






 本文介绍了ZooKeeper,一个开源的分布式协调服务,强调其高可用性、一致性、简单数据模型、事件通知机制以及ZAB协议在保持一致性中的作用。同时讨论了CAP理论在ZooKeeper中的应用,尤其是在分布式系统中的权衡策略。
本文介绍了ZooKeeper,一个开源的分布式协调服务,强调其高可用性、一致性、简单数据模型、事件通知机制以及ZAB协议在保持一致性中的作用。同时讨论了CAP理论在ZooKeeper中的应用,尤其是在分布式系统中的权衡策略。
数新网络-让每个人享受数据的价值
官网现已全新升级—欢迎访问!
前 言
ZooKeeper是一个开源的、高可用的、分布式的协调服务,由Apache软件基金会维护。它旨在帮助管理和协调分布式系统和应用程序,提供了一个可靠的平台,用于处理分布式同步、配置管理和群组服务等任务。ZooKeeper广泛应用于构建分布式系统,它提供了一个稳定的基础来管理配置、协调节点、实现分布式锁、实现分布式队列等。通过ZooKeeper,开发人员可以轻松解决分布式系统中的同步和协调问题,使得分布式应用的开发更加简单和可靠。
01 zookeeper的特点
1-1 高可用性
ZooKeeper的设计目标之一是高可用性。它通过复制数据到多个服务器,使用Quorum算法来确保数据的一致性。如果部分节点发生故障,仍然能够提供可用的服务,保持系统的可用性。
1-2 一致性
ZooKeeper提供强一致性保证。在ZooKeeper集群中,大多数节点(法定人数)必须就数据的状态达成一致意见。这样可以确保每个客户端对数据的读取都能获得相同的最新数据。
1-3 简单数据模型
ZooKeeper采用类似文件系统的数据模型,使用树状结构来存储数据。每个节点(Znode)都有一个路径和一个数据负载。这种简单的数据模型使得ZooKeeper易于理解和使用。
1-4 事件通知
ZooKeeper支持Watch机制,客户端可以设置在Znode上的观察,以便在Znode发生更改时接收通知。这样可以实现分布式的事件通知和协作机制,支持事件驱动的应用程序设计。
1-5 顺序节点
ZooKeeper支持顺序节点的创建,即创建的节点会自动带有唯一递增的序列号。这个特性可用于实现分布式锁、分布式队列等常见的协调原语。
1-6 原子操作
ZooKeeper提供原子操作,可以保证复杂的多步骤操作在ZooKeeper上是原子的。这些原子操作为构建高级别的分布式协调原语提供了支持。
1-7 集群模式
一致性。ZooKeeper集群中的节点可以动态地加入或离开,使得系统更加灵活和可扩展。
1-8 临时节点
ZooKeeper支持临时节点,这些节点的生命周期与客户端会话相关联。当客户端会话结束时,临时节点会被自动删除,这样可以实现临时性的数据和状态管理。
02 zookeeper架构
下图为zookeeper架构的角色分布图:
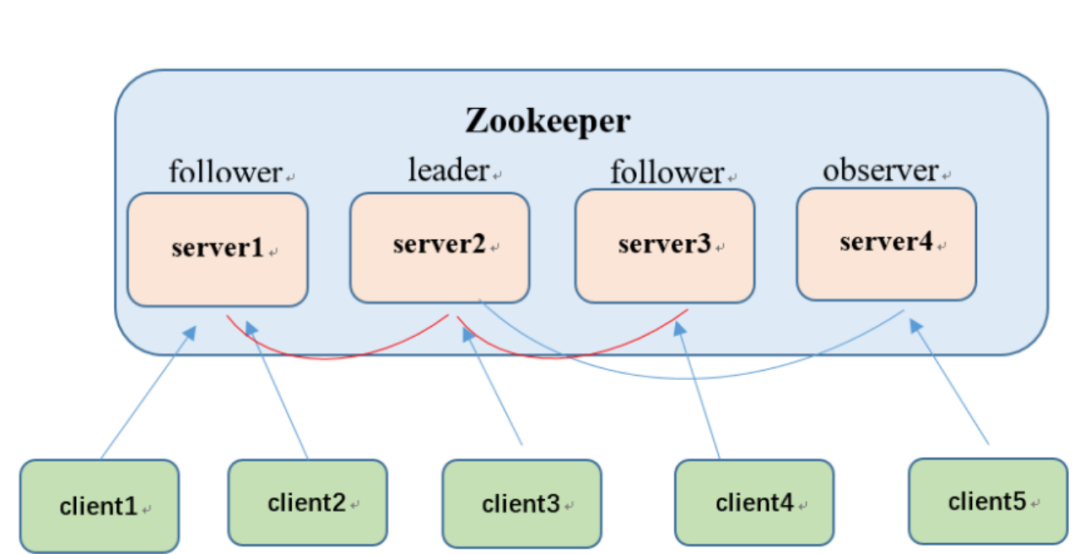
2-1 Leader:
集群中的一个服务器被选举为Leader。Leader负责处理客户端的写请求(例如创建、更新和删除Znodes)和协调分布式事务。Leader通过ZooKeeper协议来确保写操作在集群中的大多数节点上同步执行,以保持数据的一致性。如果Leader服务器发生故障或断开连接,集群会通过选举算法自动选择新的Leader。
2-2 Follower
Follower是集群中的其他服务器,它们遵从Leader的指令,复制Leader上的写操作,以保持数据一致性。Follower可以处理客户端的读请求,但不能处理写请求。Follower与Leader保持心跳连接,以便及时了解Leader的状态。
观察者是一种特殊类型的ZooKeeper服务器,它不参与Leader选举,也不参与写操作的复制。
03 选举机制
集群中在 Zookeeper运行期间 Leader 和 非 Leader 各司其职,当有非 Leader 服务器宕机或加入不会影响 Leader,但是一旦 Leader 服务器挂了,那么整个 Zookeeper 集群将暂停对外服务,会触发新一轮的选举。
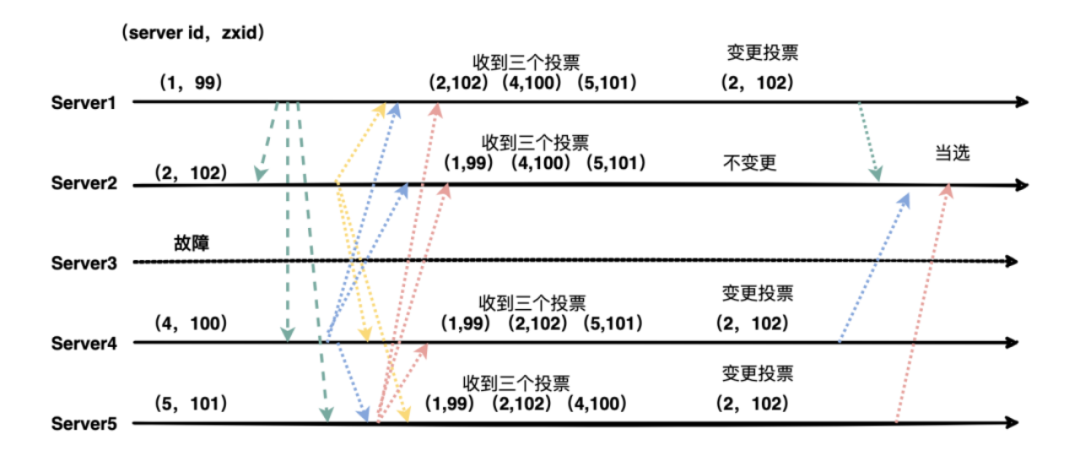
第一次投票每台机器都会将票投给自己。接着每台机器都会将自己的投票发给其他机器,如果发现其他机器的zxid比自己大,那么就需要改投票重新投一次。比如server1 收到了三张票,发现server2的xzid为102,pk一下发现自己输了,后面果断改投票选server2为老大。
3-1 Server id(或sid):服务器ID
比如有三台服务器,编号分别是1,2,3。编号越大在选择算法中的权重越大,比如初始化启动时就是根据服务器ID进行比较。
3-2 Zxid:事务ID
服务器中存放的数据的事务ID,值越大说明数据越新,在选举算法中数据越新权重越大。
3-3 Epoch:逻辑时钟
也叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的,每投完一次票这个数据就会增加。
3-4 Server状态:选举状态
LOOKING,竞选状态。
FOLLOWING,随从状态,同步leader状态,参与投票。
OBSERVING,观察状态,同步leader状态,不参与投票。
LEADING,领导者状态。
04 ZAB协议
ZAB(Zookeeper Atomic Broadcast)协议是Zookeeper内部用于实现分布式一致性的核心协议。它是一个基于原子广播的协议,用于保证Zookeeper集群中数据的一致性和可靠性。ZAB协议是Zookeeper的关键特性之一,确保在集群中的各个节点之间维持数据的一致性。
ZAB协议的特点:
原子广播:ZAB协议确保事务是原子性广播的,要么所有Follower节点都接收到该事务,要么都没有接收到。这样可以保证数据的一致性。
崩溃恢复:ZAB协议允许集群在部分节点宕机或崩溃后,重新选举新的Leader,从而保持服务的可用性和容错性。
顺序性:ZAB协议保证所有节点按照相同的顺序处理事务,从而保持数据的一致性。
轻量级:ZAB协议只需要在集群中的少数节点上进行广播和确认,因此具有较低的通信开销。
交叉验证可以帮助准确地估计模型的性能,从而支持更好的模型选择和超参数调整,以获得更好的泛化性能。
05 CAP理论
Zookeeper是一个分布式协调服务,它主要用于构建分布式系统中的协调和同步机制。而CAP理论则是分布式系统理论中的重要概念,它描述了在分布式系统中三个关键属性的权衡:一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)。CAP理论指出在分布式系统中,无法同时满足这三个属性,只能选择其中两个,因为其中任意两个属性之间是存在冲突的。
具体来说,CAP理论的三个属性解释如下:
5-1 一致性(Consistency)
在分布式系统中,一致性意味着所有节点在同一时刻看到的数据副本是相同的。即使是在有多个副本的情况下,所有节点也能够看到相同的数据。
5-2 可用性(Availability)
可用性指的是系统能够在有限时间内对请求作出响应,并能够保证服务的可用性,即使在部分节点故障的情况下。
5-3 分区容忍性(Partition Tolerance)
网络中断或节点之间无法相互通信,系统仍然能够保持可用性和一致性。
在CAP理论中,在分布式系统中只能选择其中两个属性,并且一般情况下选择分区容忍性是必须的,因为网络分区是不可避免的,特别在大规模的分布式系统中。Zookeeper在设计时倾向于CP(一致性和分区容忍性)模型。
它优先保证数据的一致性和分区容忍性,而可用性可能会在某些情况下受到影响。在Zookeeper中,当网络分区发生时,集群会尝试维持数据的一致性,但可能会导致一些节点在分区期间暂时不可用。这是因为Zookeeper为了保持数据的一致性,需要在多数节点上进行写操作确认,如果无法满足多数节点的写操作,写操作将被阻塞,从而影响可用性。
06 总结
Zookeeper 作为 Hadoop 项目中的一个子项目,是 Hadoop 集群管理的一个必不可少的模块,它主要用 来控制集群中的数据,如它管理 Hadoop 集群中的 NameNode,还有 Hbase 中 Master Election、 Server 之间状态同步等。
Zoopkeeper 提供了一套很好的分布式集群管理的机制,就是它这种基于层次型的目录树的数据结构,并对树中的节点进行有效管理,从而可以设计出多种多样的分布式的数据管理模型。


















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









