







SQL
MySQL的SQL跟许多关系型数据库一样,大同小异,主要分为四种:DDL(Database Definition Language)、DML(Database Management Language)、DQL(Database Query Language)、DCL(Database Control Language)对应了数据库中表的定义、操作、查询、权限控制。
- DDL
数据库定义语言
语法:
创建数据库 :
create database 数据库名;(普通写法)
create database if not exists 数据库名;(不存在则创建,防止重复创建报错)
删除数据库:
drop database 数据库名 ;(普通写法)
drop database if exists 数据库名;(存在则删除,防止重复删除报错)
使用数据库:
use 数据库名;
select database(); (查看当前使用的数据库是哪个)
查看所有存在的数据库:
show databases;
创建表:
create table 表名称(
字段名称1 数据类型,
......
字段名称2 数据类型,
字段名称n 数据类型
);
表(具体结构)
| 字段名1 | 字段名2 | … | 字段名n |
|---|---|---|---|
| 值 | 值 | … | 值 |
删除表:
drop table 表名;
drop table if exists 表名;(存在则删除)
修改表:
更改表名:
alter table 表名 rename to 新的表名;
添加字段
alter table 表名 add 字段名 数据类型;
修改字段的类型
alter table 表名 modify 字段名 新数据类型;
修改字段名和数据类型
alter table 表名 change 字段名 新字段名 数据类型;
删除字段
alter table 表名 drop 字段名;
查看表的结构:
desc 表名;
- DML
数据库操作语言
语句:
添加记录:
赋予指定字段数据,并添加一条记录:
insert into 表名(字段名1,字段名2,字段名3,...) values(值1,值2,值3,...);
赋予所有字段数据,并添加一条记录:
insert into 表名 values(值1,值2,值3,...);
批量添加记录:
insert into 表名(字段名1,字段名2,字段名3,...) values (值1,值2,值3,...),(值1,值2,值3,...),(值1,值2,值3,...);
insert into 表名 values (值1,值2,值3,...),(值1,值2,值3,...),(值1,值2,值3,...);
修改记录:
update 表名 set 字段名1 = 值1,字段名2=值2,字段名3=值3 where 条件;
注:若省略 where 条件,则会将所有记录的对应字段修改。
删除记录:
delete from 表名 where 条件;
注:若省略 where 条件,则会将所有记录都删除。
- DQL
数据库查询语言
查询语法:
select字段列表
from表名列表
where条件列表
group by分组字段
having分组后条件
order by排序字段
limit分页限定;
基础查询:
查询某列数据
select 字段名 from 表名;
查询多列数据
select 字段名1,字段名2,... from 表名;
查询所有列数据
select * from 表名;
去重查询
select distinct 字段名 from 表名;
起别名
select 字段名 as 别名 from 表名;
条件查询:
select 字段列表 from 表名 where 条件列表;
注:如果要判断字段值是否为null不能用=,必须使用 is 关键字
模糊查询
select 字段列表 from 表名 where 某字段 like 模糊字符串;
注:模糊字符串的通配符有%表示多个字符,_表示单个字符。
排序查询:
select 字段列表 from 表名 order by 字段名1 排序方式,字段名2 排序方式,... 排序方式;
注:asc:升序排序 desc:降序排序
分组查询:
聚合函数:
count(字段名) 统计数量 (如要统计表所有的记录,最常用count(*))
max(字段名) 最大值
min(字段名) 最小值
sum(字段名) 求和
avg(字段名) 平均分
注:null 值不参与聚合函数的计算
select 聚合函数(字段名) from 表名;
分组查询语法:
select 字段列表 from 表名 [where 分组前条件] group by 分组字段名 [having 分组后条件];
注:
where 与 having 区别在于执行时机不同,且having是对分组后的结果进行过滤,having能对聚合函数进行判断,where不行。
分组后,查询的字段列表为聚合函数和分组字段,其他字段无意义.
语句执行顺序:where >group by > 聚合函数 > having
分页查询:
select 字段列表 from 表名 limit 起始索引,最大记录条目数;
注:
起始索引是从0开始算的(第0条记录)
记录条目数是一页现实的记录数量
limit 关键字是 MySQL 特有
多表查询:
select 字段列表 from 表名1,表名2;
注:该语句查询出来的记录个数是 所有表记录的笛卡儿积(就是两个表的数据自由组合的结果)。
所以一般 多表查询 都会用上 where 条件判断,去除笛卡尔积出来了无效数据:
select 字段列表 from 表名1,表名2 where 条件;
连接查询:
内连接:查询两个表中交集的数据
外连接:
左外连接:相当于查询A表
连接查询(如图所示):
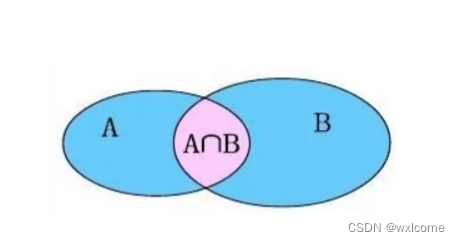
内连接:查询两个表中交集的数据
隐式内连接:
select 字段列表 from 表1,表2 where 条件;
显示内连接:
select 字段列表 from 表1 inner join 表2 on 条件;
外连接:
左外连接:相当于查询A表的所有数据和交集的数据。
select 字段列表 from 表1 left join 表2 on 条件;
右外连接:相当于查询B表的所有数据和交集的数据。
select 字段列表 from 表1 right join 表2 on 条件;
子查询(嵌套查询):
















 306
306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









