







在本章和下一章中,我们将研究现代 GPU 的架构和微架构。 我们将对 GPU 架构的讨论分为两部分:(1) 在本章中研究实现计算部分的 SIMT 内核,然后 (2) 在下一章中研究内存系统。
在其传统的图形渲染角色中,GPU 访问数据集,例如详细的纹理贴图,这些数据集太大而无法完全缓存在芯片上。 为了实现图形处理中需要的高性能可编程性,以随着图形模式数量的增加降低验证成本,并使游戏开发人员能够更轻松地做出差异化的产品 [Lindholm et al., 2001],有必要采用 可以维持大片外带宽的架构。 因此,今天的 GPU 可以并发执行数万个线程。 虽然每个线程的片上内存很小,但缓存仍然可以有效地减少大量的片外存储访问。 例如,在图形工作负载中,相邻像素操作之间存在显著的空间局部性,这可以由片上缓存捕获。
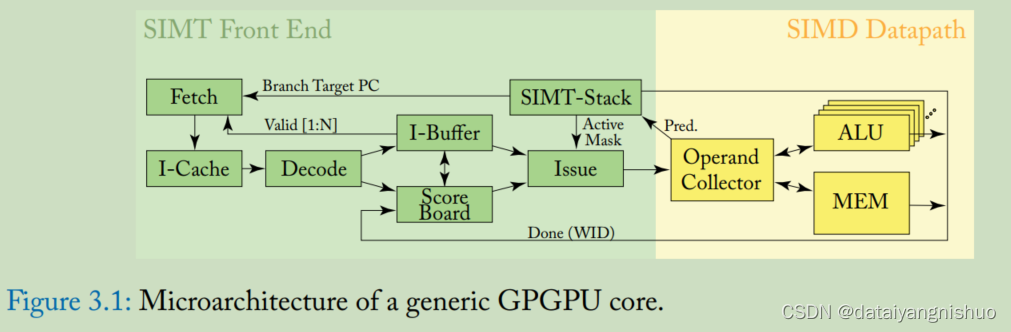
图 3.1 说明了本章讨论的 GPU 流水线的微架构。 此图说明了图 1.2 中所示的单个 SIMT 核心的内部组织结构。 流水线可分为 SIMT 前端和 SIMD 后端。 流水线由三个调度“循环”组成,它们在单个流水线中共同作用:指令获取循环、指令发射循环和寄存器访问调度循环。 指令获取循环包括 Fetch、I-Cache、Decode 和 I-Buffer 模块。 指令发射循环包括 I-Buffer、Scoreboard、Issue 和 SIMT Stack 模块。 寄存器访问调度循环包括标记为操作数收集器、ALU 和内存访问模块。 在本章的其余部分,我们通过考虑依赖于每个循环的架构的关键方面,帮助您全面了解图中的各个模块。
由于全面了解该结构涉及许多细节,因此我们将讨论分成几个部分进行。 我们按照这个顺序是为了越来越详细的开发核心微体系结构。 我们从整个 GPU 流水线的高级视图开始,然后填充细节。 我们将这些越来越准确的描述称为“近似”,以承认即使在我们最详细的描述中也省略了一些细节。 由于当今 GPU 的核心组织原则是多线程,我们围绕上述三个调度循环来组织这些“近似”。 我们发现通过考虑三个越来越准确的“近似循环”来组织本章很方便,这些“近似循环”逐步考虑了这些调度循环的细节。















 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









