







「高级java工程师」常见面试题及其答案:
「高级java工程师」常见面试题及其答案(持续更新)_好人老李的博客-CSDN博客
目录
String、StringBuffer和StringBuilder的区别?
synchronized与ReentrantLock的区别?
Spring、SpringMVC、SpringBoot的关系?
java基础
面向对象与面向过程的区别?
面向过程(Procedure xx,简称POP)的思想是:
分析解决问题需要哪些步骤 → 每一个步骤使用函数实现 → 依次调用函数来解决问题
以「把大象搬进冰箱」这个经典问题为例,面向过程的解决思路:

-
解决问题分3步:打开冰箱 → 搬大象 → 关闭冰箱
-
设计对应的方法:openFridge()、moveElephant()、closeFridge()
-
依次调用
int main() {
openFridge();
moveElephant();
closeFridge();
}面向对象(Object xx,简称OOP)的思路是:
分析问题由哪些对象组成 → 使用类实现每一个对象 → 调用对象的方法来解决问题
还是以「把大象搬进冰箱」为例:
-
这个问题有涉及2个对象,冰箱和大象
-
使用类实现冰箱和大象,冰箱要具备开门和关门的能力,大象要具备走路的能力
-
实例化冰箱和大象,调用对象的方法就可以解决问题
class Elephant{
public static void walkInto(target){}
}
class Fridge{
public static void open(){ }
public static void close(){ }
}
class APP{
public static void main(String[] args){
Fridge.open(); //冰箱开门
Elephant.walkInto(Fridge); //大象走进冰箱
Fridge.close(); //冰箱关门
}
}面向过程和面向对象的区别:
面向过程:
-
优点:性能好,面向对象需要先对类进行实例化,再调用对象的方法,面向过程直接调用函数
-
缺点:复用性差,扩展性差
面向对象:
-
优点:面向对象有封装、继承、多态的特性,易复用、易扩展
-
缺点:性能相对差一些,一般来说java程序执行速度比C慢10倍
JRE、JDK、JVM的区别?
- JDK:Java Development Kit,是一个工具包,用于开发和运行Java程序,包含了java开发工具和JRE。
- JRE:Java Runtime Environment,提供了一个java程序的运行环境。
- JVM:Java 虚拟机,负责执行 Java 程序。
总结:JDK包含JRE,JRE包含JVM。
java的数据类型有哪些?
java的数据类型有两种:
- 基本数据类型
- 引用数据类型
基本数据类型又包括四类8种:
- 整数型:byte 1字节 [-128~127],short 2字节,int 4字节,long 8字节
- 浮点型:float 4字节,double(默认) 8字节
- 字符型:char,2字节,unicode编码值
- 布尔型:boolean,1字节,值只有true和false
重写和重载的区别?
- 重载:overloading,发生在类内部,方法名相同,参数不同。
- 重写:overriding,是子类对父类的方法进行重写, 返回值和形参不能改变。
- 重写和重载是java多态性的不同表现形式
java创建对象有几种方式?
1. new
Person person = new Person(18);2. Class.newInstance
Class person = Person.class;
Person person = null;
try {
person = (Person) person.newInstance();
} catch (Exception e) {
e.printStackTrace();
}3. 反序列化(比较耗内存)
Person person = new Person("fsx", 18);
byte[] bytes = SerializationUtils.serialize(person);
Object deserPerson = SerializationUtils.deserialize(bytes);4. clone()(对象必须实现Cloneable接口,并重写clone方法)
Person person1 = new Person(18);
Person person2 = person1.clone();反射
什么是反射?有什么作用?
什么是反射:反射是java的一种机制,可以在运行态,获取任意一个类的所有属性和方法,可以用来创建对象、调用方法、对属性进行赋值。
Class<?> clz = Class.forName("xxx.User");
Object object = clz.newInstance();反射的优缺点?
反射的优点:能够在运行时动态获取类的实例,提高了程序的灵活性
反射的缺点:反射机制中包括了一些动态类型,JVM无法对反射代码进行优化,因此性能较差,对性能要求高的程序尽量少用反射。
==和equals()的区别?
==:引用是否相同,是不是指向同一个内存空间
equals():值是否相同,所指向的内存空间的值是不是相同
String a = new String("123");
String b = new String("123");
a == b //false
a.equals(b) //truefinal、finally、 finalize 的区别?
- final:java的1个关键字,代表最终。如果一个类被声明为final,它不能被继承;如果变量声明为final,给定初始值后,不可修改;如果方法声明为final,不能被重载。
- finally:java的一种异常处理机制,finally代码总会执行。
- finalize:java中的一个方法名,在Object类中定义,因此所的类都继承了它,finalize()方法在垃圾收集器删除对象之前对会被调用。
String
String类为什么设计成不可变?
- 字符串常量池:字符串常量池(String pool) 是Java堆内存中的一个特殊存储区域,当创建一个String对象时,如果此字符串值已存在于常量池,则不会创建一个新的对象,而是引用已经存在的对象,达到复用的效果。String类如果可变,常量池就不支持了。
-
效率:String对象经常会被比较,如果不可变,String对象的哈希码就可以被缓存,不必每次都计算哈希码,提升性能。
-
安全:String经常用做重要参数使用,例如URL、文件路径等,如果可变,会有安全隐患。
String、StringBuffer和StringBuilder的区别?
- String是一个字符串常量,不可改变;StringBuffer和StringBuilder是字符串变量,可以改变,但StringBuffer是线程安全的,StringBuilder是非线程安全的。
- 如何选择?如果修改少,使用String;如果在多线程下经常修改,使用SreingBuffer;如果是单线程下经常修改,使用StringBuilder。
异常
java常见的异常类型有哪些?有什么区别?
java异常的顶层类是Throwable,他的子类是:Error和Exception。
Error:运行时环境错误,如:内存溢出、系统崩溃等,程序无法恢复。
Exception:可捕获且可恢复的异常,Exception又分为两类:
- CheckedException(可检查异常/编译时异常):可检查异常需要在源代码里显式地使用try catch捕获,否则编译不过。如IOException、SQLException等。
- RuntimeException(不可检查异常/运行时异常):运行时异常是可能被程序员忽略的异常。如:ArrayIndexOutOfBoundsException(数组下标越界)、NullPointerException(空指针异常等。
IO
BIO、NIO、AIO 有什么区别?
先了解下1个IO请求的处理过程:
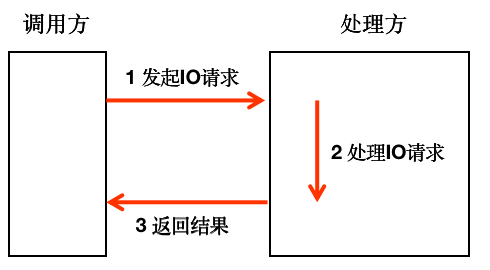
同步和异步的区别:同步和异步,是处理方处理IO请求的2种方式,同步是指IO处理线程会一直等待相关的IO数据就绪后再执行逻辑处理,异步是指IO处理线程不会一直等待相关的IO数据就绪,比如可以轮询查看相关IO数据是否已经准备OK。
阻塞和非阻塞的区别:阻塞和非阻塞,是调用方的2种IO请求方式,阻塞是指调用方一直等待处理方的结果,非阻塞是调用方不会一直等待处理方的结果,可以先去执行其他任务,过一段时间再来查看结果是否返回。
BIO:Blocking IO,同步阻塞IO。调用方发起IO请求后,会一直阻塞等待结果返回,同时处理方会一直等到IO数据就绪后,再进入处理。优点:一请求一应答的方式,逻辑简单,易实现。缺点:大量等待,性能很差。
NIO:Non-Blocking IO,同步非阻塞IO。调用方发起IO请求后,会一直阻塞等待结果返回。IO处理线程不会原地等待IO数据,可以先做其他事情,定时轮询检查IO数据是否就绪。
AIO:异步非阻塞IO。调用方发起IO请求后,不会等待结果,先处理其他事情,处理方执行完操作后利用系统函数告知调用方结果。IO处理线程不会原地等待IO数据,可以先做其他事情,定时轮询检查IO数据是否就绪。
序列化和反序列化
什么是序列化和反序列化?
序列化是指将对象写入IO流,反序列化是指从IO流中恢复对象。
序列化的作用?
- 远程传输对象
- 持久化保存对象
什么是serialVersionUID?
- serialVersionUID是序列化的版本号, 序列化时,其值与数据一起存储;反序列化时,将检查序列化数据是否与当前类版本匹配。
- 实现Serializable接口的类都有一个表示序列化版本标识符的静态变量,缺少serialVersionUID时,IDE会发出警告。
如何生成serialVersionUID?
- 使用默认值:private static final long serialVersionUID = 1L;
- 自动生成: private static final long serialVersionUID = 4603642343377807741L;
- 看诉求:如果希望类的不同版本序列化时兼容,需确保类的不同版本具有相同的serialVersionUID;如果不希望类的不同版本序列化时兼容,需确保类的不同版本具有不同的serialVersionUID。
如何实现序列化?
注意:JavaBean实体类必须实现Serializable接口,否则无法序列化。
public class User implements Serializable {
private static final long serialVersionUID = -7890663945232864573L;
private String userName;
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
@Override
public String toString() {
return "User [userName=" + userName + ", passWord=" + passWord + "]";
}
}方式1:IO流序列化
Java原生序列化方法是指通过 InputStream 和 OutputStream 之间的转化进行序列化和反序列化。
User u = new User();
u.setUserName("张三");
// 序列化
ByteArrayOutputStream out = new ByteArrayOutputStream();
ObjectOutputStream obj = new ObjectOutputStream(out);
obj.writeObject(u);
// 反序列化
ObjectInputStream ois = new ObjectInputStream(new BufferedInputStream(
new java.io.ByteArrayInputStream(out.toByteArray())));
User user = (User) ois.readObject();方式2:jackson序列化
大多数公司都将json作为服务器端返回的数据格式,Json序列化一般会使用jackson包。
import com.fasterxml.jackson.databind.ObjectMapper;
User u = new User();
u.setUserName("张三");
// 序列化
ObjectMapper mapper = new ObjectMapper();
byte[] writeValueAsBytes = null;
writeValueAsBytes = mapper.writeValueAsBytes(u);
// 反序列化
User user = mapper.readValue(writeValueAsBytes, User.class);方式3:FastJson/Gson
fastjson是由阿里巴巴开源的Json解析器和生成器,不过安全漏洞多,不建议使用,推荐使用Google的Gson。
集合
ArrayList和LinkedList的区别?
- 都是对List接口的实现,但一个底层是Array(动态数组),一个是Link(链表)
- 随机访问时(get和set操作),ArrayList比LinkedList的效率更高,因为LinkedList是线性的数据存储方式,所以需要移动指针从前往后依次查找。
- 对数据进行增加和删除的操作时(add和remove操作),LinkedList比ArrayList的效率更高,因为ArrayList是数组,所以在其中进行增删操作时,会对操作点之后所有数据的下标索引造成影响,需要进行数据的移动。
HashMap 的工作原理?
HashMap是Map接口的一种实现,用于存储K-V数据结构的元素。
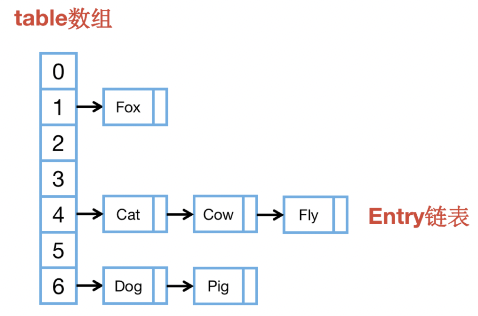
HashMap的数据结构:
-
JDK7,HashMap的内部数据结构是数组+链表:
-
JDK8开始,当链表长度 > 8时会转化为红黑树,当红黑树元素个数 ≤ 6时会转化为链表。
put元素的原理:
-
计算K的hash值:hash = (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16)
-
计算K的数组位置:index = hash & (length - 1)
-
如果有相同K,则覆盖V
-
如果没有相同K,JDK7采用头插法(刚添加的元素被访问的概率大),但会引入循环引用问题,导致CPU高,JDK8开始采用尾插法,避免了这个问题。
-
如果元素个数超过阈值,进行扩容或数据结构变更(链表 → 红黑树)的操作。
get元素的原理:
-
计算K的hash值
-
计算K的数组index值
-
遍历寻找元素
HashMap的扩容机制?
什么时候扩容?
当元素数量超过阈值时扩容,阈值 = 数组容量 * 加载因子,数组容量默认16,加载因子默认0.75,所以默认阈值12。
为什么容量必须是2的幂?
计算K的数组位置公式:index = h & (length-1),由于2的幂次方-1都是1,这样运算时就可以充分利用到数据的高低位特点,减少hash冲突的概率,提升存取效率。
扩容的原理:
-
创建新数组,容量翻倍
-
旧数组元素迁移到新数组
ConcurrentHashMap工作原理?
HashMap线程不安全,多线程环境可以使用Collections.synchronizedMap、HashTable实现线程安全,但性能不佳。ConurrentHashMap比较适合高并发场景使用。
ConcurrentHashMap JDK7实现原理:
数据结构:
-
ConcurrentHashMap由一个Segment数组构成(默认长度16&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









