







早就想搞一下内存问题了!这次正趁着搞bigmemory内核,可以写一篇文章了。本文旨在记录,不包含细节,细节的话,google,百度均可,很多人已经写了不少了。我只是按照自己的理解记录一下内存的点点滴滴而已,没有一家之言,不讨论,不较真。
当时的机器是为了执行一个特定的任务,但是这种存储执行模型作为的一个最简单的核心,为后代的逐步复杂化奠定了基础。我的观点还是,一个概念或者其它什么东西,之所以复杂是因为它经得起复杂。罗马帝国始终脱离不了城邦格局,它经不起复杂,它崩溃了!

但是,这种模型有两个显而易见的缺点,第一,很难满足一个大内存需求的任务,第二,一分就是一个段,段必须处在一个连续的空间。
内存页面的概念被提出后,页就成了分配内存的最小单位,而MMU则成了为程序分配内存的服务管理机构,有了这个新机构,应用程序再也不用考虑物理内存的位置的大小以及偏移问题了。
虚拟内存的提出是革命性的,在以前,程序不得不维护自己段寄存器,以明确自己所需内存的位置,只要是有一个地址,就可以根据段寄存器知道它位于内存中的什么地方,也就是说,那个时候,程序是直接使用物理内存的。虚拟内存出现后,MMU接管了内存管理的一切,应用程序不必关心内存的位置和大小了。如果是32位系统,那么程序被承诺可以使用高达4G的内存,如果是64位系统,...至于自己使用的内存在什么位置,则不必关心,可用的4G内存只是许诺,等到需要的时候MMU自然会给你,如果没有空闲内存,自然会给你个说法。MMU作为一个仲裁和管理机构,前提是大家必须信任它!
如果说初期的直接独占使用物理内存是王政时代, 段式管理是贵族寡头时代的话,虚拟内存管理则真正到了民主时代,各项机构有条不紊运行。
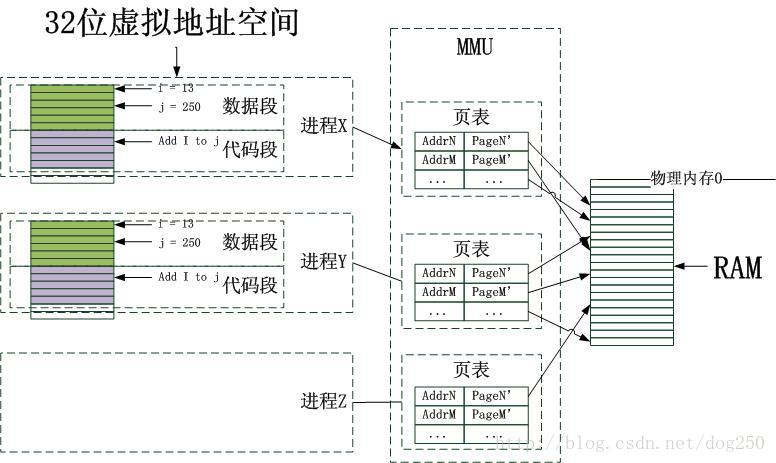
由于采用了MMU这个中间层,物理内存不再和程序直接打交道,则物理内存的形式就变得不再重要,它可以是内存条,也可以是磁盘,甚至可以是设备,只要MMU能给出合理的解释,并且按照应用程序访问内存的规则来访问这些实体并能给出正确的结果即可。这就使得文件映射,设备映射成了可能。如下图所示:
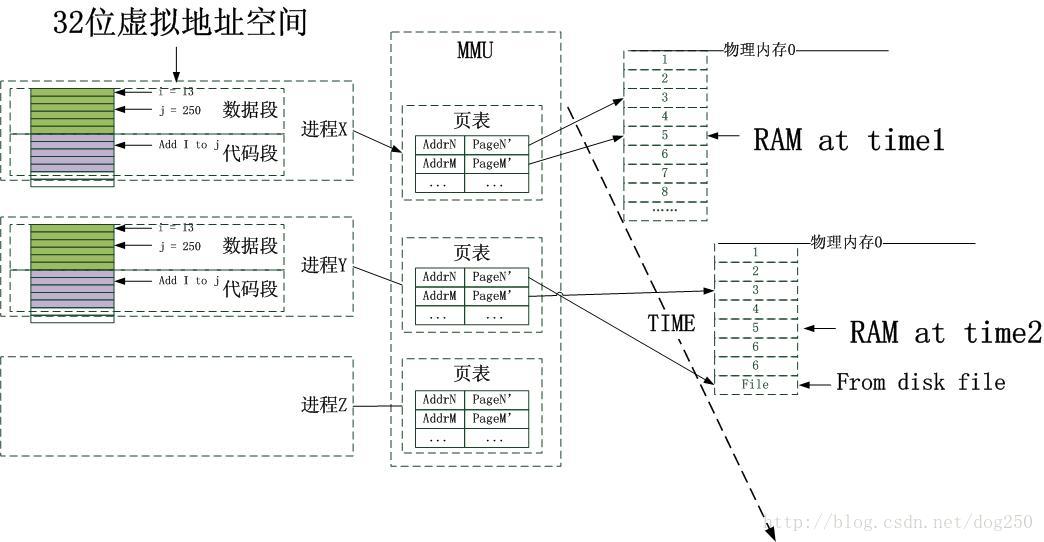
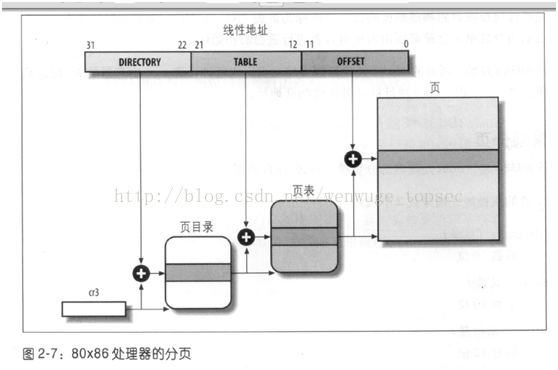
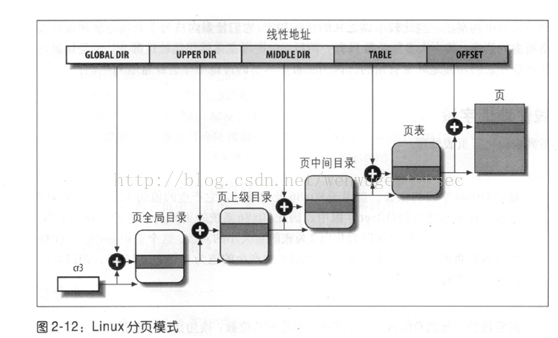
虽然说“从虚拟内存映射到物理内存通过查表可以实现”,但是具体的查表过程却非常复杂,并不是简单的一对一的映射这么实现的。实际的实现是通过一个多极页表的方式实现的。所谓的多级页表是将虚拟地址分为不同的部分,每一部分代表不同的索引。这样就可以按照内存的范围进行区域划分,更好的进行页表的管理。具体的方法和图示无须google,百度即可!
使用多级页表并不是为了减少内存使用,说实话,如果把所有的4G映射都建立页表项的话,采用两极页表还会浪费页目录表占用的4K空间,然而并不能如此考虑问题,内存使用分布是不遵循幂率的,因此你不必考虑黑天鹅事件。大部分情况下,不会建立太多的页表,即使建立1000个页表,它也会多数承载于连续的页目录项中,很多的页表是不需要分配内存的。主旨就是,将管理结构分级往前推,往前推,往前推!
本文最后会给出一个程序,让你眼见为实地明白页表到底占据多少空间以及内存的分布如何影响页表占据内存空间的大小。
事实上,整体的换入换出模型更加适合虚拟化,所谓的虚拟化指的是全部的,包括CPU在内的虚拟化。它不适合虚拟内存,既然CPU都是分时处理不同进程的,内存为何就不能分页面映射给不同的进程呢?
a.管理成本:是资源就要有效管理,而管理本身也是消耗资源的,它在各个系统上都有一个上限。
b.体系结构的兼容性考虑:如果说从一张白纸重新作画,那再简单不过了,然而现实并非如此,总线宽度为了兼容性并不能随意扩展。
c.实现成本:计算机上的任何概念都是一个有限集,更加明确的原则就是,它不要求100%的好,而是要求90%可用即可。
d.电梯效应:超高层的摩天大楼不可能建造,并不是因为底层承载不了上层的持续压力,而是如果建成了高层大厦,建得越高,电梯占据的空间就越大,达到阀值后,电梯的空间将超越使用空间。这是管理成本的另一层含义,只是更加严重些!
即使不能使物理内存无限大,也可以让它更大,PAE就是这个想法的产物。
到此为止,可能你还是不明白32位的系统如何去识别4G以上的内存。注意,MMU使用页表来定位页面的位置,只要页表项能填入一个大于32位的数字,就能寻址到4G以上的内存--因为32位可以寻址4G(why?...),加上硬件地址总线宽度能超越32位,那就能定位到大于4G的内存,定位到这个页面后,将其映射回32位的某个地址即可。如下图所示:
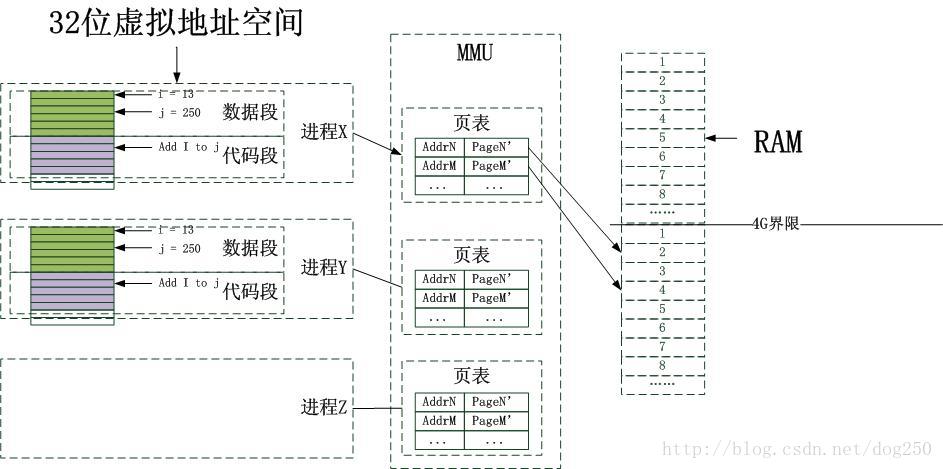
记住,物理内存仅仅就是一个资源的角色,在不考虑兼容性以及管理成本的情况下,当然越大越好,并非非要和虚拟地址空间一致。在32位系统中,进程的虚拟地址空间永远都是32位也就是4G的,但是这4G空间的地址却是可以映射到任意的物理地址空间,一切尽在MMU,说白了就是,第一,页表项的映射指示到了任意的物理页面,第二就是地址总线的宽度允许寻址到那个位置(否则,虽然从程序上讲不会出错,但是在地址总线上发射地址的时候会发生回绕!)。程序员可以照着书上的例子写出代码,但是没有什么书教你在哪些机器上这些代码可以得到你预期的结果!!
是时候说一下Linux了,对于实践者和怀疑论者以及书生乃至抑郁症患者抑或精神病而言,没有任何高谈阔论可以比得上一个实际的例子了。
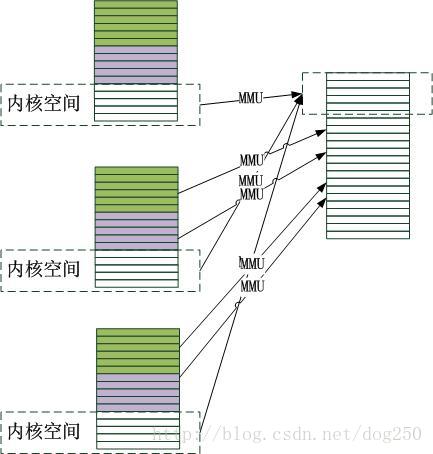
用户态可以有自己的映射,内核态的映射全部交给了内核本身!内核简化了,它可以用一种更加简单且高效的方式实现管理,那就是一一线性映射,也就是将一个连续的内核地址空间,映射到一块连续的物理地址空间,虽然最终的访存还是需要MMU,但是起码不需要做复杂的管理工作了。映射到哪块连续的物理地址空间好呢?当然是最初的空间好,因为内核的映射位置不能依赖物理地址空间的大小。
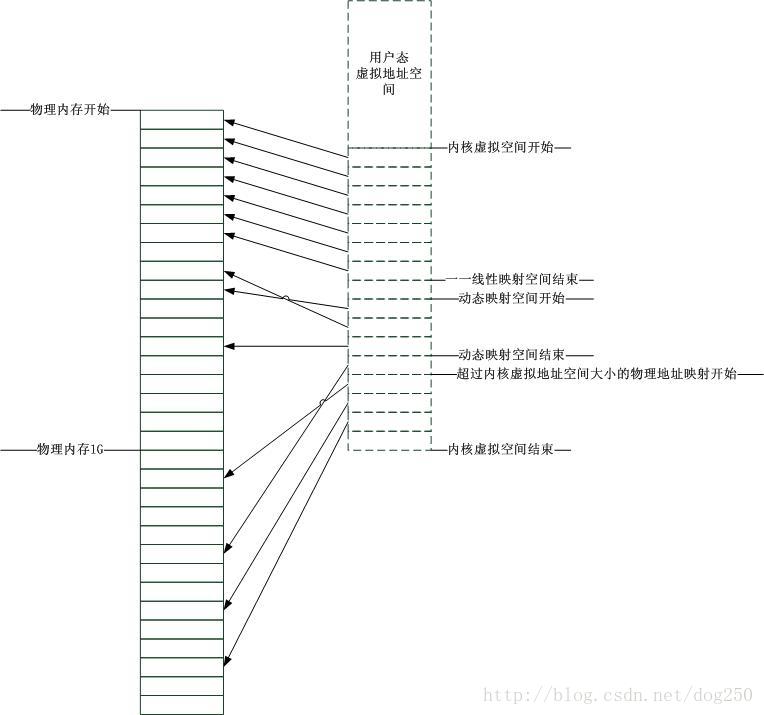
以上就是一一线性映射的由来!但是为了满足动态的内核态服务的内存需求,比如动态插拔的内核模块,比如用户系统调用的临时需求,内核的虚拟地址空间还要留下一部分用来映射这些动态的数据。最终内核态的虚拟地址空间的布局成了如下布局:
这样的布局本身没有什么问题,特别是如果你理解Windows的自映射以及内核分页机制之后,你就会发现Linux的方式是多么的原生态,多么的环保。然而这种方式有一个疑问-现如今还不能成为问题:
为了保持一一映射的关系,所有的一一映射的内存必须独占且常驻内存,和最原始的冯诺依曼机器实现那种方式一样,因此,Linux的一一映射方式真正回归了原生态,只是中间有一个MMU例行公事而已!
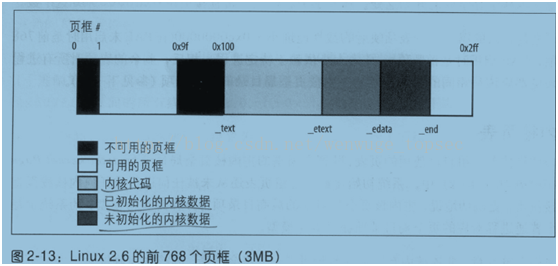
现在考虑PAE的模式!我讨厌《尼罗河上的惨案》中那个穿西服的家伙那种方式!如果启动了PAE,意味着系统中存在大量的内存页面,为了管理这些页面,Linux内核必须为这些页面建立结构体,即struct page。Linux系统是按照伙伴系统分配page的,伙伴系统要求事先必须存在page的索引,因此必须要考虑page结构体们占据的内存空间。作为基础管理数据结构,这些page结构都处在内核的一一映射地址空间,然而一一映射的地址空间大小是有限制的,即896M!按照一个page结构体32字节大小来计算的话,你算一下能允许多少page被索引,记住,896M不能全都用于page结构,内存管理只是Linux内核的一部分而已,另外还有大头戏,进程管理!结果就是在现行的Linux内存管理模式下,只能管理有限的page,因此你并不能安装64G的内存在Linux系统上。
但是,作为一个通用且前卫的系统,关键是Linus动不动就动粗口的情形下,Linux有自己的解决方案,其中不外乎以下两点:
a.使用大页面:一般而言,一个页面4K,这样为了索引大内存就需要大量的页面,但是如果一个页面4M或者2M的话,索引大量内存就不需要大量的页面了,页面数量减少了,页面管理结构所占据的内存空间也就减少了!
b.使用独立的4G/4G模式:虽然大页面可以缓解管理结构占据内存太大的问题,但是并不能解决!Linux支持一种4G/4G模式,即不再将所有进程的最上面1G的内核空间共享,而是每个进程的用户态独占4G虚拟地址空间,切换到内核态时,同时切换到另一个4G地址空间,即独立的4G的内核地址空间!内核态不再借用用户进程地址空间,而是独立出来一个4G空间来寻址,在X86上,意味着不管是系统调用,不管是中断还是异常,陷入内核时,都要切换CR3寄存器,这意味着你要付出一些代价!切换CR3的代价是昂贵的,它不光是save/restore的代价,更是取消了cache加速的代价!
执行前,查看 /proc/meminfo后,由于页表分配在高端内存,即896上的内存(我的系统2000M内存),其内容为:
HighTotal: 1628104 kB
HighFree: 1261560 kB
执行后,total数目为768,符合预期,因为上1G的内存属于内核空间,不能mmap。查看/proc/meminfo后,HIGH内存减小,减小多少自己算
HighTotal: 1628104 kB
HighFree: 1255360 kB
如果不用FIX参数,那么页表项同样也是建立那么多,在我测试下来,还多了很多,1024个页表项全部建立成功,但是,HIGH内存占据反而减少了:
HighTotal: 1628104 kB
HighFree: 1257344 kB
这说明内存分配的布局,也就是页表有与否,会影响管理成本!什么是High内存,是大于896M的所有物理内存!可用通过/proc/meminfo看出来!
实际上,很多技术都是基于概率的,都是追求90%的可用而不是100%的完美!为何大家不必为卫星残骸坠落地球而担心,因为地球上70%都是海洋,陆地上人类聚集的地点不足1%,所以砸中人的概率字计算吧。如果我被砸中了,算是我对较真的神诅咒的一种报应吧,但是并不绝对!
按照局部性原理,一个CPU在同一时刻只能处理有限区域的内存数据!时间比空间更重要,强劲的CPU要比64位的虚拟地址空间更加有用,虚拟地址空间并不是实际落实的物理地内存空间,效率和速度体现在落实的物理内存上!即使是物理内存的因素,安装比较大的物理内存更多的是在于减少换入换出开销,而不是为了满足同时访问大量内存的需求。即使有同时需要大量内存的程序,也可以通过并发处理,通过多核来将其平坦化!
我并不诋毁64位,只是觉得按照资源池的概念,你只需要在乎物理内存,而无需在乎虚拟内存!别提数据库,我讨厌数据库,因为它总是为自己占据大量磁盘需要很高的CPU处理能力而狂呼资源不够,但是实际上早期的ER模型并不适合现在的大数据处理!是数据库本身的问题,而不是处理资源不够!
与其64位,不如来个8核,已经有了8核,32位够了!
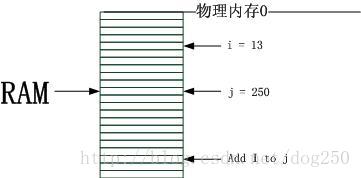
1.最简单的内存使用
最简单的模型是冯.诺依曼提出的原始模型,简单的把数据和指令存放在内存中,然后机器从内存中取出指令和数据进行计算,如下图所示:
当时的机器是为了执行一个特定的任务,但是这种存储执行模型作为的一个最简单的核心,为后代的逐步复杂化奠定了基础。我的观点还是,一个概念或者其它什么东西,之所以复杂是因为它经得起复杂。罗马帝国始终脱离不了城邦格局,它经不起复杂,它崩溃了!
2.分时系统内存模型
2.1.计划
一台机器执行一个任务,太浪费资源了,略过中间的挣扎,直接到了分时系统时代,一台机器可以执行多个任务了,如果切换机制足够好,这些任务可以满足低延迟需求。冯诺依曼机器的核心是处理器和内存,处理器沿时间轴推进,内存则空间平面上展开,分时系统在时间轴上分割了多个任务,它需要在空间平面上同样分割多个任务,于是内存变成了一种共享的资源,如何在多个任务之间分配这个单一的共享的内存资源成了后来技术发展的重轴戏。2.2.段式内存模型
段式内存模型将一个程序划分为不同的段,不同任务的不同段处在内存的不同段当中,如下图所示:
但是,这种模型有两个显而易见的缺点,第一,很难满足一个大内存需求的任务,第二,一分就是一个段,段必须处在一个连续的空间。
2.3.虚拟内存
一个任务所需要的内存大小以及位置不应该依赖其它任务的内存的大小和位置,并且内存的位置也不应该是永久性的,任务使用内存就应该和人们使用公共厕所一样。程序任务只管自己的计算逻辑,用到内存的时候,不必自己操心,应该有一个服务机构为其现场分配内存,分配多少算好呢,答案就是就可能少,按照基本单位分配,也就是说只分配程序现在用的那个内存,即便说马上就要用另一块内存,那也要等到时候再说,这样就做到了公平和高效!既满足了尽可能多的程序的内存需求,又不会浪费任何不会用到的内存。内存页面的概念被提出后,页就成了分配内存的最小单位,而MMU则成了为程序分配内存的服务管理机构,有了这个新机构,应用程序再也不用考虑物理内存的位置的大小以及偏移问题了。
虚拟内存的提出是革命性的,在以前,程序不得不维护自己段寄存器,以明确自己所需内存的位置,只要是有一个地址,就可以根据段寄存器知道它位于内存中的什么地方,也就是说,那个时候,程序是直接使用物理内存的。虚拟内存出现后,MMU接管了内存管理的一切,应用程序不必关心内存的位置和大小了。如果是32位系统,那么程序被承诺可以使用高达4G的内存,如果是64位系统,...至于自己使用的内存在什么位置,则不必关心,可用的4G内存只是许诺,等到需要的时候MMU自然会给你,如果没有空闲内存,自然会给你个说法。MMU作为一个仲裁和管理机构,前提是大家必须信任它!
如果说初期的直接独占使用物理内存是王政时代, 段式管理是贵族寡头时代的话,虚拟内存管理则真正到了民主时代,各项机构有条不紊运行。
2.4.页式内存模型
页式模型顾名思义就是以页面为基础进行内存管理,注意,最终的内存页面并不直接和程序打交道,它通过MMU和程序打交道。由于有了MMU这个中间层,它负责将一个程序的虚拟内存地址映射到实际的物理地址,怎么做到的呢?当然是通过一张表,即页表来查询的。
由于采用了MMU这个中间层,物理内存不再和程序直接打交道,则物理内存的形式就变得不再重要,它可以是内存条,也可以是磁盘,甚至可以是设备,只要MMU能给出合理的解释,并且按照应用程序访问内存的规则来访问这些实体并能给出正确的结果即可。这就使得文件映射,设备映射成了可能。如下图所示:
虽然说“从虚拟内存映射到物理内存通过查表可以实现”,但是具体的查表过程却非常复杂,并不是简单的一对一的映射这么实现的。实际的实现是通过一个多极页表的方式实现的。所谓的多级页表是将虚拟地址分为不同的部分,每一部分代表不同的索引。这样就可以按照内存的范围进行区域划分,更好的进行页表的管理。具体的方法和图示无须google,百度即可!
附:一些细节-为何采用多级页表
在实际的实现中,为何要使用多级页表而不是单级页表呢?这是从管理成本来考虑的。由于是一个表,那么它便有连续内存存储的需求,这样才好根据索引来快速定位。如果是单层页表,那么即使一个页面被分配,也需要建立整个页表,32位的情况下以4K页面为例,需要20位要寻址页面基地址,20位的话单级页表需要一下子建立4M大小的页表。使用多级页表并不是为了减少内存使用,说实话,如果把所有的4G映射都建立页表项的话,采用两极页表还会浪费页目录表占用的4K空间,然而并不能如此考虑问题,内存使用分布是不遵循幂率的,因此你不必考虑黑天鹅事件。大部分情况下,不会建立太多的页表,即使建立1000个页表,它也会多数承载于连续的页目录项中,很多的页表是不需要分配内存的。主旨就是,将管理结构分级往前推,往前推,往前推!
本文最后会给出一个程序,让你眼见为实地明白页表到底占据多少空间以及内存的分布如何影响页表占据内存空间的大小。
2.5.换入换出机制
有点懵了,怎么现在才开始说换入换出,是不是顺序弄乱了,不是说很早的UNIX时代就有换入换出了么?如今Linux还保留着swap进程(其实是内核线程,因为总有人较真,说什么内核线程不能叫做进程,看书看多了)这个名称。非也,不是弄错了,而是我想基于交换机制来谈一下虚拟内存的意义,并不是讲换入换出机制本身。2.5.1.整体换入换出
这是最实际不过的了,分时系统将一个进程拉到前台来运行的时候,将该进程的映像从磁盘换到内存,同时将正在执行的进程换出到磁盘。虽然简单,但是却没有后续的可扩展性。这其实是基于最初的内存模型修正的,而丝毫没有用到虚拟内存的优势。虚拟内存不关心进程,不关心内存页面的位置,切断了物理内存和进程的关系,只关注页面本身,页面的内容可以来自计算,来自文件,来自设备,...事实上,整体的换入换出模型更加适合虚拟化,所谓的虚拟化指的是全部的,包括CPU在内的虚拟化。它不适合虚拟内存,既然CPU都是分时处理不同进程的,内存为何就不能分页面映射给不同的进程呢?
2.5.2.页面换入换出
由整体换入换出的弊端引起的直接结果就是页面的换入换出。一个页面就是一个页面,它不和进程进行关联,只和页表项进行关联,这是虚拟内存管理高效性和公平性之根本。单独页面的管理以及基于页面的换入换出机制,虚拟内存之根本!3.物理内存的角色
在使用虚拟内存之后,物理内存的角色已经不再像早期那样重要,它退化成了一个资源的角色,作为一种资源,原则上它可以是无限大的,而且越大越好,但是受制于以下的因素:a.管理成本:是资源就要有效管理,而管理本身也是消耗资源的,它在各个系统上都有一个上限。
b.体系结构的兼容性考虑:如果说从一张白纸重新作画,那再简单不过了,然而现实并非如此,总线宽度为了兼容性并不能随意扩展。
c.实现成本:计算机上的任何概念都是一个有限集,更加明确的原则就是,它不要求100%的好,而是要求90%可用即可。
d.电梯效应:超高层的摩天大楼不可能建造,并不是因为底层承载不了上层的持续压力,而是如果建成了高层大厦,建得越高,电梯占据的空间就越大,达到阀值后,电梯的空间将超越使用空间。这是管理成本的另一层含义,只是更加严重些!
即使不能使物理内存无限大,也可以让它更大,PAE就是这个想法的产物。
4.映射到物理内存
物理内存并非一定要和虚拟内存的大小一致,如果是这样的话,虚拟内存的意义是不明显的。以32位系统为例,N个进程均被许诺有4G内存,然而它们共享4G物理内存,谁也不能同时用尽所有内存,然而如果真的有这样需求的进程怎么办?那只能频繁的换入换出了,虽然也是可以实现,但是更好的做法就是安装N*4G的内存,可是这样的话好像又退回到了段式管理,只是内存的实际位置不再确定,只是将基于段的管理改成了粒度更细的页式管理而已。由于N的不确定性以及内存使用的不确定性,没有必要安装那么大的内存,最终的方案就是安装稍微大一些的内存,比如16G,32G,64G的内存,机器就足以飞起来了!到此为止,可能你还是不明白32位的系统如何去识别4G以上的内存。注意,MMU使用页表来定位页面的位置,只要页表项能填入一个大于32位的数字,就能寻址到4G以上的内存--因为32位可以寻址4G(why?...),加上硬件地址总线宽度能超越32位,那就能定位到大于4G的内存,定位到这个页面后,将其映射回32位的某个地址即可。如下图所示:
记住,物理内存仅仅就是一个资源的角色,在不考虑兼容性以及管理成本的情况下,当然越大越好,并非非要和虚拟地址空间一致。在32位系统中,进程的虚拟地址空间永远都是32位也就是4G的,但是这4G空间的地址却是可以映射到任意的物理地址空间,一切尽在MMU,说白了就是,第一,页表项的映射指示到了任意的物理页面,第二就是地址总线的宽度允许寻址到那个位置(否则,虽然从程序上讲不会出错,但是在地址总线上发射地址的时候会发生回绕!)。程序员可以照着书上的例子写出代码,但是没有什么书教你在哪些机器上这些代码可以得到你预期的结果!!
5.Linux上的实现与PAE/PSE相关
上面说的加大物理内存供应的说法,其实有一种实现那就是PAE。PAE是什么,google吧,如果怕google动不动就RESET,那么百度也能得到结果!PAE允许你寻址36位的物理地址空间!也就是说允许你安装64G的内存。按照物理内存只是资源池的概念,所有的32位进程共享所有安装的物理内存,每一个进程寻址32位虚拟地址,通过MMU实际可以访问36位的物理地址。是时候说一下Linux了,对于实践者和怀疑论者以及书生乃至抑郁症患者抑或精神病而言,没有任何高谈阔论可以比得上一个实际的例子了。
5.1.Linux的地址映射方式
Linux采用了一种极其简单的地址映射方式,那就是将内核空间的代码以及数据和实际的用户进程隔离开来,怎么个简单法呢?很简单,那就是将进程的地址空间划分为用户态的3G和内核态的1G,所谓的用户态就是非特权态,对于那些爱看书的优秀学生而言,他们熟悉的语言是第3特权护环,不管怎么说,反正就是进程可见的数据和代码的地址空间!用户态的地址空间映射,内核不过问,而内核态的映射,所有的用户态共享,作为一个管理机构,它是唯一的,如下图所示:
用户态可以有自己的映射,内核态的映射全部交给了内核本身!内核简化了,它可以用一种更加简单且高效的方式实现管理,那就是一一线性映射,也就是将一个连续的内核地址空间,映射到一块连续的物理地址空间,虽然最终的访存还是需要MMU,但是起码不需要做复杂的管理工作了。映射到哪块连续的物理地址空间好呢?当然是最初的空间好,因为内核的映射位置不能依赖物理地址空间的大小。
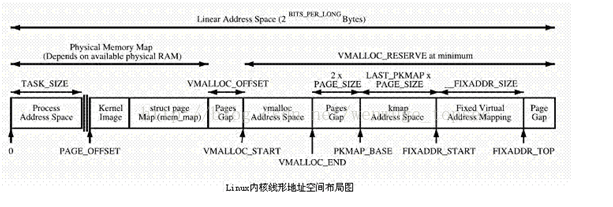
以上就是一一线性映射的由来!但是为了满足动态的内核态服务的内存需求,比如动态插拔的内核模块,比如用户系统调用的临时需求,内核的虚拟地址空间还要留下一部分用来映射这些动态的数据。最终内核态的虚拟地址空间的布局成了如下布局:
这样的布局本身没有什么问题,特别是如果你理解Windows的自映射以及内核分页机制之后,你就会发现Linux的方式是多么的原生态,多么的环保。然而这种方式有一个疑问-现如今还不能成为问题:
为了保持一一映射的关系,所有的一一映射的内存必须独占且常驻内存,和最原始的冯诺依曼机器实现那种方式一样,因此,Linux的一一映射方式真正回归了原生态,只是中间有一个MMU例行公事而已!
现在考虑PAE的模式!我讨厌《尼罗河上的惨案》中那个穿西服的家伙那种方式!如果启动了PAE,意味着系统中存在大量的内存页面,为了管理这些页面,Linux内核必须为这些页面建立结构体,即struct page。Linux系统是按照伙伴系统分配page的,伙伴系统要求事先必须存在page的索引,因此必须要考虑page结构体们占据的内存空间。作为基础管理数据结构,这些page结构都处在内核的一一映射地址空间,然而一一映射的地址空间大小是有限制的,即896M!按照一个page结构体32字节大小来计算的话,你算一下能允许多少page被索引,记住,896M不能全都用于page结构,内存管理只是Linux内核的一部分而已,另外还有大头戏,进程管理!结果就是在现行的Linux内存管理模式下,只能管理有限的page,因此你并不能安装64G的内存在Linux系统上。
但是,作为一个通用且前卫的系统,关键是Linus动不动就动粗口的情形下,Linux有自己的解决方案,其中不外乎以下两点:
a.使用大页面:一般而言,一个页面4K,这样为了索引大内存就需要大量的页面,但是如果一个页面4M或者2M的话,索引大量内存就不需要大量的页面了,页面数量减少了,页面管理结构所占据的内存空间也就减少了!
b.使用独立的4G/4G模式:虽然大页面可以缓解管理结构占据内存太大的问题,但是并不能解决!Linux支持一种4G/4G模式,即不再将所有进程的最上面1G的内核空间共享,而是每个进程的用户态独占4G虚拟地址空间,切换到内核态时,同时切换到另一个4G地址空间,即独立的4G的内核地址空间!内核态不再借用用户进程地址空间,而是独立出来一个4G空间来寻址,在X86上,意味着不管是系统调用,不管是中断还是异常,陷入内核时,都要切换CR3寄存器,这意味着你要付出一些代价!切换CR3的代价是昂贵的,它不光是save/restore的代价,更是取消了cache加速的代价!
5.2.Linux内核的管理成本
说白了,Linux内核的管理成本太昂贵,很多的管理数据结构都要占据内核的一一线性映射的896M的空间!虽然进程结构task_struct结构体不大,但是896M除以sizeof(struct task_struct)的话,也不是一个很大的数,再加上CR3指向的页目录页表等,896M真的容不下什么太多的内容!最根本的限制那就是这种机制限制了系统同时运行进程的数量!但是,Linux内核的这种原始内存映射的优点也显而易见,那就是社区大牛们总是可以设计出一些精巧的数据结构,往往在恶劣环境下写出的代码,一定是高效的代码,这同时也是微软的信条!5.3.看一段代码展示管理成本
是时候展示一个简单的代码了。该代码让你看一下管理成本,虽然很简单,但是可以让你看到一个进程本身虽然不占据什么内存空间,但是光其页表就占据大量的内存。在展示代码之前,先看一个Linux内核的编译宏HIGHPTE,该宏决定你能不能将页表这种吃内存的管理结构分配在高端内存,即大于896M的物理内存,也就是说如果你启用了该宏,就不必在一一线性映射区域分配页表!我的系统启用了该宏,意味着页表都尽量分配在高端内存。以下是代码:- #include <stdio.h>
- #include <stdlib.h>
- #include <sys/mman.h>
- int main(int argc, char **argv)
- {
- int i = 0, total = 0;
- for (i = 0; i < 1024; i ++) {
- int j = 0;
- for (j = 0; j < 1024; j++) {
- //保证每一个页表起码有一个页面被分配,这样是为了填充满整个页目录
- //所以要用FIX参数,使用LOCK参数目的在于使其页表项中有内容,否则就是缺页中断按需分配了
- char *p = (char *)mmap(i*1024*4096+j*4096, 16, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_ANONYMOUS|MAP_FIXED|MAP_LOCKED, -1, 0);
- //注释掉的是:随机分配页面,不必填充,每一个页目录项
- //char *p = (char *)mmap(NULL, 16, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_ANONYMOUS|MAP_LOCKED, -1, 0);
- if((int)p != -1) {
- total ++;
- *p = 13;
- printf("addr:%p %d %d\n", p, i, j);
- break;
- }
- }
- }
- printf("total:%d\n", total);
- sleep(10000);
- }
执行前,查看 /proc/meminfo后,由于页表分配在高端内存,即896上的内存(我的系统2000M内存),其内容为:
HighTotal: 1628104 kB
HighFree: 1261560 kB
执行后,total数目为768,符合预期,因为上1G的内存属于内核空间,不能mmap。查看/proc/meminfo后,HIGH内存减小,减小多少自己算
HighTotal: 1628104 kB
HighFree: 1255360 kB
如果不用FIX参数,那么页表项同样也是建立那么多,在我测试下来,还多了很多,1024个页表项全部建立成功,但是,HIGH内存占据反而减少了:
HighTotal: 1628104 kB
HighFree: 1257344 kB
这说明内存分配的布局,也就是页表有与否,会影响管理成本!什么是High内存,是大于896M的所有物理内存!可用通过/proc/meminfo看出来!
6.IT技术并不绝对
到底安装多少物理内存算多,可以算出来吗?IT技术算精确技术吗?我不觉得喜欢较真的人能彻底理解TCP。卫星技术要比IT技术高深TMD的多了,怎么没有人能预测出欧洲卫星残骸坠落地球的具体地点,追究TCP重传具体时间具体算法的人可能要彻夜计算卫星残骸坠落地点了,由于精神高度紧张,猝死的可能性比猜中50%的可能性更高!实际上,很多技术都是基于概率的,都是追求90%的可用而不是100%的完美!为何大家不必为卫星残骸坠落地球而担心,因为地球上70%都是海洋,陆地上人类聚集的地点不足1%,所以砸中人的概率字计算吧。如果我被砸中了,算是我对较真的神诅咒的一种报应吧,但是并不绝对!
7.64位,TMD64位!
曾经,大家不约而同地使用64位系统,实际上没有谁的系统可以用到大内存,就算吃内存的游戏,32位也已经足够,关键的是能申请到物理内存。只要物理内存大即可,虚拟内存有谁会用到那么大呢?你更多的受益于多核而不是64位。我们对时间的感觉要比对空间的感觉敏感得多。按照局部性原理,一个CPU在同一时刻只能处理有限区域的内存数据!时间比空间更重要,强劲的CPU要比64位的虚拟地址空间更加有用,虚拟地址空间并不是实际落实的物理地内存空间,效率和速度体现在落实的物理内存上!即使是物理内存的因素,安装比较大的物理内存更多的是在于减少换入换出开销,而不是为了满足同时访问大量内存的需求。即使有同时需要大量内存的程序,也可以通过并发处理,通过多核来将其平坦化!
我并不诋毁64位,只是觉得按照资源池的概念,你只需要在乎物理内存,而无需在乎虚拟内存!别提数据库,我讨厌数据库,因为它总是为自己占据大量磁盘需要很高的CPU处理能力而狂呼资源不够,但是实际上早期的ER模型并不适合现在的大数据处理!是数据库本身的问题,而不是处理资源不够!
与其64位,不如来个8核,已经有了8核,32位够了!
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









