






通过之前的文章《Spark RDD分区数与分区器源码解析》我们了解到了什么是 RDD,RDD 可以简单理解为弹性分布式数据集,RDD提供了很多种类的算子,那么使用RDD的这些算子是如何在分布式环境下去执行的呢?
归根结底,我们编写的代码是需要通过Spark去帮助我们把任务分布到各个集群上并执行的,那么这一类过程我们统称为分布式计算,Spark能实现分布式计算功能主要是靠它的进程模型以及调度系统。
一、Spark 进程模型
Spark 进程模型一共分为两块,分别是:
Driver:负责解析用户代码、构建计算流图,并将计算流程拆分为分布式计算任务然后提交给集群去运行,本质上就是一个运行着上述代码逻辑的JVM进程,当我们提交了一个Spark应用之后,便会启动一个Driver进程。
Executor:真正负责执行用户代码的进程,在Spark分布式环境里,一个工作节点上会运行多个Executor,然后由多个Executor同时去执行任务代码。
它们之间的关系类似于这样:
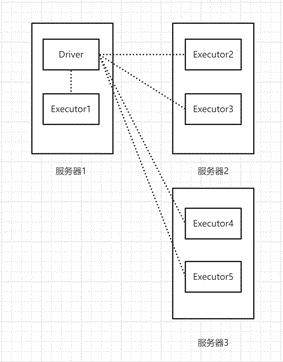
图表1 Driver & Executor
那么大家可能会好奇,Driver具体是如何解析用户代码并构建计算流图、Executor又是如何执行任务的呢?就让我们带着这些问题,具体来看一下Spark的调度系统。
二、Spark调度系统
前面我们讲到Driver是一个进程,那么这个进程里面还运行着DAGScheduler、SchedulerBackend以及TaskScheduler三个线程,这三个线程各自有各自的功能。
DAGScheduler
DAGScheduler的角色有点类似于架构师,负责将整体系统的架构拆分为一个又一个的项目然后交给其他人去实现,这个整体系统架构就是DAG,DAG全称Directed AcyclicGraph —— 有向无环图。在Spark中用DAG来描述我们的计算逻辑,DAG 是一组顶点和边的组合,在Spark中顶点代表了RDD, 边代表了对RDD的一系列操作。在Spark 中引入DAG可以优化计算计划,比如减少Shuffle数据。
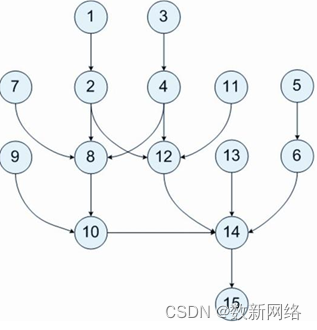
图表2有向无环图
那么DAGScheduler的职责就是将计算图DAG以Shuffle为边界拆分为执行阶段Stages,同时将这个Stage转换为TaskScheduler所需要的Task去调度。

图表3 DAGScheduler 职责
SchedulerBackend
SchedulerBackend的角色则有点类似于人力总监,负责实时汇总并掌握全公司的人力,全公司的人力对应的就是Spark的计算资源,核心职责就是实时收集集群中可用的计算资源并提供给TaskScheduler用以调度。
这些计算资源都是通过与集群内所有Executor中的ExecutorBackend保持周期性通信来获取到的,同时内部使用ExecutorDataMap来保存这些集群信息,ExecutorDataMap是一种HashMap,它的Key是每个Executor的字符串,Value则是用于封装Executor的一个对象,这个对象里面会记录RPC地址、主机地址、可用CPU核数等,它相当于是对Executor做的一个描述,描述该Executor的资源有哪些。
同时SchedulerBackend会将可调度的资源封装成一个WorkerOffer提供给TaskScheduler计算资源,WorkerOffer封装了ExecutorID、主机地址、CPU核数,用来表示一份可用于调度任务的空闲资源。
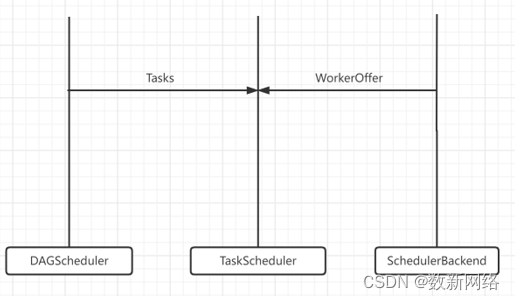
图表4 SchedulerBackend 职责
TaskScheduler
TaskScheduler从DAGScheduler获取到的每一个任务本身都具有不同的资源分配规则,比如说不同Stages之间,TaskScheduler提供了两种调度模式,FIFO(先到先得)和FAIR(公平调度),而在同一个Stages内的不同任务可以按照本地性级别来分配Executor执行,从PROCESS_LOCAL(同一进程内)、NODE_LOCAL(同一节点内)、RACK_LOCAL(同一物理机内)到ANY(无限制),限制越来越宽松。
TaskScheduler的角色则类似于项目经理,总架构师拆分项目后分配给TaskScheduler,然后TaskScheduler又从人力资源总监SchedulerBackend那里获取到自己可用的组员名单,然后将自己拿到的任务以及名单按照资源来分配规则,安排好每个员工的具体工作之后,再给到SchedulerBackend,SchedulerBackend在将这些任务进一步分配给分公司的人力资源管理ExecutorBackend。

图表5 TaskScheduler 职责
ExecutorBackend
ExecutorBackend作为分公司的人力资源主管,在拿到活之后,会把任务分配给底下的组员,这些组员就是Executors线程池里的一个又一个CPU线程,每个线程负责处理一个Task,处理完之后这些线程便会通过ExecutorBackend告知SchedulerBackend,SchedulerBackend和TaskScheduler再以接力的方式告知DAGScheduler,后续再开启下一轮的Stages计算。

图表6 ExecutorBackend 职责
三、总结
在介绍完Spark的进程模型以及任务调度系统之后,想必大家对于Spark又有了一个新的认识,掌握了这些内容就等于掌握了Spark分布式计算的精髓,为我们今后开发高性能代码打下了良好的基础。但这只是冰山一角,Spark本身是一个非常庞大的架构,它衍生出了很多框架,每个框架都有不同的设计理念,都值得我们去学习,学无止境,让我们一起学好基础,努力提高自己吧。
注:文章部分参考来源于网络,如有侵权,请联系删除!
















 638
638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









