






一、起始篇
1.4 存储程序计算机
问题描述:
假如有一串这样的十进制数字:23277366664792221这样的一串数字,计算出该字符串中最大的游程是什么?(游程指的是在字符串中重复连续出现的字符最多的次数)
解决方法:
对于我们人类来说,一眼就能看出最大的游程是4(字符串中有4个连续的6),但假如数字有成千上百个呢,我们就要通过计算机来计算了,需要站在计算机的角度来解决问题。
计算机从字符串的开始位置逐个读取,并和前一个字符进行比较,如果相同,则将它列入相同的序列,同时该序列的长度增加1,如果不同,则开启新的序列,该新的序列为最新读取的数字。
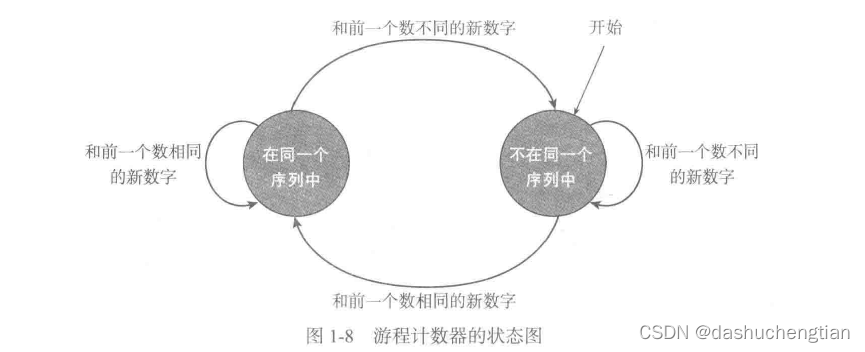
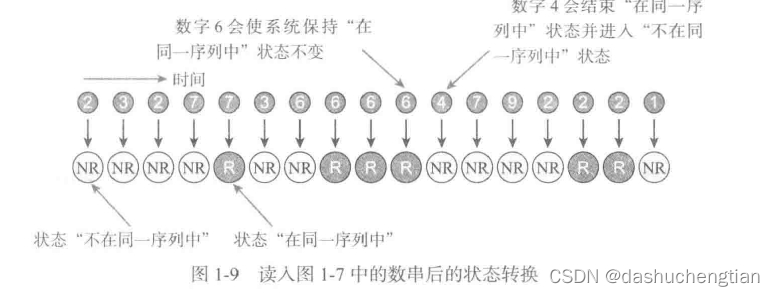
同时我们也可以用表格的形式表示这种解决办法:

构造算法:
i 当前字符的位置
New Diget 刚从串中读出的数字的值
Current_Run_Value 当前序列的值
Current_Run_Length 当前序列长度
Max_Run 目前为止的最大序列长度
下面用伪代码来表示:(伪代码是介于算法和程序之间的一种表示方法)
1、读出串的第一个数字,将赋值给New Diget
2、将Current_Run_Value的值设置为New Diget
3、将Current_Run_Length的值设为1
4、将Max_Run 的值设为1
5、 REPEAT
6、 串 Read New Diget #从串中读出下一个数字
7、 IF 它的值与Current_Run_Value的值相同
8、
THEN Current_Run_Length=Current_Run_Length+1
9、 ELSE{Current_Run_Length=1
10、 Current_Run_Value=New Diget
}
11、 IF Current_Run_Length>Max_Run
12、 THEN Max_Run =Current_Run_Length
13、 UNTIL 直到读完最后一个数字
存储器的简单介绍
存储器是用来存储信息的,比如上面算法中的指令,变量,还有变量的地址,这些都是存储在存储器当中的,存储器有很多的类别,按照速度划分,非常快的Cache(CPU里面的寄存器)、主存(内存条)、辅存(机械硬盘或固态硬盘等)。
1.5 存储程序的概念
程序是有很多条指令组成的执行命令,程序被存储在存储器中,每条指令或者变量在存储器中都有自己的地址,计算机是通过地址来找到指令或者相对应的值得,如有三个地址,分别是P、Q、R,Q地址中存储的是整数4,R地址中存储的是5,现在要将R和Q进行相加,并将结果存储到地址P中,为了实现这个功能,一般的指令设置为ADD P,Q,R,在计算机内部实现的原理如下图:
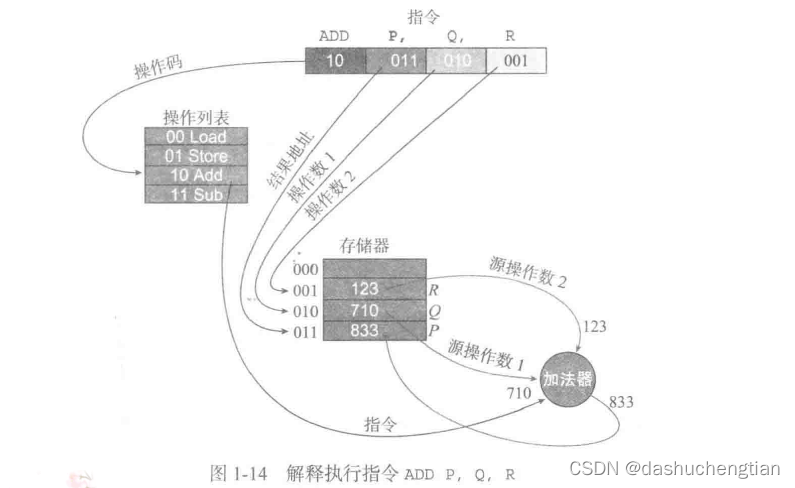
首先CPU从内存中加载指令(ADD P,Q,R),加载之后,解释成操作列表,cpu会从存储器中读出Q地址的内容,然后再读出R地址的内容,放到CPU的加法器(ALU逻辑运算单元)中相加并将结果写入存储器中的P地址。
1.5.1 计算机分类
按照计算机指令对数据进行处理的方式,计算机可以分为以下3类:
1、存储器——存储器计算机,该计算机能够直接从存储器中读取数据并进行相关的操作,然后将数据存储到存储器中。
2、寄存器——存储器计算机,该计算机的能够处理两个数据,一个数据来源于寄存器,一个来源于存储器,其结果要么存储在寄存器中,要么存储在存储器中。
3、寄存器——寄存器计算机,该计算机只能处理寄存器中的数据,该数据的来源通过Load指令从存储器中获得数据,用Store指令将数据存回存储器中。
1.6.1 存储器
在计算机中存储器有很多类型,按照速度的划分,可以呈现金字塔的字样,如图所示:
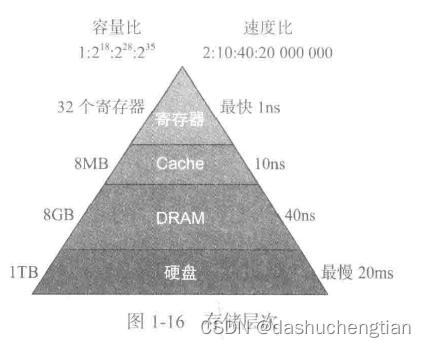
金字塔的最顶端的存储器的速度越快,但存储容量也越小,其中寄存器是放在CPU内部的,还有就是Cache,它有L1-L3级 的缓存,L1最快,依次递减,cpu会先去L1级缓存那里找数据,如果没有则去L2,如果L3也没有,那就只能去DRAM(主存)中去找。
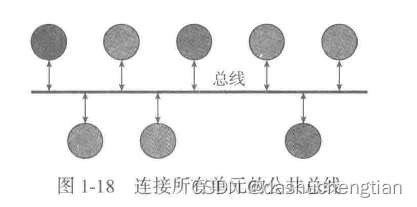
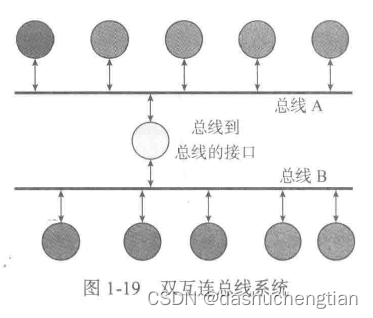
1.6.2 总线
总线是用于连接两个单元之间的桥梁,让两个单元之间可以互相通信,如CPU单元和存储单元需要通信的话,需要在两者之间用总线连接上,在复杂的计算机中总线有很多条,如USB总线,用于连接存储外设,另外总线与总线又通过另外的总线来连接,实现了计算机内部各个单元的互相通信。
二、计算机算术
2.1、数据是什么
在计算机中,数据指的是文本,视频,音频,图像等信息,在计算机中这些内容都将被转换为计算机能够识别的二进制数据,为什么要选择二进制数据,而不是十进制等其他呢,主要是因为二进制数仅用0和1两个数就可以表示任何的信息,这样用高压电平表示就比较简单,成本也比较低和可靠。
2.2 位和字节
在计算机二进制中的0和1的这些数字叫做位(bit),每8位组成一个1个字节(byte)!
2.3 位模式
计算机是用位模式来进行运算的,也就是说计算机会将输入的文本,音频,视频等转换为相应的二进制模式,在二进制中,通常8位为一组,如00000001,不同数量的位可以表示不同数字的组合,比如说2位,那么可以表示为4种组合,即00,01,10,11,依次类推,有n位,就有种组合,这些组合可以用来表示不同的含义,比如说要用来表示人的年龄,那么用8位的二进制就绰绰有余了,因为8位有256种组合,可以用来表示256个数字或者其他内容。
2.4 字符
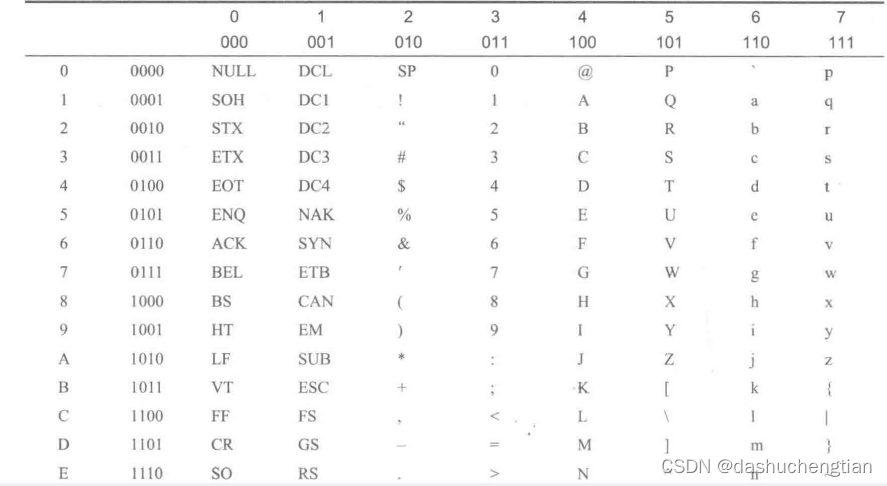
字符就是我们非常熟悉的汉字,英文等,如‘家’、‘A’、‘停’、‘C’等,但是这些字符对于计算机来说是不能识别的,计算机只能识别二进制,所以必须要有一张编码表,把每个字符给它一个对应的编号,这个编号是二进制形式的,也就是上面所说的位模式,例如字符‘@’用二进制表示为00000100,下图是ASCII编码表,它用7位来表示,可以表示128个字符,它是类似于excel表格的,字符通过行和列来确定,如字符‘B’所在的行是0010,所在的列是100,所以它的二进制编码是0010100。
2.5 二进制运算
二进制运算跟十进制运算规则一样,只不过二进制的基数为2,十进制的基数为10,二进制在加减乘除的时候,运算的种类不多。
规则:
不管是两位二进制数是相加还是相减,都要将他们的每一个对应的位进行运算,从低位开始运算,下图是二进制的加减乘的规则:

例子:


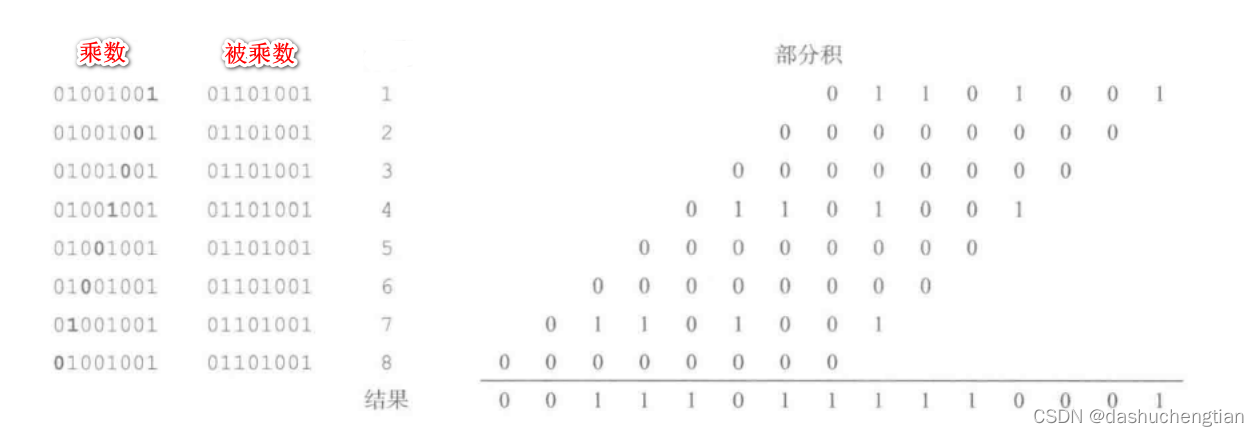
乘法运算的过程:和十进制的乘法运算时一样的,先用乘数的最低位去乘被乘数的所有位,依次循环直到乘完乘数的最高位,最后将全部相加:
2.6 有符号整数
有符号整数也就是有正有负的整数,无符号整数指的是全部都是正的整数,一般用于表示有符号整数的方法有三种,分别是符号及值表示法,补码以及移码,每种表示法都有其优缺点,用于不同的场景。
符号及值表示法:
用二进制中的最高位来表示正负,0表示正,1表示为负,如00001101表示为+13,10001101表示为-13。
由于符号及值表示法在运算中需要用到加法器和减法器,比较繁琐,一般用于浮点数计算的时候用该方法,而另外一种补码表示法则只需要一种加法器即可实现加减乘除。
补码表示法:
这里讲的补码是二进制的补码,在二进制补码运算中,一个n位的二进制数N,它的补码是2^n-N,例如5(二进制为00000101)的补码为2^8-00000101=10000000-00000101=11111011,基于这个公式可以推导出计算一个数补码的快捷方式:将这个数的所有位取反+1,例如00000101的补码就是00000101+1=11111011。
补码使得在算术运算中减法的实现只需要加法器就可以实现,如7-5,那么只需要将7的二进制数加上5的二进制数的补码,这样就实现了减法。

补码具有以下几个特点:
补码中的0是唯一的,不会存在两个0,补码的最高位为符号位,如果为0,则表示正数,如果为1,则表示为负数。
移位运算:
移位运算用于计算机中的乘法和除法,在向右移1位表示除以2,向左移1位表示乘以2,我们先来看一下移位的规则,这里以补码的移位作为例子:
向左移:全部位向左移,最高位被丢弃,最低位补0,如111001000左移1位,变成110010000。
向右移:全部位向右移,最高位补符号位,如10001100向右移1位,变成11000110。
利用移位和加法就能够实现n位的乘法运算了,下面以无符号整数乘法为例:
计算两个n位无符号整数的乘积,下图给出了计算机内部的实现步骤:

根据以上步骤计算1101 x 1010,下图给出了各个步骤的具体演算过程:
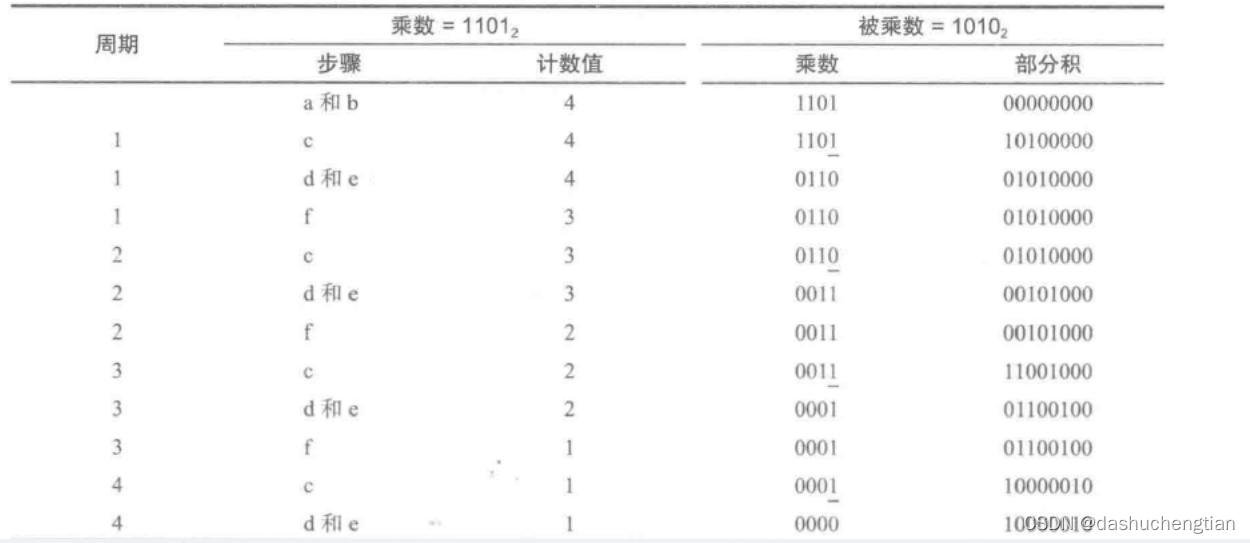
以上这种计算乘法的方法速度是比较慢的,于是人们有想出了其他方法,例如下面这个例子:
P x 10=2(2 x 2 x P + P) #将P左移两位,然后加上p,最后左移1位
9P=2 x 2 x 2 x P + P#将P左移3位,然后再加上P
另外还有一种方法叫做查表法,简单来说就是像10进制的九九乘法表一样,将可能出现的结果都放到表里面,在里面进行查找就可以了。
2.7 浮点数
2.7.1 什么是浮点数
浮点数是实数,包括了有理数和无理数,如1.2334,在二进制中使用规格化的浮点数表示方法,类似于十进制的科学表示法:
尾数 X 2^e
例如:1.01 X2^3,在二进制数的表示中,尾数的最高位总是1,这种表示方法也叫IEEE 754表示法,在该方法中,尾数用F表示,指数用E表示。
在IEEE表示法中,浮点数有三部分组成,分别是符号位,指数和尾数。

符号位用S表示,如果浮点数为负,则S=1,若浮点数为正,则S=0;
按照浮点数的长度可以分为单精度(32位)、双精度(64位)和四精度(128位),精度越高,表明尾数的精度也越高。
例子如下:


2.7.2 浮点数运算
不管是两个浮点数相加还是相乘,都需要经过以下步骤:

举例:

2.7.3 舍入和截断误差
当浮点数进行运算的时候,有可能导致尾数位数的增加,如果我们需要保留尾数4位,但尾数却有6位,这时候就需要通过方法将浮点数的尾数保留4位,有以下两种方法:
1、截断
截断就是在浮点数的尾数上进行截断,比如1.000101需要保留4位尾数,那么就在尾数的第4位进行截断,截断后的值为1.0001。
2、舍入
二进制的舍入和十进制的舍入差不多,在二进制中,舍入是需要判断剩余位的最低位的一半和丢弃位之间的大小,如果最低位的一半大于丢弃位,则直接删掉丢弃位,什么都不做,如果最低位的一半小于丢弃位,则删除丢弃位并加1,举例:
要对0.1101101进行舍入,要保留4位尾数的话,那么就需要判断,在这里,最低位是0.0001,要丢弃的位为0.0000101,那么最低位的一半是0.00001,很明显最低位的一半小于丢弃位,那么就要将0.1101加1,得到结果为0.1110。

三、体系结构与组成
3.1 存储程序计算机
ARM处理器类型的计算机就是存储程序计算机的一种,该处理器内部有寄存器、逻辑运算单元(ALU),控制单元组成。
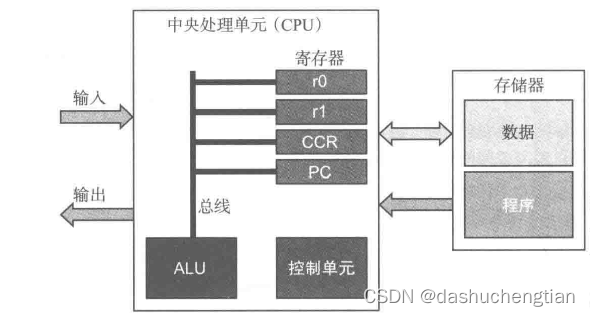
寄存器是CPU内部的存储单元,存储器一般有多个,但一般不会超过20个,每个寄存器都有自己的名字,在ARM处理器中,用r0,r1,r2.....r15这样的命名方式命名,CPU中的寄存器也有很多种类型,如用于存储中间值的寄存器,用于记录下一个指令地址的程序计数器(PC)。、
计算机指令
计算机指令常见的格式如下:

计算机处理器内部结构运行的部分图解:
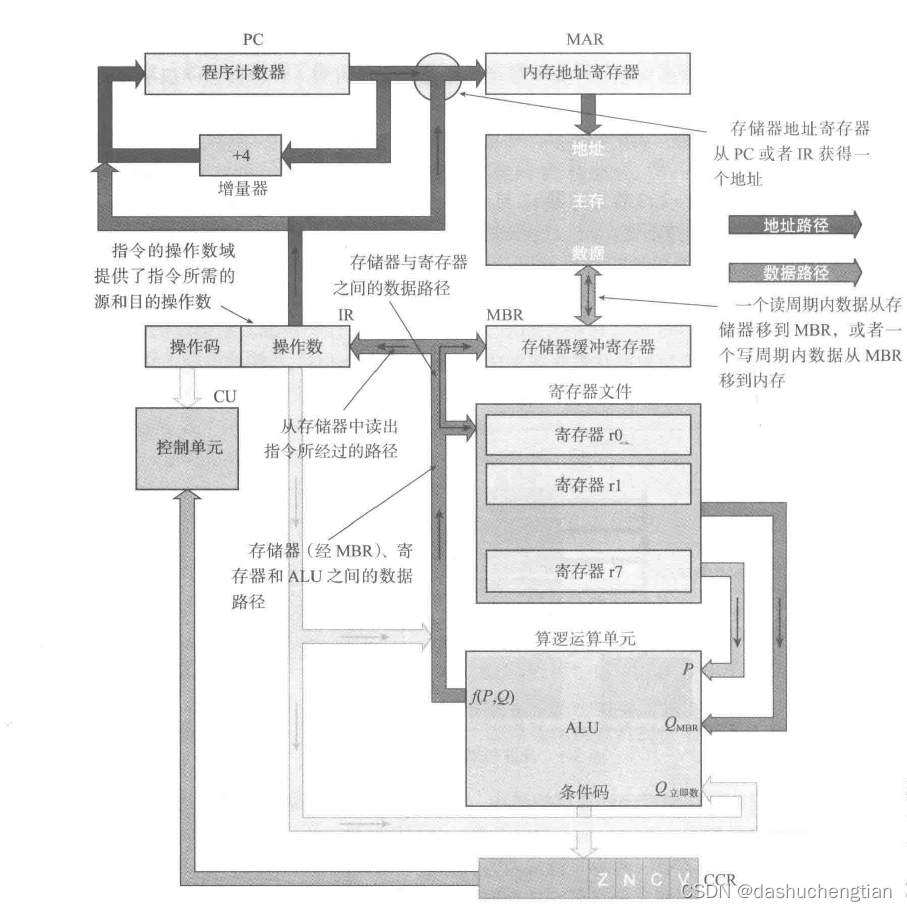
从上图可以看到有地址寄存器和数据寄存器,程序计数器和存储地址寄存器属于地址类型的寄存器,用于地址的存储,而存储器缓冲寄存器、指令寄存器(IR)和寄存器文件则属于数据寄存器,用于数据的传输和存储,图中用灰色线表示数据的传输路径,深色线表示地址的传输路径。
寄存器CCR
在寄存器中,有一种寄存器叫CCR,它是用于存储状态信息的,并将状态信息反馈给控制单元(CU),这个状态信息来源于逻辑运算单元(ALU)产生的结果,这些状态有零位,借位位,负位及溢出位,每当ALU执行一个操作,它都会更新CCR中的状态信息,然后控制单元从CCR中获得这些状态信息,用于选择下一步的指令,最常见的是条件分支指令。
例子:
比如有以下高级语言代码:
X=P-Q
IF X>0
X=P+5
ELSE
X=P+20
然后转换成汇编语言的伪指令,如下图所示:

其中DCD指的是为存储单元起一个名字,就像高级语言中的定义变量,如int P=12,在这里"P DCD 12"指令表示的是将12个数字保存到存储单元中,并命名为P。
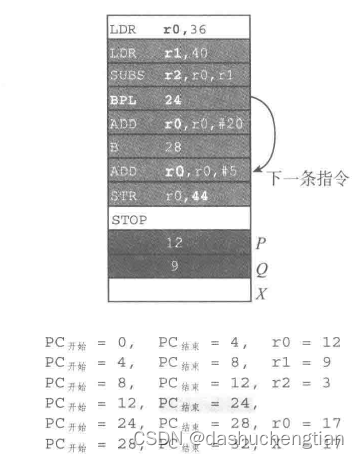
如果要执行以上的条件分支,需要将P-Q的操作发给ALU进行逻辑运算,运算完成之后会更新CCR中的状态位,如果测试的状态位false,那么控制单元就会得到信号,则程序计数器自动按顺序更新到下一个指令地址,也就是“ADD r0,r0,#20”这条指令,如果测试的状态位false,则程序计数器则会跳转到新的地址,也就是“THEN ADD r0,r0,#5”这条指令这里。
为了更好地理解,给出了在内存中指令的执行顺序来说明,在这张图中,指令和数据都是放在内存中,比如第一条指令"LDR r0,36"指的是将36这个地址中的内容加载到寄存器r0中,下图中的"PC开始"指的是当前执行指令的地址,而"PC结束"则指的是下一条要执行指令的地址。
3.2 ISA 的组成
ISA指的是计算机指令集机构,包括3部分,分别是寄存器集,寻址方式,指令格式!
3.2.1 寄存器集
寄存器和存储器相似,区别在于寄存器的运行速度更快,在ARM体系的计算机中,一般有16个通用寄存器,从r0到r15。
3.2.2 寻址方式
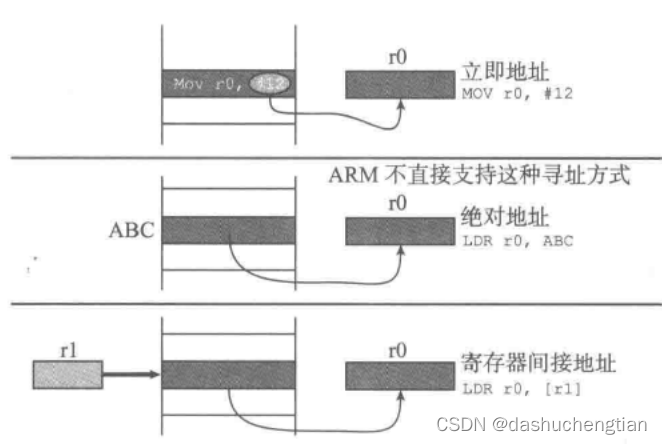
计算机指令的寻址方式指的是指令找数据的方式,有3种寻址方式:
1、立即寻址
当指令中的操作数是立即数,就会采用立即数寻址,例如 ADD r1,#5,表示将寄存器r1的值加上5,这里的5是立即数,不用从内存或其他寄存器中提取,可以直接拿来进行操作!
2、直接寻址
直接寻址的是指令中的操作数表示的是内存中的地址,比如说有专业那个一条指令:ADD P ,Q,R,其中P,Q,R表示的都是内存中的地址,需要从内存中提取数据才能进行操作。
3、间接寻址
间接寻址指的是指令中的操作数表示的是寄存器的地址,而寄存器存的内容又是要提取数据的地址,该数据存放于内存中,相当于寄存器里面存放的是指针,例如复制指令MOV r1,[r2],在这条指令中,[r2]表示将寄存器r2中存储的地址中的内容提取出来。
3.2.3 操作码与指令
根据指令中操作码地址的数量,可以将操作码分为三地址,双地址,单地址和零地址指令。
三地址指令
三地址指令有三个操作数,如ADD r0,r1,r2,该指令表示将寄存器r1和r2中的内容相加,将结果存储到寄存器r0中。
双地址指令
在双地址指令中,操作数有两个,例如ADD D1,P,该指令表示将地址P的值跟寄存器D1的值相加,再将结果存储到D1中,有些计算机会将结果存储到P中。
单地址指令
单地址指令中只有一个操作数,例如 ADD Q,该指令表示将地址Q的值加到累加器上,累加器是一个无需指定的寄存器。
零地址指令
零地址指令中没有操作数,例如ADD ,该指令表示的是从栈顶中弹出两个数相加并将结果放到栈顶,零地址格式的指令一般用于栈计算机,下图展示的是一个栈计算机实现(A+B).(C-D)代码的指令实现:

3.3.1 ARM寄存器集
ARM指令集体系的计算当中寄存器有16个,r0-r13为通用寄存器,r14作为链接寄存器,也就是存放子程序返回的地址,r15作为程序计数器,另外ARM的CPSR寄存器为条件状态寄存器,用于存放条件测试状态的。

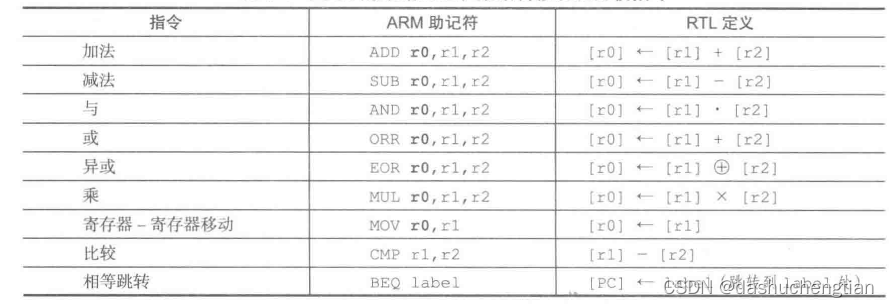
3.3.2 ARM指令集
ARM指令相对于CISC处理器计算机的指令是比较少的,下图列出了ARM常用的一些指令。
3.3.3 ARM汇编语言格式
汇编语言格式有两部分组成,一部分是可执行指令,一部分是汇编伪指令,看下图,红色的就是可执行指令,蓝色的就是汇编伪指令,汇编伪指令提供给汇编器运行环境中的一些信息,比如说END表示程序停止。

3.3.4 汇编器考虑的一些实际因素
汇编器主要使用来讲汇编程序转换为机器码,在转换的过程中,需要考虑一些实际因素,例如
“如何存储字符和值?“
汇编器使用EQU这个伪指令来讲一个数字绑定到一个名字上面,类似于高级语言中的int x=2,也可以理解为变量赋值。
另外汇编器使用DCD伪指令在存储器中预留一个32位的存储地址,例如DCD 32,这个指令会将32这个数据存储到存储器中。
在存储器中存储数据的时候,汇编器使用ALIGN伪指令强制存储单元之间是对齐的。
3.4 伪指令
ARM汇编语言由可执行指令和伪指令构成,伪指令可以看成是可执行指令的封装,相当于高级语言中的函数调用,下面以ARM汇编语言中的LDR这个伪指令为例进行介绍。
LDR指令
LDR伪指令用于将立即数或常量加载到寄存器中,格式如下:
LDR 寄存器地址,立即数或常量地址
例如LDR r1,ox1234,该指令指的是将16进制的1234这个数加载到寄存器r1中。
在ARM的汇编语言中还有其他的伪指令,这些伪指令最后都会被转换成可执行的指令去执行。
3.5 ARM数据处理指令
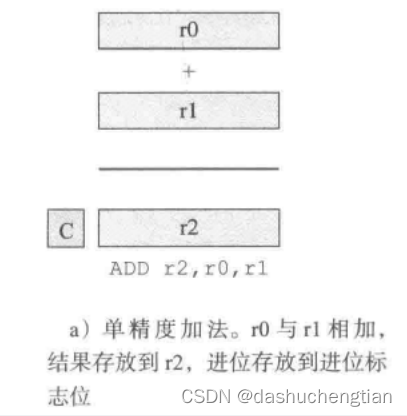
1、加减法指令
加法用ADD指令,格式如下:
ADD 存储地址,操作数1地址,操作数2地址
例子:ADD r0,r1,r2;该指令表示将寄存器r1的值加上寄存器r2的值,再将结果保存到寄存器r0中。
如果有产生进位的话,该进位会保存到CCR(条件寄存器)中。
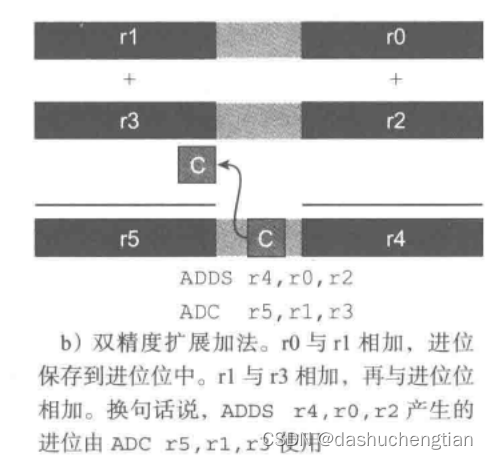
假如是用32位的ARM处理器,如果要加载内存中两个64位的数据进行相加,怎样来算呢?
方法如下:
将第一个64位的数据拆分为32位的高位和32位的低位,将其分别存得到r1和r0寄存器中,将第二个64位的数据拆分为32位的高位和32位的低位,将其分别存储到寄存器r3和r2中,然后将r0+rr2,产生的结果保存到r4中,进位保存到CCR中,然后再用ADC带进位的加法指令将r1和r3相加,将结果保存到r5中,并将CCR中的进位位相加进来,如下图演示:
2、取负指令
在ARM汇编语言中,使用RSB r1,r1,#0,该指令表示将0减去寄存器r1的值,将结果保存到寄存器,从而实现取负的功能。
3、比较指令
使用CMP P,Q这样的格式比较P和Q是否相等,同时会同步更新CCR中的0状态位(Z)。
4、乘法指令
在ARM体系中,乘法用MUL指令,例如 MUL r0,r1,#4,该指令表示r0=r1 x 4。
另外还有一个乘累加的指令(MLA),格式:MLA Rd,Rm,Rs,Rn,该指令表示为Rd=Rm x Rs+Rn,下面通过一个计算内积的例子作为理解:
有两个向量a和b,他们都拥有n个元素,a向量的内容为(a1,a2,a3,....an),b向量的内容为(b1,b2,b3,...bn),那么向量a和向量b的内积为a1.b1+a2.b2+......+an.bn。
实现内积的ARM代码如下:

温馨提示:在ARM体系中没有除法指令,需要程序员自己编写,坑啊!
5、位操作
位操作也叫作逻辑操作,有如下逻辑操作指令:
AND 与指令,规则:只要对应位都是1,则对应的结果为1,否则为0
OR 或指令,规则:对应的位只要有一个是1,则对应的结果为1
NOT 非指令,规则:取反。
EOR 异或指令,规则:对应的位相同,则对应的结果为0,否则为1

位操作的典型应用就是将多个变量合并到一个寄存器或存储单元中,比如在r0的寄存器中存储了一个8位数bbbbbbxx,在r1这个寄存器中存储了一个8位数bbbyyybb,在寄存器r2中存储了一个8位数zzzbbbbb,这里的x,y,z是我们需要保留下来的位,b是不需要保留的,我们希望把保留位合在一起得到的结果是xxyyyzzz,我们可以通过以下操作达到目的:

6、移位操作
在ARM汇编语言中有三种移位操作,分别是逻辑移位,算术移位和循环移位。
逻辑移位
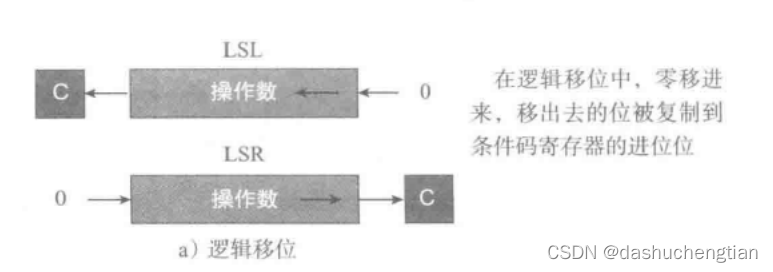
逻辑移位分为逻辑左移(LSL)和逻辑右移(LSR),例如将一个8位二进制0111 0011进行逻辑左移1位,得到的结果是11100110,也就是说最左边的位会被丢弃,右边补0,同样的道理,逻辑右移就是将最右边的位丢弃,左边补0,下面是一些逻辑左移和右移的一些例子:
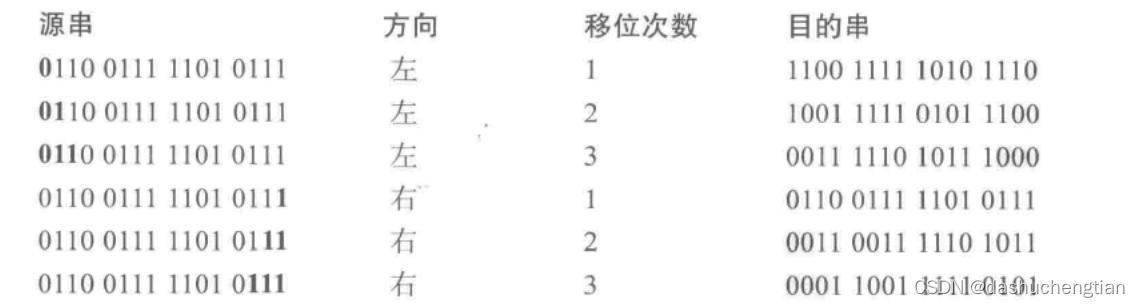
算术移位
算术移位也分为算术左移(ASL)和算术右移(ASR),这里的算术移位针对的是有符号的二进制数补码,算术左移和逻辑左移是一样的,而算术右移则会将最符号位保留,然后将最右边的位放到寄存器CCR中的进位位中,例如将11001110进行算术左移移位得到的结果是10011100,而进行算术右移1位的结果是11100111。
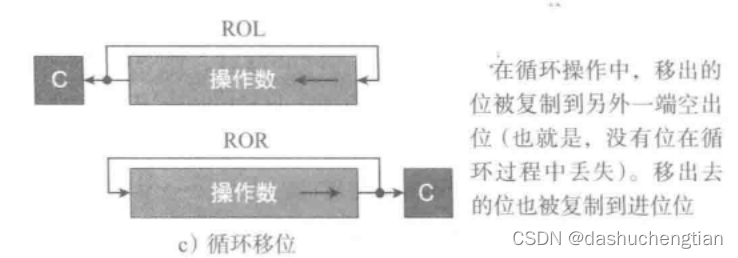
循环移位
循环移位也分为循环左移(ROL)和循环右移(ROR),循环移位是将一端移出去的位从另一端进来,比如有一个二进制数11001110进行循环左移,得到的结果是10011101,循环右移移位的结果是01100111,被移出的位会保存到寄存器CCR中的进位位中。
3.6 ARM条件控制指令
1、无条件控制指令
无条件控制指令用B TARGET格式,B表示无条件跳转,TARGET表示要跳转到的标记位置,例子如下:

2、条件分支
条件分支语句是在满足一定 的条件的时候才会跳转,例如BNE 指令,它表示测试的条件不相等,则跳转到指定的位置,例子如下:

3、测试与比较指令
有CMP,TST,TEQ等测试指令,下面以CMP测试指令为例,格式:CMP r1,r2,它的意思是将r1-r2,测试结果是否相等,这条指令会更新CCR中的零位(Z)和溢出位(V),跟CMP类似的指令还有TEQ,只不过TEQ指令测试完之后,仅修改CCR中的零位,但不会修改溢出位。
4、分支与循环结构
有3种循环结构
1、FOR循环结构
特点:先计数

2、WHILE循环
特点:先做比较,然后执行。

3、UNTILL循环
特点:一开始就执行,至少执行一次。

5、条件执行模式
在ARM中有一种指令模式叫条件执行模式,它是在指令操作符的后面加上条件判断语句,例如ADDEQ r0,r1,r2,该指令在“ADD”操作符后面加了条件判断语句EQ,它表示上一条语句的执行结果是否为0,如果为0,则执行r0=r1+r2的加法运算。
例子1:

例子2:

3.7 ARM寻址方式
在ARM的寻址方式不是绝对地址的寻址方式,而是通过寄存器间的间接寻址,在ARM中有7种寻址方式,如下图:
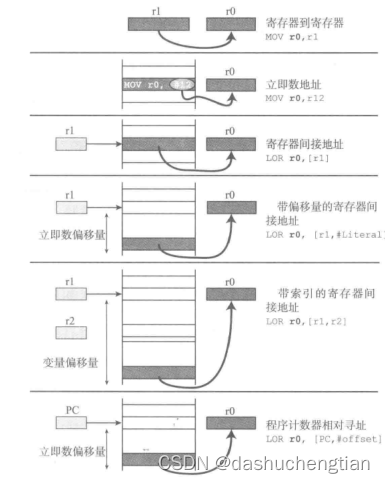
立即数寻址
常见的寻址方式之一是立即数寻址,在ARM指令中,一共有32位,其中立即数占了12位,表示的范围有限,如果要表达无符号的整数,范围是0-4095,如果想要更大的立即数比如5000,就不能了,于是ARM为了解决这个问题,将立即数分为两部分,一部分是对齐码n(4位),一部分是立即数(8位)N,将立即数N循环右移2n次,就可以得到大小为N X 2^(2n)的立即数,这样就大大扩大了立即数的范围,但同样带来了另外一个问题,假如要循环右移奇数次才能得到的数,比如循环右移9次,那又怎样得到呢?这个其实不用担心,汇编器会自动帮我们计算的。
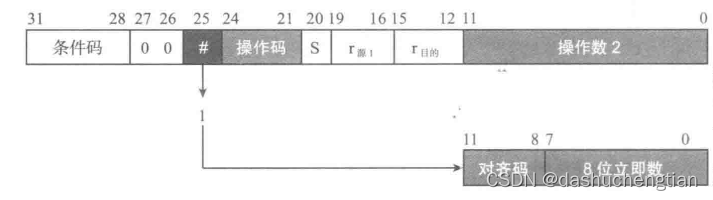
例子:
mov r1,#ox0000FF00
该指令的机器码为16进制的E3A01CFF,立即数编码为16进制的CFF,转换为二进制就是110011111111,其中C是对齐码,转换为10进制就是12,8位立即数是11111111,将该立即数向右循环右移24位(相当于向左移位8位)即可得到16进制的FF00这样大的立即数。
寄存器间接寻址
把操作数的地址放到寄存器中,然后通过寄存器去得到操作数的寻址方式叫做寄存器间接寻址。
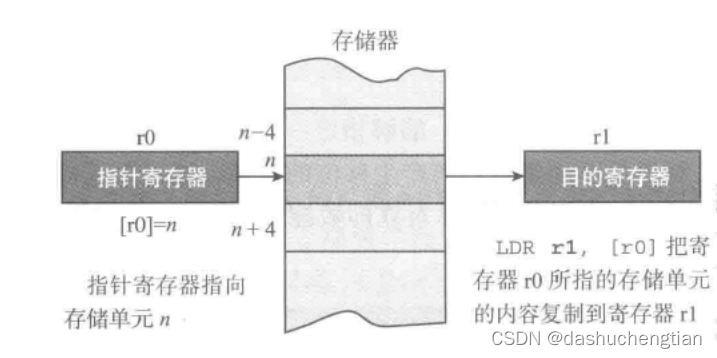
在ARM体系中,通过LDR和STR两个指令来完成加载和存储,下面通过一个例子来演示:

用ARM汇编语言实现的话,就是下面这个样子:
MOV r0,#0 将寄存器r0作为计数器,初始值为0
ADR r8,j 将寄存器r8指向数组J的地址
Loop LDR r1,[r8] 开始循环,将寄存器r8所指向地址的内容加载到寄存器r1中
ADD r1,r1,#10 将寄存器的r1中的内容加10
STR r1,[r8] 将寄存器r1中内容存储到寄存器r8所执行的地址中
ADD r0,r0,#1 将计数器加1
ADR r8,r8,#4 将寄存器r8的地址指向下一个地址
CMP r0,#21 比较计数是不是等于21了
BNE Loop
带偏移量的寄存器间接寻址
在寄存器寻址中,可以在正式加载数据之前,将寄存器加上偏移量,指向新的地址。例子如下:
LDR r1,[r0,#8] ,该语句的意思是将寄存器r1指向的地址偏移8字节,假如r0指向的是第一个地址,那么偏移8个字节就是指向第3个地址,这样就讲第三个地址的内容加载到寄存器r1中。
ARM的自动前索引
自动前索引就是在带偏移量的寄存器间接寻址的基础上后面加上一个“!”号,加上感叹号之后,表示指令完成之后,会自动将作用于偏移量的寄存器的指针自动更新相同的偏移量,例如:
LDR r1,[r0,#8]!,该语句加了感叹号就是自动前索引,它表示将寄存器r0+8地址中的内容加载到寄存器r1中,然后将寄存器r0的指针加8,更新r0的指针。
例子如下:
现有3个数组:
A{1,2,3,4}
B{5,6,7,8}
C{0,0,0,0}
要实现(A1+B1)-》C1,(A2+B2)-》C2,......(A4+B4)-》C4这样的功能,可以通过ARM的自动前索引实现:

ARM自动后索引
自动后索引就是先加载访问,然后再加偏移量,跟自动前索引是反过来的,自动前索引是先加偏移量,然后再访问,看下面的自动后索引例子:

自动后索引是将偏移量放到中括号后面的。
PC程序计数器寻址
寄存器r15是个特殊的寄存器,如果它作为指针寄存器,那么它就是我们常说的PC程序计数器,该寄存器的功能跟其他指针寄存器的功能一样,它也可以实现,只不过换了一种叫法!

3.8 子程序与栈
栈
栈是一种数据结构,它的顺序是先进后出,也就是先进来的数据,后面才出,插入数据叫做入栈,提取或删除数据叫出栈,如下图所示,数字代表插入的顺序,比如数字1是先插入的,它被放到了最下面,3是最后面插入的,被放到最后面,当要出栈的时候,3是最先出的,然后是2,最后是1,也就是先进后出的道理。

栈顶
栈顶就是栈的最顶部,比如上图中的栈顶就是3。
栈指针
栈指针其实就是指向该栈的指针,栈指针默认是指向栈顶的,但它是可以移动的,但有些处理器中,栈指针是指向栈顶上面的空白位置,在这里我们默认指向的是栈顶。
栈与子程序调用
在处理器中子程序调用是很常见的,例如下面的代码:
ADD r1,r0,#5
B Target
SUB r1,r0,#4
当执行到第二条语句"B Target"的时候,程序会跳转到子程序Target中,然后返回继续执行下一条指令,那处理器到底是怎样实现的呢?
首先处理器执行到第二条语句的时候,它会将PC(程序计数器)的值保存到栈中,这个值也就是下一条指令“SUB r1,r0,#4”地址的值,子程序Target执行完成之后,会将栈中保存的PC值返回并将其赋值给PC,这样程序就会执行下一条指令了。

3.9 数组组织中的端格式
在内存中,不管存储的是数据还是指令,最终都会被存储为机器语言,也就是二进制串或十六进制串,在存储这些数据的时候,是按字节依次排放的,但是在每一个字节中,位的排列是有些不同的,跟处理器的类型有关,有两种格式,一是大端格式,二是小端格式。
大端格式:
大端格式指的是将最高位字节存储到低地址中,就跟我们平时的十进制的排列方法是一样的,更加符合人类的习惯,比如十进制123,高位1是放在低地址上的,因为地址是从右边往左边依次增加的。
小端格式:
小端格式跟大端格式正好相反,它将高位字节放到了高位地址中。
举例:
例如要存储二进制数1000 0000,如果用大端格式存储的话,就是1000 0000,最高位1就是在最低位的地址上,如果采用小端格式,则是这样显示:0000 0001,最高位字节放在了最高位的地址上。
3.10 块移动指令
在ARM汇编语言中,可以用一条指令在寄存器和存储器之间传送数据,这就是块移动指令,包括STM块移动指令和LDM块移动指令。
STM块移动指令
该指令指的是将寄存器中的数据传输到存储器上,例如一下代码:
STMIA r0! ,{r1-r3,r5},该指令将寄存器r1,r2,r3和r5中的数据复制到连续的地址中,通过r0作为数据的索引地址。
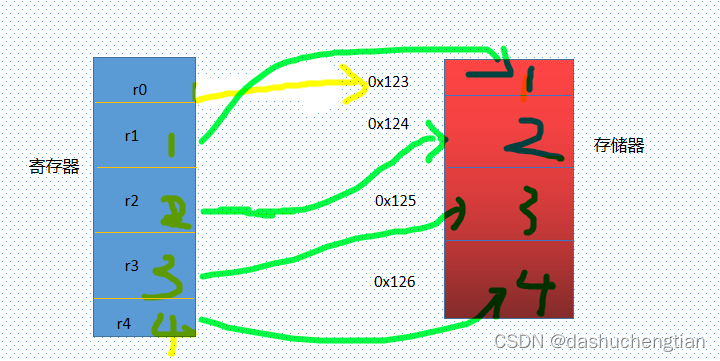
LDM块移动指令
该指令指的是将存储器中的数据加载到寄存器中,如下代码:
LDMIA r0,{r3,r4,r5,r9},该指令指的是将r0所指向的数据地址的内容赋值给寄存器r3,然后r0指向指向下一个存储器中的下一个地址,将该地址中的内容赋值给寄存器r4,以此类推。
3.11 栈指针和帧指针
当程序运行时,在栈中会记录程序中子程序,变量的状态,那么这时候就在栈中引入了栈帧来保存这些状态,在栈中,栈指针(sp)默认是指向栈顶的,也就是说随着栈中内容的变化,栈指针也会跟着变化,这对于访问栈中的变量没那么方便,于是就引入了帧指针(fp),帧指针是指向栈帧底部的一个指针,如图所示。
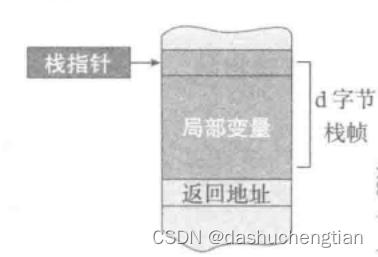
如何创建栈帧?
通过将栈指针上移就可以创建栈帧,比如讲栈指针上移100个字节,那么就会创建100个字节的栈帧,一般将r13寄存器作为栈指针。
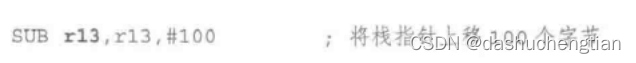
栈帧会被销毁吗?
当子程序运行完成之后,子程序对应的栈帧会自动被销毁,销毁是通过将栈指针下移,从而将栈指针回复到原来的位置,这样就实现了栈帧的销毁。
3.12 特权模式和异常
当程序运行出现错误或者其他中断请求的时候,会触发异常模式,有专门的异常处理程序,在处理异常前,需要先将异常前的状态信息(pc和处理器状态)保存到状态寄存器,等异常执行完毕之后再恢复到原来的位置继续往下执行。















 1182
1182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









