






基于热成像的巡检及AidLux工程方案
目录
项目简介
检测、分析输电线路中的绝缘子串,从而判断其工作状态是否正常。
输入图像为红外相机拍摄得到的热成像图:

项目方案
项目使用R-RetinaNet检测电力部件,可以得到带旋转角的目标检测框
项目代码可从AidLux微信公众号获取
部署代码:https://github.com/darwintk/AidLux_2304_electric_power/tree/main/AidLux_Deploy
模型文件: 百度网盘链接:百度网盘 请输入提取码 提取码:zxoo
作业要求
-
使用工具脚本完成pt模型至tflite模型的转换 (完成)
-
综合编写读取手机后置摄像头,进行绝缘子串芯片处理的整体代码,进行推理实现(报错)
电脑运行和模型转换环境配置
建议使用Linux系统,windows系统在编译部分相当复杂
编译环境
cd utils
sh make.sh命令行输出
安装swig(需要sudo),polyiou编译
sudo apt-get install swig
cd ./dataset/DOTADOTA_devkit
swig -c++ -python polyiou.i
python setup.py build_ext --inplace命令行输出:

ONNX模型转换与验证
为将pt模型转换为tflite,需先将pt转onnx,再由onnx转tflite
转换为ONNX模型
修改export_onnx.py的一些参数,保证程序读取到路径:
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Hyperparams')
parser.add_argument('--backbone', type=str, default='res50')
parser.add_argument('--hyp', type=str, default='hyp.py', help='hyper-parameter path')
parser.add_argument('--dataset_yaml', type=str, default='./datasets/dota_dataset.yaml', help='hyper-parameter path') # 设定数据集超参
parser.add_argument('--weight', type=str, default='./weights/r-retinanet-statedict.pt') # 导入模型
export(parser.parse_args())运行python export_onnx.py
一开始执行代码报错TypeError: load() missing 1 required positional argument: 'Loader',将pyyaml的版本降到5.4.1后再次运行,问题解决
模型转换成功,可在weights文件夹看到转换好的r-retinanet-statedict.onnx
验证ONNX模型
修改demo_onnx.py中的参数,让程序读取到转换后的模型和待验证图像
if __name__ == '__main__':
onnx_model = './weights/r-retinanet-statedict.onnx'
image_path = '../AidLux_Deploy/samples/000001.jpg'python demo_onnx.py验证结果,得到onnx的预测结果: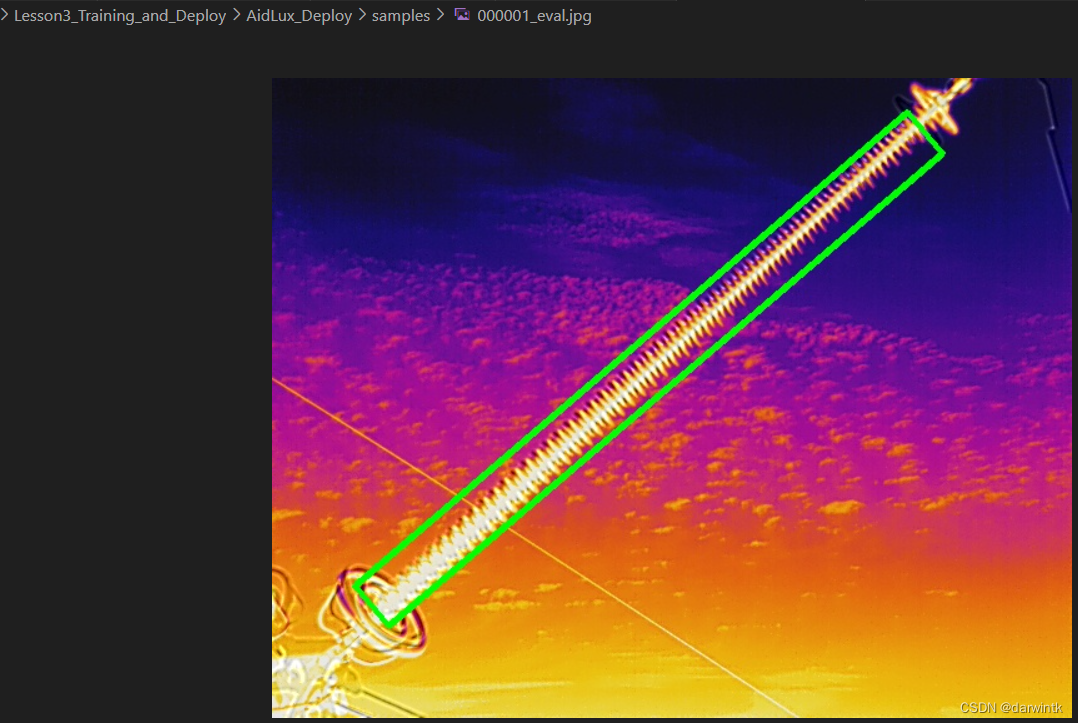
结果无误,可继续转换为tflite模型
导出tflite模型
这里使用了onnx2tflite来将onnx模型转为tflite模型,onnx2tflite项目可以自动将NCWH格式的通道变换为tensorflow的NWHC格式,比之前用过的onnx_rf要方便。
环境准备
在git上面获取onnx2tflite的代码:
git clone https://github.com/MPolaris/onnx2tflite.git
cd onnx2tflite在onnx2tflite项目中新建export_tflite.py
import os
import sys
from converter import onnx_converter
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
def onnx2tflite(onnx_path):
onnx_converter(
onnx_model_path = onnx_path,
need_simplify = False,
output_path = os.path.dirname(onnx_path),
target_formats = ['tflite'],
weight_quant = False,
int8_model = False,
int8_mean = None,
int8_std = None,
image_root = None
)
if __name__ == "__main__":
onnx2tflite("/your/path/to/Lesson3_Training_and_Deploy/R-RetinaNet-v5.0/weights/r-retinanet-statedict.onnx")保存运行python export_tflite.py,得到转换后的模型r-retinanet-statedict.tflite,与onnx模型在同一目录下
tflite模型验证
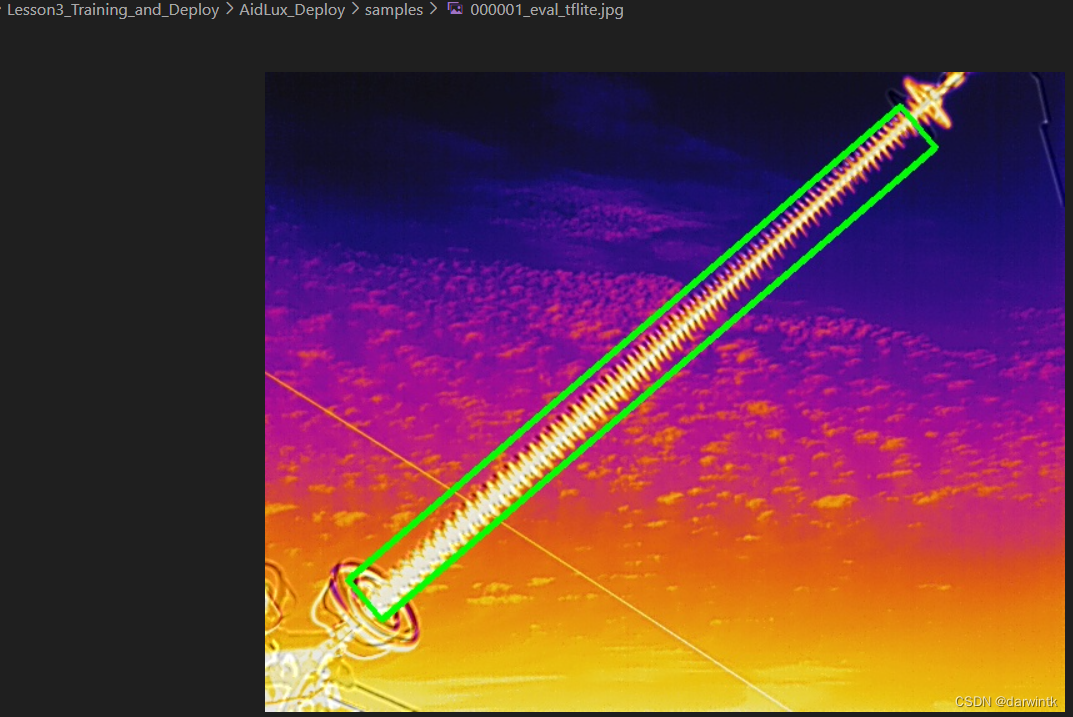
回到R-RetinaNet-v5.0目录下,修改demo_tflite.py中的参数并运行,最后得到与onnx模型预测一致的结果。
AidLux部署和测试
图片检测
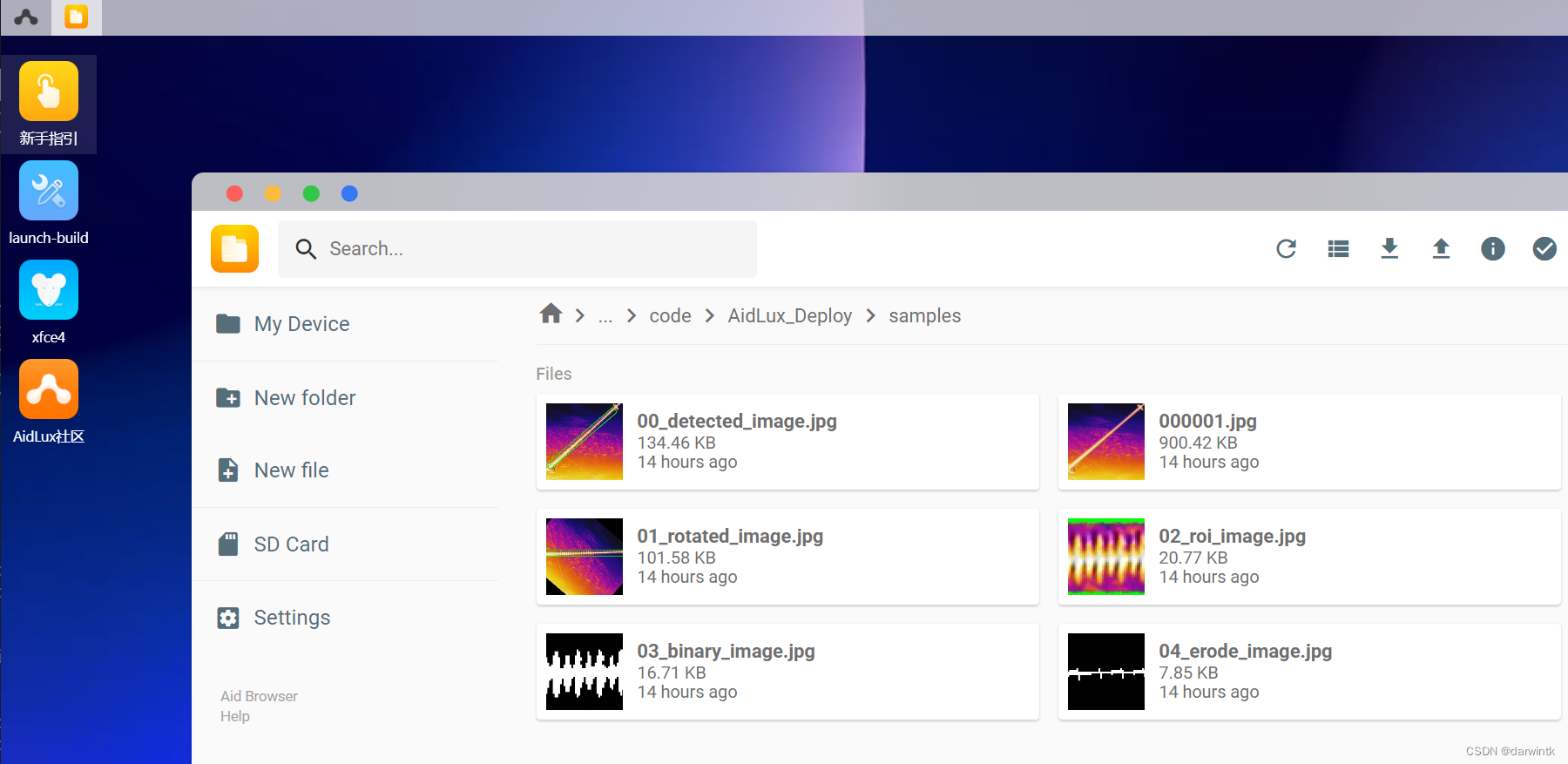
AidLux部署对应代码为AidLux_Deploy,将代码上传至AidLux设备。
将前面转换好的tflite文件放入AidLux_Deploy/models文件夹
修改并运行AidLux_Deploy/r-retinanet-local.py代码,即可在设置好的输出路径中看到代码运行结果。
摄像头检测
在图片检测的基础上修改成读取摄像头进行检测
if __name__=="__main__":
''' 定义输入输出shape '''
in_shape = [1 * 640 * 800 * 3 * 4] # HWC, float32
# out_shape = [1 * 53325 * 8 * 4] # 8400: total cells, 52 = 48(num_classes) + 4(xywh), float32
out_shape = [1 * 55425 * 8 * 4] # 8400: total cells, 52 = 48(num_classes) + 4(xywh), float32
''' AidLite初始化 '''
aidlite = aidlite_gpu.aidlite()
''' 加载R-RetinaNet模型 '''
tflite_model = '/home/code/AidLux_Deploy/models/r-retinanet-statedict.tflite'
res = aidlite.ANNModel(tflite_model, in_shape, out_shape, 4, -1) # Infer on -1: cpu, 0: gpu, 1: mixed, 2: dsp
print(res)
''' 读取手机后置摄像头 '''
cap = cvs.VideoCapture(0)
img = cap.read()
print(img.shape)
frame_id = 0
while True:
img = cap.read()
if img is None:
continue
frame_id += 1
if frame_id % 2 != 0:
continue
im, im_scales = process_img(img, NCHW=False, ToTensor=False) # im: NHWC
''' 设定输入输出 '''
aidlite.setInput_Float32(im, 800, 640)
''' 启动推理 '''
aidlite.invoke()
''' 捕获输出 '''
preds = aidlite.getOutput_Float32(0)
# preds = preds.reshape(1, 8, 53325)
preds = preds.reshape(1, 8, (int)(preds.shape[0]/8))
output = np.transpose(preds, (0, 2, 1))
''' 创建Anchor '''
im_anchor = np.transpose(im, (0, 3, 1, 2)).astype(np.float32)
anchors_list = []
anchor_generator = Anchors(ratios = np.array([0.2, 0.5, 1, 2, 5]))
original_anchors = anchor_generator(im_anchor) # (bs, num_all_achors, 5)
anchors_list.append(original_anchors)
''' 解算输出 '''
decode_output = decoder(im_anchor, anchors_list[-1], output[..., 5:8], output[..., 0:5], thresh=0.5, nms_thresh=0.2, test_conf=None)
for i in range(len(decode_output)):
print("dim({}), shape: {}".format(i, decode_output[i].shape))
''' 重构输出 '''
scores = decode_output[0].reshape(-1, 1)
classes = decode_output[1].reshape(-1, 1)
boxes = decode_output[2]
boxes[:, :4] = boxes[:, :4] / im_scales
if boxes.shape[1] > 5:
boxes[:, 5:9] = boxes[:, 5:9] / im_scales
dets = np.concatenate([classes, scores, boxes], axis=1)
''' 过滤类别 '''
keep = np.where(classes > 0)[0]
dets = dets[keep, :]
''' 转换坐标('xyxya'->'xyxyxyxy') '''
res = sort_corners(rbox_2_quad(dets[:, 2:]))
''' 评估绘图 '''
for k in range(dets.shape[0]):
cv2.line(img, (int(res[k, 0]), int(res[k, 1])), (int(res[k, 2]), int(res[k, 3])), (0, 255, 0), 3)
cv2.line(img, (int(res[k, 2]), int(res[k, 3])), (int(res[k, 4]), int(res[k, 5])), (0, 255, 0), 3)
cv2.line(img, (int(res[k, 4]), int(res[k, 5])), (int(res[k, 6]), int(res[k, 7])), (0, 255, 0), 3)
cv2.line(img, (int(res[k, 6]), int(res[k, 7])), (int(res[k, 0]), int(res[k, 1])), (0, 255, 0), 3)
cv2.line(img, (int(res[k, 6]), int(res[k, 7])), (int(res[k, 0]), int(res[k, 1])), (0, 255, 0), 3)
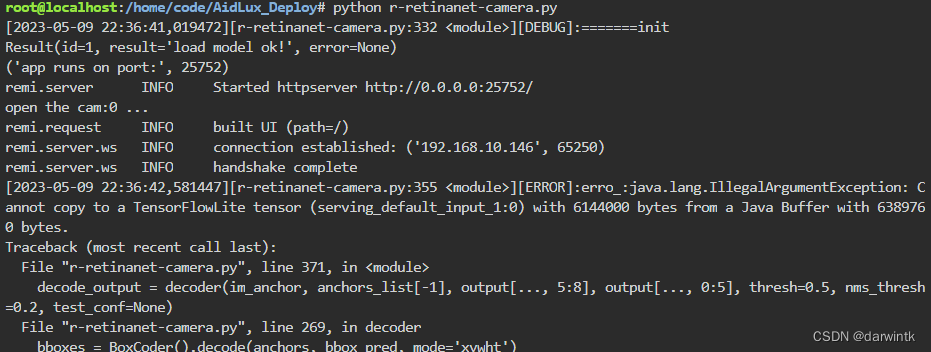
cvs.imshow(img)但出现报错,暂未解决:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









