







1. 创建表,并插入数据
1.1. 创建表employee
CREATE TABLE [dbo].[Employee] (
EmployeeNo INT IDENTITY (1, 1) PRIMARY KEY,
EmployeeName NVARCHAR (50) NULL
);
1.2. 插入4000000条模拟数据
/*INSERT Employee DEFAULT VALUES;
UPDATE Employee set EmployeeName = 'Employee ' + CONVERT(VARCHAR, EmployeeNo)
*/
SET IDENTITY_INSERT Employee ON;
DECLARE @COUNT INT;
SET @COUNT = 1;
WHILE @COUNT <= 4000000
BEGIN
INSERT INTO Employee (EmployeeNo, EmployeeName)
VALUES
(
@COUNT,
'Employee ' + CONVERT (VARCHAR, @COUNT)
)
SET @COUNT =@COUNT + 1
END
SET IDENTITY_INSERT Employee OFF;2.创建文件组,并添加数据库文件
mdf ,*ldf,ndf 。其中mdf是 primary datafile(主要数据文件)的缩写,ndf是Secondary data files(次要数据文件)的缩写。一个数据库必须有且只有一个主要数据文件,可以有零个或多个次要数据文件。ldf是log data file(日志文件)的缩写,其记录用户对数据库的操作,一个SQL Server数据库至少要有一个日志文件。
来自 http://blog.163.com/bright9880@126/blog/static/707162532010114101950417/
/*创建文件组*/
ALTER DATABASE study ADD FILEGROUP [db1_fg_00];
--创建一个文件组;
USE study;
ALTER DATABASE study ADD FILE(
name= N'byoul',
filename= N'D:\DevSoft\sqlser\MSSQL12.MSSQLSERVER\MSSQL\DATA\byoul.ndf',
SIZE= 5MB,
maxsize=100mb,
filegrowth=5MB
)--size 为文件的初始大小,maxsize为文件的最大大小,filegrouwth自动增量大小
TO filegroup[PRIMARY];
ALTER DATABASE studyADD FILE(
name= N'byou2',
filename= N'D:\DevSoft\sqlser\MSSQL12.MSSQLSERVER\MSSQL\DATA\byou2.ndf',
SIZE= 5MB,
maxsize=100mb,
filegrowth=5MB
)--size 为文件的初始大小,maxsize为文件的最大大小,filegrouwth自动增量大小
TO filegroup[PRIMARY];
ALTER DATABASE studyADD FILE(
name= N'byou3',
filename= N'D:\DevSoft\sqlser\MSSQL12.MSSQLSERVER\MSSQL\DATA\byou3.ndf',
SIZE= 5MB,
maxsize=100mb,
filegrowth=5MB
)--size 为文件的初始大小,maxsize为文件的最大大小,filegrouwth自动增量大小
TO filegroup[PRIMARY];3. 创建分区函数
依据某个表的int列来创建分区函数:
create partition functionMyPF1(int)
range left --默认是left,所以可以省略left
for values(500000,1000000,1500000)很明显,这个分区函数创建了4个分区,因为此时n=3,所以分区总数是n+1=4。而那个int分区依据列表明将要分区的那个表里面一定有一列是int类型,是分区依据列。当然也可以依据date等其他数据类型的列
使用left,各个分区的取值范围
| 分区 | 取值范围 |
|---|---|
| 1 | (负无穷,500000] |
| 2 | [500001,1000000] |
| 3 | [1000001,1500000] |
| 4 | [1500001,正无穷) |
使用 right
| 分区 | 取值范围 |
|---|---|
| 1 | (负无穷,499999] |
| 2 | [500000,999999] |
| 3 | [1000000,1499999] |
| 4 | [1500000,正无穷) |
而在本例中,我们创建分区函数如下:
CREATE PARTITION FUNCTION[EmpFunction] (INT)ASRANGE RIGHT FOR
VALUES
(
N'1000000',
N'2000000',
N'3000000'
);4. 创建分区方案
对表和索引进行分区的第二步是创建分区方案。分区方案定义了一个特定的分区函数将使用的物理存储结构(其实就是文件组),或者说是分区方案将分区函数生成的分区映射到我们定义的一组文件组。所以分区方案解决的是Where的问题,即表的各个分区在哪里存储的问题。分区方案的创建语法如下:
CREATEPARTITION SCHEME partition_scheme_name ASPARTITION
partition_function_name [ ALL ]TO ( { file_group_name | [ PRIMARY ] }
[ ,…n ] ) [ ; ]
分区方案语法的相关解释:
1. 创建分区方案时,根据分区函数的参数,定义映射表分区的文件组。必须指定足够的文件组来容纳分区数。可以指定所有分区映射到不同文件组、某些分区映射到单个文件组或所有分区映射到单个文件组。如果您希望在以后添加更多分区,还可以指定其他“未分配的”文件组。在这种情况下,SQL Server用 NEXT USED属性标记其中一个文件组。这意味着该文件组将包含下一个添加的分区。一个分区方案仅可以使用一个分区函数。但是,一个分区函数可以参与多个分区方案。
2. partition_scheme_name是分区方案的名称。分区方案名称在数据库中必须是唯一的,并且符合标识符规则。
3. partition_function_name是使用当前分区方案的分区函数的名称。分区函数所创建的分区将映射到在分区方案中指定的文件组。partition_function_name必须已经存在于数据库中。
4. ALL指定所有分区都映射到在 file_group_name中提供的同一个文件组,或映射到主文件组(如果指定了[PRIMARY])。如果指定了 ALL,则只能指定一个 file_group_name。
5. file_group_name | [ PRIMARY ] [ ,…n]代表n个文件组。和分区函数中的各个分区对应。文件组必须已经存在于数据库中。如果指定了 [PRIMARY],则分区将存储于主文件组中。如果指定了 ALL,则只能指定一个 file_group_name。分区分配到文件组的顺序是从分区 1开始,按文件组在[,…n]中列出的顺序进行分配。在 [,…n]中,可以多次指定同一个文件组。如果 n不足以拥有在分区函数中指定的分区数,则 CREATE PARTITION SCHEME将失败,并返回错误。
6. 如果分区函数生成的分区数少于创建分区方案时提供的文件组数,则分区方案中第一个未分配的文件组将被标记为 NEXT USED,并且出现显示命名 NEXT USED文件组的信息。如果指定了 ALL,则单独的文件组将为该分区函数保持它的NEXT USED属性。如果在 ALTER PARTITION FUNCTION语句中创建了一个分区,则NEXT USED文件组将再接收一个分区。若要再创建一个未分配的文件组来拥有新的分区,请使用 ALTER PARTITION SCHEME。
来自 http://www.cnblogs.com/dongpo888/archive/2012/02/16/2355028.html
此处的建立单文件组的分区方案:
CREATE PARTITION SCHEME[FunScheme]ASPARTITION[EmpFunction]TO(
[PRIMARY],
[PRIMARY],
[PRIMARY],
[PRIMARY]
);
/* primary为sqlserver的默认文件组*/5. 对表进行分区
5.1. 删除原主键
删除原来的主键约束
declare @pkname varchar(1000)
SELECT @pkname= name
FROM
sysobjects
WHERE
xtype='pk'
ANDobject_name(parent_obj) ='Employee'EXEC(
'alter table Employee drop constraint '+@pkname
);5.2. 采用分区方案,对表进行分区
ALTER TABLE[dbo].[Employee]ADD PRIMARY KEYCLUSTERED ([EmployeeNo]ASC)WITH(
PAD_INDEX=OFF,
STATISTICS_NORECOMPUTE=OFF,
SORT_IN_TEMPDB=OFF,
IGNORE_DUP_KEY=OFF,
ONLINE=OFF,
ALLOW_ROW_LOCKS=ON,
ALLOW_PAGE_LOCKS=ON
)ON[FunScheme] ([EmployeeNo]);6. 查看结果
6.1. 查看表信息
SELECT * FROM sys.partitions AS p
JOIN sys.tables AS t ON p.object_id = t.object_id
WHERE
p.partition_id IS NOT NULL
AND t.name = ‘Employee’;
6.2. 查看表信息
SELECT
$PARTITION.EmpFunction (EmployeeNo) AS 分区编号,
COUNT (EmployeeNo) AS 记录数
FROM
Employee
GROUP BY
$PARTITION.EmpFunction (EmployeeNo);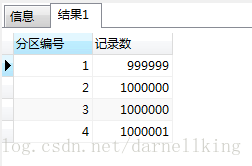
6.3. 查看数据存放的文件
SELECT
ps.name AS PSName,
dds.destination_id AS PartitionNumber,
fg.name AS FileGroupName,
fg.name,
t.name,
f.name AS filename
FROM
(
(
(
sys.tables AS t
INNER JOIN sys.indexes AS i ON (t.object_id = i.object_id)
)
INNER JOIN sys.partition_schemes AS ps ON (
i.data_space_id = ps.data_space_id
)
)
INNER JOIN sys.destination_data_spaces AS dds ON (
ps.data_space_id = dds.partition_scheme_id
)
)
INNER JOIN sys.filegroups AS fg ON dds.data_space_id = fg.data_space_id
INNER JOIN sys.database_files f ON f.data_space_id = fg.data_space_id
WHERE
t.name = 'employee'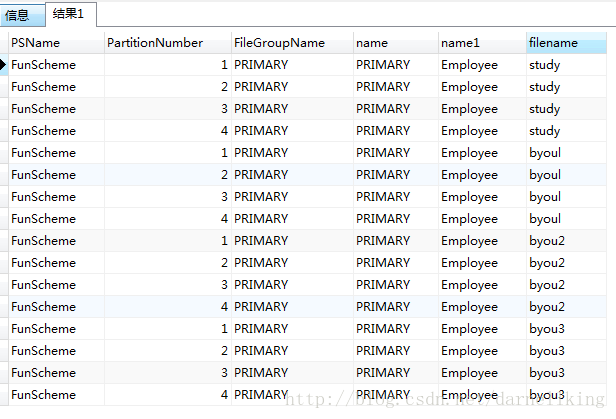
7. 将分区表更改为普通表
7.1. 删除分区
ALTER PARTITION FUNCTION EmpFunction () MERGE RANGE (N'1000000');
ALTER PARTITION FUNCTION EmpFunction () MERGE RANGE (N'2000000');
ALTER PARTITION FUNCTION EmpFunction () MERGE RANGE (N'3000000');7.2. 删除主键
DECLARE
@pkname VARCHAR (1000)
SELECT
@pkname = name
FROM
sysobjects
WHERE
xtype = 'pk'
AND object_name(parent_obj) = 'Employee'
EXEC (
'alter table Employee drop constraint ' +@pkname
);7.3. 重建索引
如果不对主键索引进行重建,数据库里面记录的还是分区表
CREATE CLUSTERED INDEX PK_Employee ON Employee ([EmployeeNo]) ON [PRIMARY];将分区表还原为普通表到此就已经结束。
7.4. 删除分区方案,截止删除分区函数
DROP PARTITION SCHEME [FunScheme];
DROP PARTITION FUNCTION [EmpFunction];7.5. 删除次数据库文件
/清空ndf里面的数据,执行这一步之前一定要确保数据已备份/
USE master;
/*清空ndf里面的数据,执行这一步之前一定要确保数据已备份*/
DBCC SHRINKFILE (byoul, EMPTYFILE);
ALTER DATABASE [study] REMOVE FILE [byoul];
/*清空ndf里面的数据,执行这一步之前一定要确保数据已备份*/
DBCC SHRINKFILE (byou2, EMPTYFILE);
ALTER DATABASE [study] REMOVE FILE [byou2];
/*清空ndf里面的数据,执行这一步之前一定要确保数据已备份*/
DBCC SHRINKFILE (byou3, EMPTYFILE);
ALTER DATABASE [study] REMOVE FILE [byou3];














 128
128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









