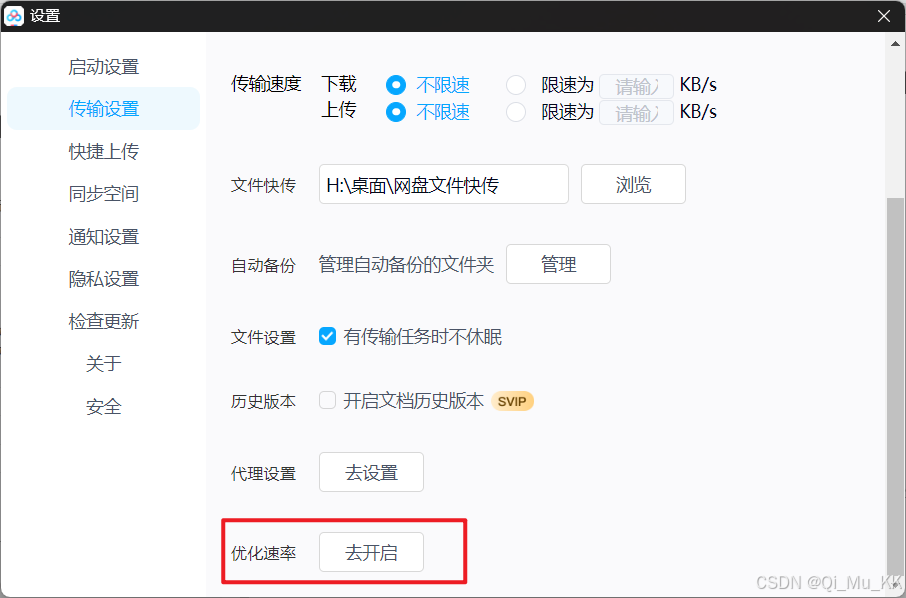
点击开启优化速率
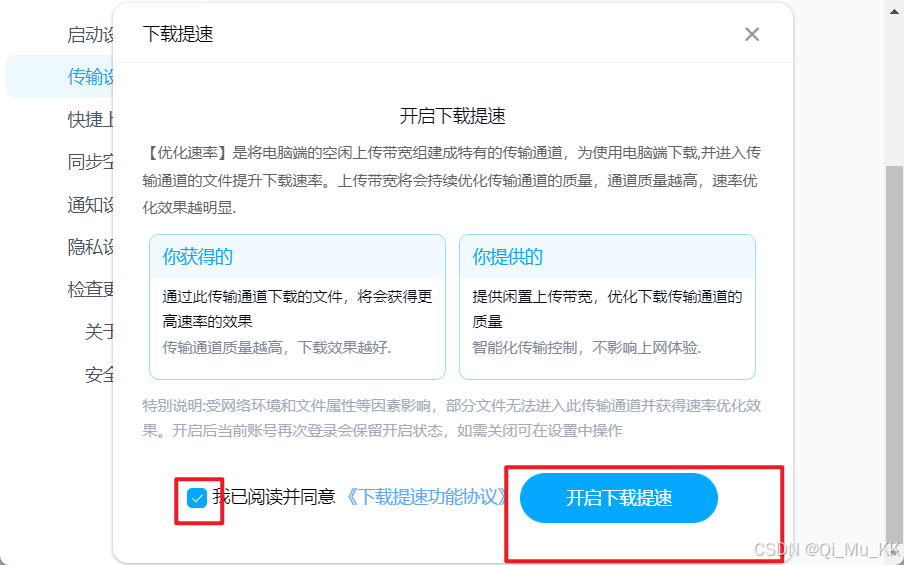
同意并点击开启。
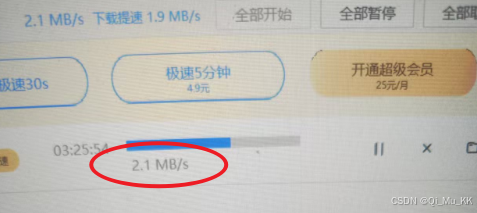
到这里就配置好了,可以看到速度有明显提升但根据各位观众老爷们的网速和设备不同,下载速度还是存在差异,并且下载速度不稳定,受网盘影响。
那么这时候就有人要问了,博主博主,这种操作还是吃网盘限速了,有没有下载既稳定免费又不限速的方法?Σ(`д′*ノ)ノ
有的,兄弟!有的!!这么简单免费还不限速的方法还有一个(/▽\)
接下来就是博主开头展示下载方法
方法二(免费不限速,适合所有文件下载)
受篇幅限制,请各位老爷们转战博主另一篇帖子:
超详细IDM直连获取百度网盘不限速下载 点击查看详情教程


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









