







Pytorch学习笔记
基于视频
Pytorch下载与安装
- 下载与安装
- 前置条件
Anaconda下载安装(官网或者清华源)
- 安装Pytorch
(42条消息) pytorch快速安装【清华源】ZQ_ZHU的博客-CSDN博客-c pytorch
注意:下载去掉 -c pytorch!且一定要换源
- 输入验证
import torch torch.cuda.is_availale()运行成功则安装成功
万能函数
-
查看
dir()
注意:_ _ xxx _ _为不可修改的变量
-
帮助
help()
Pytorch加载数据机制
-
Dataset和Dataloader
- Dataset
- 提供一种方式去获取数据及其Label
- Dataloader
- 为后面的网络提供不同的数据形式
- Dataset
-
Dataset的使用
- 基本图像操作
# python中的 python image library from PIL import Image img_path = "B:\\Desktop\\hymenoptera_data\\train\\ants\\0013035.jpg" print(img_path) img = image.open(img_path)
-
操作二
# os.path.join()函数将前后字符串拼接 self.path = os.path.join(self.root_dir, self.label_dir) # 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表 self.img_path = os.listdir(self.path)- Dataset文档
All datasets that represent a map from keys to data samples should subclass it. All subclasses should overwrite :meth:`__getitem__`, supporting fetching a data sample for a given key. Subclasses could also optionally overwrite :meth:`__len__`, which is expected to return the size of the dataset by many :class:`~torch.utils.data.Sampler` implementations and the default options of :class:`~torch.utils.data.DataLoader`. ------------------------------------------------------ 表示从键到数据样本的映射的所有数据集都应子类化,它所有子类都应覆盖:meth:__getitem__函数,支持获取给定密钥的数据样本。子类也可以选择覆盖:meth:__len__函数,它将返回数据集的大小- 调用
# 数据集调用MyData方法创建一个对象 ants_dataset = MyData(root_dir, ants_label_dir) bees_dataset = MyData(root_dir, bees_label_dir) # 两个数据集的合并 train_dataset = ants_dataset + bees_dataset
TensorBoard的使用
-
安装
pip install tensorboard -i https://pypi.tuna.tsinghua.edu.cn/simple # 调整端口 + 运行 tensorboard --logdir=你的路径 --port=6007 -
使用
from torch.utils.tensorboard import SummaryWriter # 定义logs文件夹 writer = SummaryWriter("logs") # y = x for i in range(100): # 第一个参数:图表的title # 第二个参数:X轴 # 第三个参数:Y轴 writer.add_scalar("y = 2*x", 3*i, i) writer.close() -
Scalar中存在问题
-
如果将两个函数写到同一个表中,有可能存在自动拟合现象
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OAdVn93x-1668067221437)(https://cdn.jsdelivr.net/gh/cr7tywzrjw/images/img/202210301700452.png)]
-
-
深度
import numpy as np from torch.utils.tensorboard import SummaryWriter from PIL import Image writer = SummaryWriter("logs") image_path = "B:\\Desktop\\hymenoptera_data\\train\\ants_image\\0013035.jpg" img_PIL = Image.open(image_path) # 将输入的图片类型由JpegImage转换为Numpy格式 img_array = np.array(img_PIL) # 第一个参数:模块名 # 第二个参数:图片输入 # 第三个参数:Step:x # 第四个参数:规定数据格式(H 高 W 宽 C 通道) writer.add_image("test", img_array, 3, dataformats='HWC')
Transform的使用
-
Transforms的结构和作用

-
Transforms的实现
from PIL import Image from torchvision import transforms img_path = "B:\\Desktop\\hymenoptera_data\\train\\ants_image\\0013035.jpg" img = Image.open(img_path) # 利用Transforms模具去设计一个工具tensor_trans tensor_trans = transforms.ToTensor() # 同时利用该工具去处理图像得到一个输出 tensor_img = tensor_trans(img) print(tensor_img) -
Tensor数据类型:包装了神经网络所需要的理论基础参数。
-
Normalize函数
transform.ToTensor(), transform.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))- ToTensor()能够把灰度范围从0-255变换到0-1之间,而后面的transform.Normalize()则把0-1变换到(-1,1).具体地说,对每个通道而言,Normalize执行以下操作
image=(image-mean) / std-
其中mean和std分别通过(0.5,0.5,0.5)和(0.5,0.5,0.5)进行指定。原来的0-1最小值0则变成(0-0.5)/0.5=-1,而最大值1则变成(1-0.5) / 0.5=1
-
数据标准化—transforms.normalize()详解
-
mean 和 std 要在normalize() 之前自己先算好再传进去的,不然每次normalize() 就得把所有的图片都读取一遍算这两个
-
应用了torchvision.transforms.ToTensor,其作用是将数据归一化到[0,1](是将数据除以255),transforms.ToTensor() 会把HWC会变成CHW(拓展:格式为(h,w,c),像素顺序为RGB)
-
ToTensor已经[0,1]为什么还要[0.5, 0.5, 0.5]?那么归一化后为什么还要接一个Normalize()呢?Normalize()是对数据按通道进行标准化,即减去均值,再除以方差
-
解答:数据如果分布在(0,1)之间,可能实际的bias,就是神经网络的输入b会比较大,而模型初始化时b=0的,这样会导致神经网络收敛比较慢,经过Normalize后,可以加快模型的收敛速度。
因为对RGB图片而言,数据范围是[0-255]的,需要先经过ToTensor除以255归一化到[0,1]之后,再通过Normalize计算过后,将数据归一化到[-1,1]。
-
-
Resize函数
-
Resize函数的直接使用
# 重设大小,输入像素(512, 512) trans_resize = transforms.Resize((512, 512)) img_resize = trans_resize(img) # 转为tensor类型 img_resize_tensor = trans_tensor(img_resize) print(img_resize_tensor) # 放入tensorboard中 writer.add_image("Resize", img_resize_tensor, 0) -
compose函数使用
# 将图片缩放到512,长宽比保持不变 trans_resize_2 = transforms.Resize(512) # 下列解释:一般用Compose把多个步骤整合到一起 trans_compose = transforms.Compose([trans_resize_2, trans_tensor]) img_resize_2 = trans_compose(img) writer.add_image("Resize", img_resize_2, 1)- compose函数中的参数需要是一个列表,在compose中,数据需要的是transforms类型,所以compose函数的意义就是将其中的transforms按照次序依次执行
-
-
RandomCrop函数
-
使用
# 随机裁剪,输入值为size trans_random = transforms.RandomCrop([128, 128]) trans_compose_2 = transforms.Compose([trans_random, trans_tensor]) # 裁剪1000张图片 for i in range(1000): img_crop = trans_compose_2(img) writer.add_image("RandomCrop", img_crop, i)
-
Torchvision中的数据集使用
-
使用
import torchvision # 下载官网数据集 train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, download=True) test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, download=True) # 输出第一个数据集 print(test_set[0]) img, target = test_set[0] print(img) print(target) print(test_set.classes[target]) img.show() -
下载
DataLoader使用
-
使用
import torchvision from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter # 导入数据集 test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor()) # num_workers=0 表示只有一个主进程 # batch_size 表示每次要取64个数据组合 # drop_last 表示数据不足的时候就舍去 # shuffle true表示数据随机抓取第二轮 test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False) img, target = test_data[0] print(img.shape) print(target) writer = SummaryWriter("dataloader") # 循环加载test——loader中的数据 for epoche in range(2): step = 0 for data in test_loader: imgs, targets = data # print(imgs.shape) # print(targets) # 注意为images不是image # format()函数的作用是将数据格式化,即epoche为1的时候前面{}中即为1,并存放对应的数据 writer.add_images("epoche_{}".format(epoche), imgs, step) step += 1 writer.close()- 运行for循环的话就会重新调用test_loader,如果shuffle是True的话,那么bactch_size中的图片每个都不一样
神经网络基本骨架Moudle
-
Containers.moudle
import torch.nn as nn import torch.nn.functional as F class Model(nn.Module): def __init__(self): # 继承父类方法的构造函数 super().__init__() # 卷积 self.conv1 = nn.Conv2d(1, 20, 5) self.conv2 = nn.Conv2d(20, 20, 5) # 前向传播 def forward(self, x): x = F.relu(self.conv1(x)) return F.relu(self.conv2(x))-
前向传播
Input —> forward —> Output
-
实例应用
import torch from torch import nn # RJW神经网络 class RJW(nn.Module): # 继承父类 def __init__(self) -> None: super().__init__() # 前向传播,指定一个输入 def forward(self, input): output = input + 1 return output # 新建实例对象 rjw = RJW() # 输入一个tensor类型,torch.Tensor是存储和变换数据的主要工具。 # Tensor与Numpy的多维数组非常相似。 x = torch.tensor(1.0) output = rjw(x) print(output)
-
卷积相关知识的补充
-
卷积的组成:输入图像、卷积核
操作:将每一个位置对应相乘
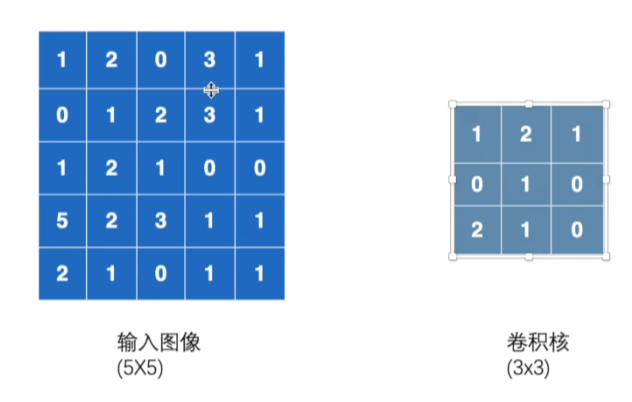
-
当Stride为1时卷积后的输出

-
实例使用
import torch import torch.nn.functional as F # 输入图像 input = torch.tensor([[1, 2, 0, 3, 1], [0, 1, 2, 3, 1], [1, 2, 1, 0, 0], [5, 2, 3, 1, 1], [2, 1, 0, 1, 1]]) # 设置卷积和 kernel = torch.tensor([[1, 2, 1], [0, 1, 0], [2, 1, 0]]) print(input.shape) print(kernel.shape) # 1个数据 1个通道 高度5 宽度5 input = torch.reshape(input, (1, 1, 5, 5)) kernel = torch.reshape(kernel, (1, 1, 3, 3)) print(input.shape) print(kernel.shape) # stride 步长 # conv2d 卷积 output = F.conv2d(input, kernel, stride=1) print(output) # padding 外边框补齐 # conv2d 卷积 output2 = F.conv2d(input, kernel, stride=1, padding=1) print(output2)
神经网络-卷积层
-
CONV2D
# in_channels 输入通道数 # out_channels 输出通道数等于卷积核数 # dilation 对应位 # groups 分组卷积 # bias 偏置 # padding_mode 填充模式 torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None) -
搭建自己的神经网络
import torch import torchvision.datasets from torch import nn from torch.utils.data import DataLoader from torch.nn import Conv2d from torch.utils.tensorboard import SummaryWriter # 设置数据集 dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(), download=True) dataloader = DataLoader(dataset, batch_size=64) # RJW网络类 class RJW(nn.Module): def __init__(self) -> None: super().__init__() # 设置网络,各个参数的含义不再赘述 self.conv1 = Conv2d(in_channels= 3, out_channels= 6, kernel_size= 3, stride= 1, padding= 0) def forward(self, x): x = self.conv1(x) return x rjw = RJW() # print(rjw) writer = SummaryWriter("../data/logs") step = 0 for data in dataloader: imgs, targets = data output = rjw(imgs) # 输出torch.Size([64, 3, 32, 32]) # 输出torch.Size([64, 6, 30, 30]) # 64:batch_size 3:out_channels 32:图像大小 print(imgs.shape) print(output.shape) writer.add_images("input", imgs, step) # -1指的是根据后边的值自动进行计算,其他参数同上 output = torch.reshape(output, (-1, 3, 30, 30)) writer.add_images("output", output, step) step += 1
神经网络-最大池化操作
-
最大池化操作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-avRprC6w-1668067221438)(https://cdn.jsdelivr.net/gh/cr7tywzrjw/images/img/202211041103384.png)]
- 参数详解
- Ceil_model:决定是不是要忽略边框部分,例如 5 ∗ 5 5*5 5∗5的输入图像中,利用 3 ∗ 3 3*3 3∗3的池化核进行池化,得到的输出有 2 ∗ 2 2*2 2∗2和 1 ∗ 1 1*1 1∗1两种差别
- Kernel_size:池化核的大小
- dtype:输入图像的数据类型
- 参数详解
-
池化调用函数
import torch from torch import nn from torch.nn import MaxPool2d input = torch.tensor([[1, 2, 0, 3, 1], [0, 1, 2, 3, 1], [1, 2, 1, 0, 0], [5, 2, 3, 1, 1], [2, 1, 0, 1, 1]], dtype=torch.float32) input = torch.reshape(input, (-1, 1, 5, 5)) print(input.shape) class RJW(nn.Module): def __init__(self) -> None: super().__init__() # 最大池化操作,输入必要参数 self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True) def forward(self, input): output = self.maxpool1(input) return output rjw = RJW() output = rjw(input) print(output) -
池化的作用:保留数据特征,减少数据量
-
Tensorboard中的效果展示
-
池化展现出的是每个图片的最大特征,同时数据量大小也能降低

-
神经网络-最大非线性激活操作
-
ReLU函数作用:激活函数是加入非线性因素,线性不能非常好的拟合现实的情况,加入非线性因素可以增强拟合的能力,否则模型泛化能力变差
-
ReLU函数的使用
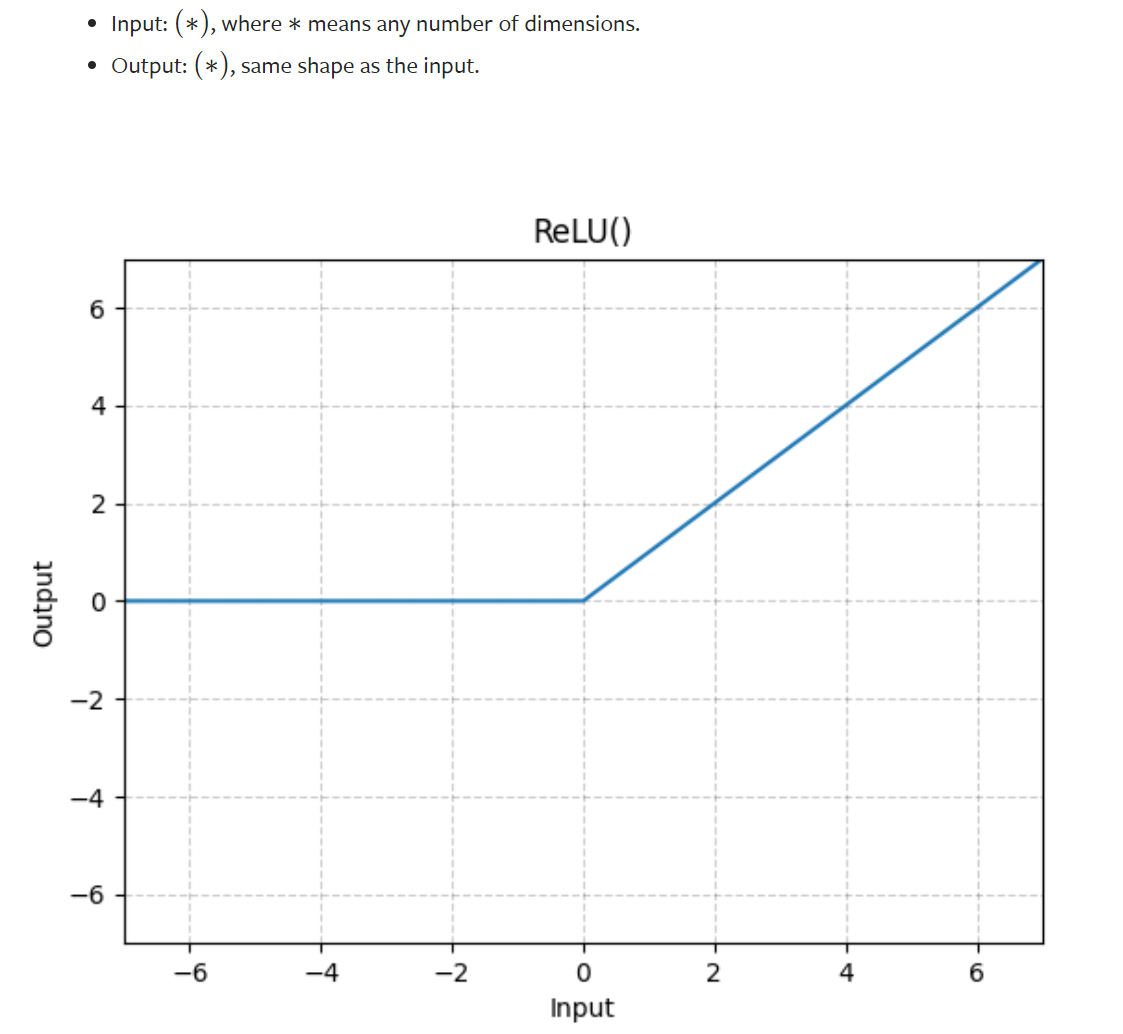
-
相似的-Sigmoid函数的使用
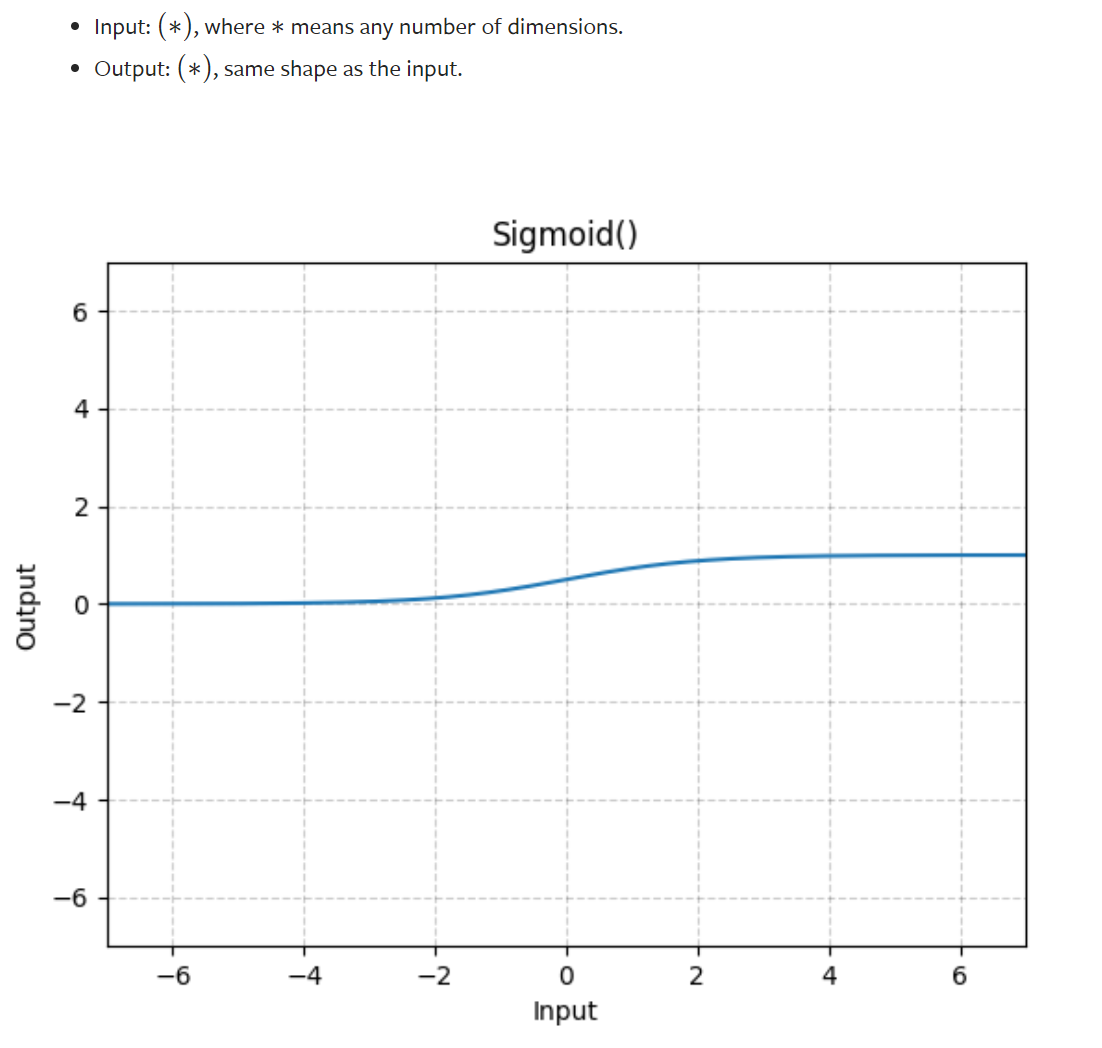
神经网络-线性层及其他
-
Linear函数-线性层
# 先利用output.reshape(1, 1, 1, -1) # 得到输出196608,有多少列 # 再使用Linear函数 def __init__(self) -> None: super().__init__() # 10:每一个输出图像的大小 self.linear1 = Linear(196608, 10) -
torch.flatten函数
-
替代torch.reshape函数
output = torch.flatten(imgs)
-
神经网络实战
-
神经网络实现实战

-
根据公式计算神经网络参数

-
代码实现
-
未加入Sequential

-
加入Sequential
self.model1 = Sequential( Conv2d(3, 32, 5, padding=2), MaxPool2d(2), Conv2d(32, 32, 5, padding=2), MaxPool2d(2), Conv2d(32, 64, 5, padding=2), MaxPool2d(2), Flatten(), Linear(1024, 64), Linear(64, 10) ) -
整体实现
import torch from torch import nn from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential from torch.utils.tensorboard import SummaryWriter class RJW(nn.Module): def __init__(self) -> None: super().__init__() self.model1 = Sequential( Conv2d(3, 32, 5, padding=2), MaxPool2d(2), Conv2d(32, 32, 5, padding=2), MaxPool2d(2), Conv2d(32, 64, 5, padding=2), MaxPool2d(2), Flatten(), Linear(1024, 64), Linear(64, 10) ) def forward(self, x): x = self.model1(x) return x rjw = RJW() print(rjw) print("----------------------------") input = torch.ones((64, 3, 32, 32)) output = rjw(input) print(output.shape) writer = SummaryWriter("logs_nn_network") writer.add_graph(rjw, input) writer.close() -
引入实际的数据集进行实现
import torchvision from torch import nn from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear from torch.utils.data import DataLoader dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(), download=True) dataloader = DataLoader(dataset, batch_size=1) class RJW(nn.Module): def __init__(self) -> None: super().__init__() self.model1 = Sequential( Conv2d(3, 32, 5, padding=2), MaxPool2d(2), Conv2d(32, 32, 5, padding=2), MaxPool2d(2), Conv2d(32, 64, 5, padding=2), MaxPool2d(2), Flatten(), Linear(1024, 64), Linear(64, 10) ) def forward(self, x): x = self.model1(x) return x rjw = RJW() for data in dataloader: imgs, targets = data outputs = rjw(imgs) print(outputs) # print(imgs) print(targets) print("---------------")-
在实际的数据集中输出结果如下所示
tensor([[-0.0630, 0.0902, 0.0604, 0.0883, -0.0663, 0.0701, -0.0184, -0.0324,
-0.0339, -0.1069]], grad_fn=)tensor([1])
其中,-0.0630、0.0902等等数据,为通过卷积、池化等一系列操作由网络计算出的数据,tensor([1])的具体含义为第1类的图片同目标图片最为匹配即,0.0902在同一组数据中最大。
-
-
损失函数
-
Loss的作用
- 计算实际输出和目标之间的差距
- 为我们更新输出提供一定的依据,即反向传播
-
L1Loss函数与MSELoss函数应用举例
import torch from torch.nn import L1Loss, MSELoss inputs = torch.tensor([1, 2, 3], dtype=torch.float32) targets = torch.tensor([1, 2, 5]) inputs = torch.reshape(inputs, (1, 1, 1, 3)) targets = torch.reshape(targets, (1, 1, 1, 3)) # 将相差的加起来取平均 # loss = L1Loss() # 将相差的值加起来 loss = L1Loss(reduction='sum') # 每个取平方再加起来取平均 loss_mse = MSELoss() result = loss(inputs, targets) result_mse = loss_mse(inputs, targets) print(result) print(result_mse) -
CrossEntropyLoss函数的使用
- CrossEntropyLoss函数详解
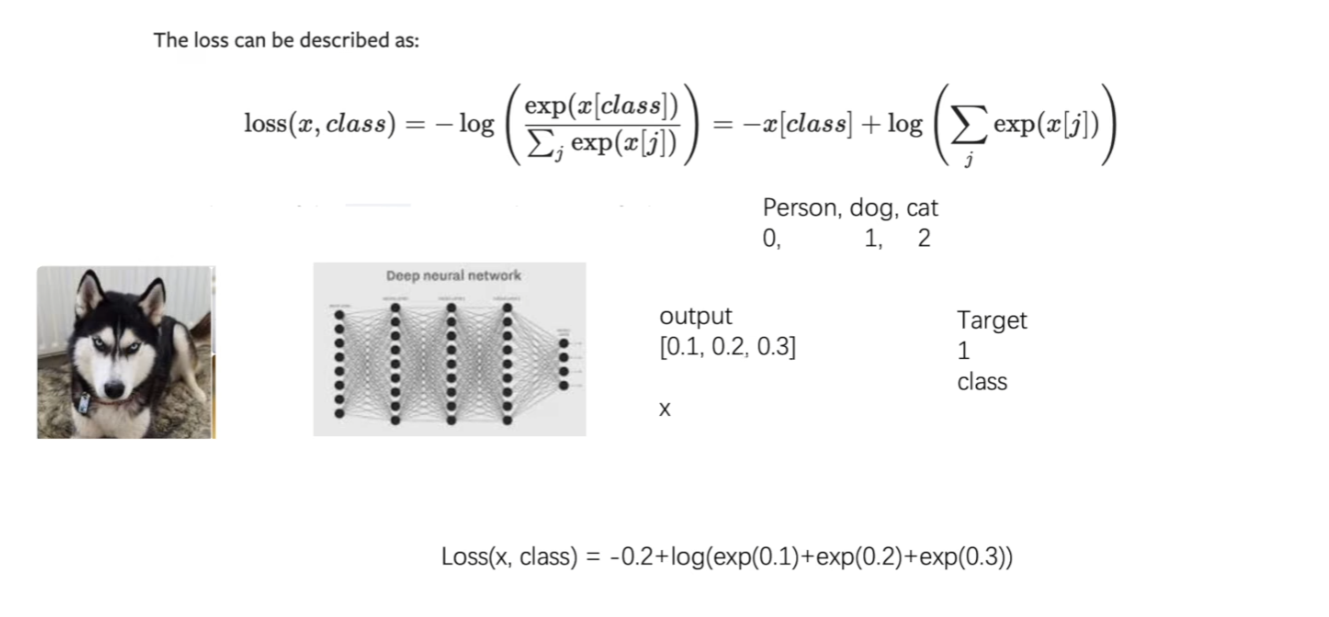
-
只有当命中的时候,即对应的x[class]的值取到比较大的时候,Loss函数才比较小。
-
output输出相当于对Person和dog和cat的值的预测,如果输出结果相差不大,那么意味着分类器性能较低。
-
Target的值就是class的值,其为实际过程中给出的,1则为针对dog的预测结果
-
实例使用
x = torch.tensor([.1, .2, .3]) y = torch.tensor([1]) x = torch.reshape(x, [1, 3]) loss_cross = nn.CrossEntropyLoss() result_cross = loss_cross(x, y) print(result_cross)
-
神经网络实战和Loss函数结合
# 引入loss函数,看每一次的loss具体有多少 loss = nn.CrossEntropyLoss() for data in dataloader: imgs, targets = data outputs = rjw(imgs) # 输入outputs即输出的结果 # 输入target目标结果进行匹配 # 观察最后的输出结果有多少偏差 result = loss(outputs, targets) print(result) # 输出: # tensor(2.2747, grad_fn=<NllLossBackward0>) # 相差2.2747,这个值越小越好 -
梯度Grad的概念
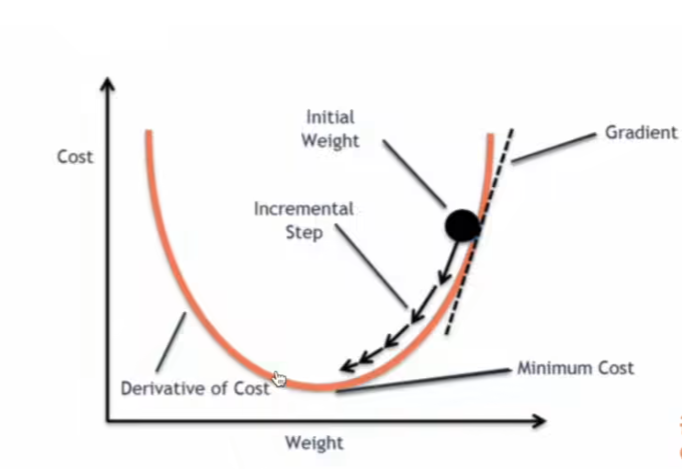
- 梯度的示意图:图中所示的Gradient为梯度,点Weight的位置每次都可以根据该梯度Gradient来进行一个自动的调整。
优化器
-
优化器的必要步骤
for input, target in dataset: # 必须清零,防止上一步参数对本步产生的影像 optimizer.zero_grad() output = model(input) loss = loss_fn(output, target) loss.backward() optimizer.step() -
优化器的使用
rjw = RJW() # lr:学习的速率 # parmeters:神经网络基本参数 optim = torch.optim.SGD(rjw.parameters(), lr=0.01) loss = nn.CrossEntropyLoss() for epoche in range(1, 10): # 做一个结果展示 running_loss = 0.0 for data in dataloader: imgs, targets = data outputs = rjw(imgs) result = loss(outputs, targets) # 清零 optim.zero_grad() # 得到了每一个参数对应梯度 result.backward() # 调用优化器的step()函数计算 optim.step() running_loss += result print(running_loss)
VGG16网络模型的修改与添加
-
参数pretrained 为false和true时的区别
vgg16_false = torchvision.models.vgg16(pretrained = False)
#False,下载的是网络模型,默认参数vgg16_true = torchvision.models.vgg16(pretrained = True)
#True,下载的是网络模型,并且在数据集上面训练好的参数。 -
网络模型的修改
-
VGG16网络模型
VGG( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): ReLU(inplace=True) (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (3): ReLU(inplace=True) (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (6): ReLU(inplace=True) (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (8): ReLU(inplace=True) (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (13): ReLU(inplace=True) (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (15): ReLU(inplace=True) (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (18): ReLU(inplace=True) (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (20): ReLU(inplace=True) (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (22): ReLU(inplace=True) (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (25): ReLU(inplace=True) (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (27): ReLU(inplace=True) (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (29): ReLU(inplace=True) (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) ) (avgpool): AdaptiveAvgPool2d(output_size=(7, 7)) (classifier): Sequential( (0): Linear(in_features=25088, out_features=4096, bias=True) (1): ReLU(inplace=True) (2): Dropout(p=0.5, inplace=False) (3): Linear(in_features=4096, out_features=4096, bias=True) (4): ReLU(inplace=True) (5): Dropout(p=0.5, inplace=False) (6): Linear(in_features=4096, out_features=1000, bias=True) # 局部添加 (add_linear): Linear(in_features=1000, out_features=10, bias=True) ) # 整体添加 (add_linear): Linear(in_features=1000, out_features=10, bias=True) ) -
针对整体添加一个线性层
vgg16_true.add_module("add_linear", nn.Linear(1000, 10)) # (add_linear): Linear(in_features=1000, out_features=10, bias=True) -
针对classifier添加一个线性层
vgg16_true.classifier.add_module("add_linear", nn.Linear(1000, 10)) # (add_linear): Linear(in_features=1000, out_features=10, bias=True) -
局部修改
vgg16_false.classifier[6] = nn.Linear(4096, 10) # (6): Linear(in_features=4096, out_features=10, bias=True)
-
网络模型的保存与训练
-
模型保存与加载方式合集
-
保存方式1与对应的加载方式
# 保存的是模型的结构和模型的参数 torch.save(vgg16, "vgg16_method1.pth") model = torch.load("vgg16_method1.pth") print(model) -
保存方式2
# 只保存模型参数 torch.save(vgg16.state_dict(), "vgg16_method2.pth") # 加载 vgg16 = torchvision.vgg16(pretrained=False) vgg16.load_state_dict(torch.load("vgg16_method2.pth")) print(vgg16)
-
-
网络训练状态和测试状态开始
# 训练 rjw.train() # 测试 rjw.eval()
利用GPU进行训练
-
需要对原有代码进行改进
GPU可以进行加速的环节:
1. 网络模型本身 2. 数据本身(包括输入以及标注) 3. 损失函数 -
使用方法:
-
方法1
if torch.cuda.is_avaiable(): imgs = imgs.cuda() -
方法2
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") imgs = imgs.to(device)
-
-
免费开源的训练平台:Google Colab
-
With关键字
With的出现可以自动的处理对文件的关闭操作,更加节约性能
-
跑模型需要注意的点(删除Required=True,意思就是不需要手动输入参数“–dataroot /…/…”)
















 1483
1483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









