






目的
快速浏览新闻
项目:
利用华尔街日报(wsj)的RSS上看新闻,不需要第三方的应用程序,用网页展示。
把codes 放到 Nas Container/Docker ,可以随用浏览器看到内容,定时更新。
工具: laptop windows11, docker, qnap nas + app container, python
后面还想加入其它的,琢磨Twitter去了。
数据来源
华尔街日报WSJ 的数字分享
https://www.wsj.com/news/rss-news-and-feeds

在Opinion 观点, World News 全球新闻 等上点右鼠标右键获得 links
应用简介
基于 Flask 框架开发的网页应用,用于处理和展示 RSS 源的内容。通过自动抓取特定的 RSS 源,它将新闻文章转换为 CSV 文件并呈现在网页上。应用程序集成了多个 Python 库,如 pandas、feedparser 和 googletrans,来处理数据和翻译内容。
主要组件:
2个文件
-
主程序 (app.py)
-
rss2csv (rss_to_csv.py)
核心功能
-
RSS 内容抓取与转换: 通过
rss_to_csv.py脚本,该应用程序会自动抓取指定的 RSS 源内容,并将其转换为 CSV 文件。每次运行时,都会过滤重复的内容,并且按时间顺序对数据进行排序。最终的 CSV 文件会存储在指定目录中。 -
多源支持: 该应用程序支持多个 RSS 源,例如
WSJ World News、WSJ US Business等。不同来源的内容可以汇总到同一 CSV 文件中,每天生成一个新文件。 -
自动刷新与本地展示: 应用程序通过 Flask 服务器在本地运行,用户可以通过浏览器访问网页来查看最新的 RSS 源内容。网页每隔 2.1 小时会自动刷新,确保用户看到的内容是最新的。此外,应用程序支持高亮显示特定关键字,例如 "China" 或 "Chinese",以方便用户快速定位重要内容。
-
本地时间显示与时区转换: 应用程序会将新闻发布的时间从纽约时间转换为用户电脑的本地时间,这样用户可以更直观地了解每篇文章的发布时间。
-
CSV 文件管理: 每天会生成一个新的 CSV 文件,应用程序会自动删除 7 天之前的文件,以确保目录不会被过时文件占用太多空间。
用到技术
- Flask:用于构建应用的网页框架。
- Pandas:用于处理 RSS 源抓取后的数据,转换为 CSV 文件格式。
- Feedparser:用于解析 RSS 源。
- Googletrans:用于将文章内容翻译为中文。
- Docker:应用程序最终将在 Docker 中运行,确保环境的一致性和便捷的部署。
复制全部代码,配置所需环境,放在对应的目录下面,即可使用。
CODING 已经调整为在Linux下执行!
目录结构
rss_to_csv/ # 项目根目录
│
├── Dockerfile # Docker 配置文件
├── requirements.txt # Python 依赖库列表
├── rss_to_csv.py # RSS 抓取和CSV生成的核心脚本
├── app.py # Flask 应用程序主文件,负责展示RSS内容
│
└── rss_project/csv_files/ # 存储生成的CSV文件的目录
└── wsj_YYYY-MM-DD-hhmm.csv
目录说明:
- rss_project/:项目根目录,包含应用的所有主要文件。
- Dockerfile:用于定义 Docker 容器的配置,包括基础镜像、安装的依赖等。
- requirements.txt:列出项目需要的所有 Python 库和它们的版本(例如 Flask、pandas、feedparser、googletrans 等)。
- rss_to_csv.py:该脚本负责从指定的 RSS 源抓取内容,并将其转换为 CSV 文件。
- app.py:这是 Flask 应用的核心文件,运行时会启动本地服务器,通过网页展示 RSS 内容,并执行 CSV 文件的读取和自动更新操作。
- rss/:这个目录存储所有生成的 CSV 文件,每天一个 CSV 文件,文件名格式为
wsj_YYYY-MM-DD-hhmm.csv。
完整代码
这是我的第一个python coding: rss_to_csv.py
功能:负责抓取 RSS 内容并生成 CSV 文件。
rss_to_csv.py 代码:
注意:这段代码是在QNAP NAS的Docker 上运行,已经把目录改为 Linux 格式。如果你在Windows上运行,需要更改所有,有关路径的表达!
需要修改这段:csv_directory = '/usr/src/app/rss_project/csv_files'
import os
import feedparser
import pandas as pd
from deep_translator import GoogleTranslator
from datetime import datetime
# 设置 CSV 文件的目录
csv_directory = '/usr/src/app/rss_project/csv_files'
os.makedirs(csv_directory, exist_ok=True)
# 初始化翻译器
translator = GoogleTranslator(source='en', target='zh-CN')
# 定义 RSS 源
rss_feeds = [
"https://feeds.a.dj.com/rss/RSSOpinion.xml",
"https://feeds.a.dj.com/rss/RSSWorldNews.xml",
"https://feeds.a.dj.com/rss/WSJcomUSBusiness.xml",
"https://feeds.a.dj.com/rss/RSSMarketsMain.xml",
"https://feeds.a.dj.com/rss/RSJD.xml"
]
# 获取当前时间并生成 CSV 文件名
current_time = datetime.now().strftime("%Y-%m-%d-%H%M")
csv_file_name = f"wsj_{current_time}.csv"
csv_file_path = os.path.join(csv_directory, csv_file_name)
# 初始化数据列表
data = []
# 遍历每个 RSS 源并提取信息
for feed in rss_feeds:
d = feedparser.parse(feed)
for entry in d.entries:
title = entry.title
summary = entry.summary
link = entry.link
published = entry.published
try:
# 使用 deep_translator 翻译标题和摘要
translated_title = translator.translate(title)
translated_summary = translator.translate(summary)
except Exception as e:
print(f"翻译失败: {e}")
translated_title = title
translated_summary = summary
# 将翻译后的内容与原始内容合并
full_title = f"{title}\n{translated_title}"
full_summary = f"{summary}\n{translated_summary}"
# 添加到数据列表
data.append([published, link, full_title, full_summary])
# 将数据保存到 CSV 文件
df = pd.DataFrame(data, columns=["Published", "Link", "Title", "Summary"])
df.to_csv(csv_file_path, index=False, encoding='utf-8')
print(f"RSS内容已保存到 {csv_file_path}")
复制上面代码即可,下面是代码段的解释。
代码描述:
# 如果这代码对你有用,你需要安装 import 后面这些所有必要的库,如果已经安装过,要更新到2023.9月的版本。
import os # 用于操作文件和目录
import feedparser #用于解析RSS源
import pandas as pd #用于数据处理和将数据保存为CSV格式
from deep_translator import GoogleTranslator #用于将RSS内容从英文翻译成中文
from datetime import datetime #用于获取当前时间,以便生成带有时间戳的CSV文件名
# 设置 CSV 文件的目录 这些代码的目录位置已经是按照 linux 调整,因为要跑在Docker里
csv_directory = '/usr/src/app/rss_project/csv_files'
os.makedirs(csv_directory, exist_ok=True)
# 初始化翻译器
translator = GoogleTranslator(source='en', target='zh-CN')
# 定义 5个 RSS 源
rss_feeds = [
"https://feeds.a.dj.com/rss/RSSOpinion.xml",
"https://feeds.a.dj.com/rss/RSSWorldNews.xml",
"https://feeds.a.dj.com/rss/WSJcomUSBusiness.xml",
"https://feeds.a.dj.com/rss/RSSMarketsMain.xml",
"https://feeds.a.dj.com/rss/RSJD.xml"
]
# 获取当前时间 并将其格式化为“年-月-日-小时分钟”的格式 并生成 CSV 文件名 避免重复,以后定期用程序删除, 我在app.py cooding写的是保留7天。
current_time = datetime.now().strftime("%Y-%m-%d-%H%M")
csv_file_name = f"wsj_{current_time}.csv"
csv_file_path = os.path.join(csv_directory, csv_file_name)
# 初始化数据列表 准备一个空列表来存储RSS源中提取的内容。
data = []
# 遍历每个 RSS 源并提取信息 然后从中提取每个entry的信息,如标题、摘要、链接和发布时间
for feed in rss_feeds:
d = feedparser.parse(feed)
for entry in d.entries:
title = entry.title
summary = entry.summary
link = entry.link
published = entry.published
try:
# 使用 deep_translator 翻译标题和摘要 尝试使用翻译器将标题和摘要从英文翻译成中文。如果翻译过程中发生异常,程序会输出错误信息,并继续使用原始内容。 最开始用 googletrans 开始没问题,后来频繁报错,换成了这个。 也是免费的。 如果要很好的翻译,推荐用AI,如Chatgpt
translated_title = translator.translate(title)
translated_summary = translator.translate(summary)
except Exception as e:
print(f"翻译失败: {e}")
translated_title = title
translated_summary = summary
# 将翻译后的内容与原始内容合并成一个完整的条目,以换行符分隔。
full_title = f"{title}\n{translated_title}"
full_summary = f"{summary}\n{translated_summary}"
# 将每条RSS信息(发布时间、链接、标题和摘要)存储在data列表中
data.append([published, link, full_title, full_summary])
# 将数据保存到 CSV 文件 文件名带有时间戳
df = pd.DataFrame(data, columns=["Published", "Link", "Title", "Summary"])
df.to_csv(csv_file_path, index=False, encoding='utf-8')
print(f"RSS内容已保存到 {csv_file_path}") #程序最后输出CSV文件已保存的提示信息
rss_to_csv.py 小结:
wsj 提供了多个RSS源,汇总到一个表里再做整理。 因为是英文内容,书读得少,需要看中文方便阅读。
我把题目Titile与汇总Summary 做了双语显示(英+中),在捕捉内容时同时翻译,一同存入csv文件中,这样虽然增加了执行时间,但后面的主程序来处理内容会很容易。
CSV 文件的快速浏览
目录在docker里位置:/usr/src/app/rss/


小记:
代码半天不到就拼完了,并上了windows Docker 都好好的。 没有字体,格式等问题。当转到 QNAP Nas Docker/Container上后,已经用了一天时间才搞定。 现在的代码已经是 linux 调整后的。
主程序 app.py
通过 Flask 运行的网页应用,展示 CSV 数据,执行抓取和更新任务。
app.py 代码
import os
import threading
import time
import pandas as pd
from flask import Flask, render_template_string
from datetime import datetime, timedelta
import subprocess
# 初始化 Flask 应用
app = Flask(__name__)
# 设置 CSV 文件的目录
csv_directory = '/usr/src/app/rss_project/csv_files'
rss_script_path = '/usr/src/app/rss_to_csv.py'
#csv_directory = r'Z:\2024-MyProgramFiles\rss_project\rss_project\csv_files'
#rss_script_path = r'Z:\2024-MyProgramFiles\rss_project\rss_to_csv.py'
os.makedirs(csv_directory, exist_ok=True)
# 定时运行 rss_to_csv.py
def run_rss_script():
while True:
subprocess.run(['python', rss_script_path])
cleanup_old_files() # 每次运行完脚本后清理旧文件
time.sleep(7200) # 每2小时运行一次
# 清理超过7天的 CSV 文件
def cleanup_old_files():
now = datetime.now()
cutoff = now - timedelta(days=7)
for filename in os.listdir(csv_directory):
if filename.startswith("wsj_") and filename.endswith(".csv"):
file_path = os.path.join(csv_directory, filename)
file_time = datetime.fromtimestamp(os.path.getmtime(file_path))
if file_time < cutoff:
os.remove(file_path)
print(f"删除旧文件: {filename}")
# 在 Flask 应用启动前运行一次 rss_to_csv.py
subprocess.run(['python', rss_script_path])
# 启动定时任务
threading.Thread(target=run_rss_script, daemon=True).start()
# 自定义 HTML 模板,设置标题为 "The Wall Street Journal"
HTML_TEMPLATE = """
<!doctype html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>The Wall Street Journal</title> <!-- 设置网页标题 -->
<style>
body {
font-family: Arial, sans-serif;
line-height: 1.5;
color: #333;
background-color: #f5f5f5;
margin: 0;
padding: 20px;
}
.header {
display: flex;
justify-content: space-between;
align-items: center;
margin-bottom: 20px;
}
.file-info {
font-weight: bold;
font-size: 18px;
}
.refresh-btn-container {
display: flex;
align-items: center;
}
.refresh-btn {
padding: 8px 16px;
background-color: #4CAF50;
color: white;
border: none;
cursor: pointer;
border-radius: 4px;
font-size: 14px;
}
.refresh-btn:hover {
background-color: #45a049;
}
.countdown {
margin-left: 10px;
font-size: 14px;
color: #555;
}
.current-time {
font-size: 16px;
font-weight: bold;
}
table {
width: 100%;
border-collapse: collapse;
margin-bottom: 20px;
}
th, td {
padding: 8px 12px;
border: 1px solid #ddd;
text-align: left;
white-space: pre-line; /* 支持换行显示 */
}
th {
background-color: #f4f4f4;
font-weight: bold;
}
tr:nth-child(even) {
background-color: #f9f9f9;
}
.highlight {
background-color: yellow;
}
.url-cell {
max-width: 100px; /* 将 URL 列的最大宽度设置为100px */
word-wrap: break-word; /* 强制换行 */
overflow-wrap: break-word;
}
.url-container {
display: inline-flex; /* 确保 URL 和按钮在同一行 */
align-items: center;
}
.copy-btn {
margin-left: 10px;
padding: 5px 10px;
font-size: 12px;
cursor: pointer;
}
</style>
</head>
<body>
<div class="header">
<div class="file-info">文件名: {{ file_name }}</div>
<div class="refresh-btn-container">
<button class="refresh-btn" onclick="location.reload();">刷新页面</button>
<div class="countdown">下次刷新倒计时: <span id="countdown">120</span> 秒</div>
</div>
<div class="current-time">当前时间: <span id="currentTime"></span></div>
</div>
<table>
<thead>
<tr>
<th>发布时间</th>
<th>URL</th>
<th>标题</th>
<th>摘要</th>
</tr>
</thead>
<tbody>
{% for row in data %}
<tr class="{% if 'China' in row[3] or 'china' in row[3] or 'chinese' in row[3] or 'Chinese' in row[3] or 'China' in row[2] or 'china' in row[2] or 'chinese' in row[2] or 'Chinese' in row[2] %}highlight{% endif %}">
<td>{{ row[0] }}</td>
<td class="url-cell">
<div class="url-container">
<a href="{{ row[1] }}" target="_blank">URL</a> <!-- 使用 URL 替代完整链接文本 -->
<button class="copy-btn" onclick="copyToClipboard('{{ row[1] }}')">复制</button>
</div>
</td>
<td>{{ row[2] }}</td>
<td>{{ row[3] }}</td>
</tr>
{% endfor %}
</tbody>
</table>
<script>
function updateTime() {
const now = new Date();
const timeString = now.toLocaleTimeString();
document.getElementById('currentTime').textContent = timeString;
}
setInterval(updateTime, 1000); // 每秒更新一次时间
function copyToClipboard(text) {
const tempInput = document.createElement('input');
tempInput.value = text;
document.body.appendChild(tempInput);
tempInput.select();
document.execCommand('copy');
document.body.removeChild(tempInput);
alert('URL 已复制到剪贴板');
}
function startCountdown(duration) {
let timer = duration, seconds;
const countdownElement = document.getElementById('countdown');
setInterval(() => {
seconds = parseInt(timer, 10);
countdownElement.textContent = seconds;
if (--timer < 0) {
location.reload();
}
}, 1000);
}
window.onload = () => {
startCountdown(120); // 设定倒计时时间为120秒
};
</script>
</body>
</html>
"""
@app.route('/')
def home():
csv_files = [f for f in os.listdir(csv_directory) if f.startswith("wsj_") and f.endswith(".csv")]
if not csv_files:
return "没有找到任何 CSV 文件"
csv_files.sort(reverse=True)
latest_csv_file = os.path.join(csv_directory, csv_files[0])
df = pd.read_csv(latest_csv_file)
file_name = os.path.basename(latest_csv_file)
return render_template_string(HTML_TEMPLATE, data=df.values, file_name=file_name)
# 启动应用
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
代码描述:
下面这些库都要有
import os
import threading
import time
import pandas as pd
from flask import Flask, render_template_string #web框架,用于构建web应用.从字符串直接渲染HTML模板,不需要单独的HTML文件。
from datetime import datetime, timedelta #处理日期和时间的计算
import subprocess #用于运行程序 rss_to_csv.py 上面解释的程序。
# 初始化 Flask 应用
app = Flask(__name__)
# 设置 CSV 文件的目录 存储CSV文件 现在是Linux目录格式
csv_directory = '/usr/src/app/rss_project/csv_files'
rss_script_path = '/usr/src/app/rss_to_csv.py'
os.makedirs(csv_directory, exist_ok=True)
# 定时运行 rss_to_csv.py
def run_rss_script():
while True:
subprocess.run(['python', rss_script_path])
cleanup_old_files() # 每次运行完脚本后清理旧文件
time.sleep(7200) # 每2小时运行一次
# 清理超过7天的 CSV 文件
def cleanup_old_files():
now = datetime.now()
cutoff = now - timedelta(days=7) #在这里可以更改时间
for filename in os.listdir(csv_directory):
if filename.startswith("wsj_") and filename.endswith(".csv"):
file_path = os.path.join(csv_directory, filename)
file_time = datetime.fromtimestamp(os.path.getmtime(file_path))
if file_time < cutoff:
os.remove(file_path)
print(f"删除旧文件: {filename}")
# 在 Flask 应用启动前运行一次 rss_to_csv.py 所以程序第一次运行,可能不成展示内容或最新的内容,要等这个文件创建后 刷新才用
subprocess.run(['python', rss_script_path])
# 启动定时任务
threading.Thread(target=run_rss_script, daemon=True).start()
# 自定义 HTML 模板,设置标题为 "The Wall Street Journal" 4个列的宽度,高亮内容含有 China Chinese 条目
HTML_TEMPLATE = """
<!doctype html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>The Wall Street Journal</title> <!-- 设置网页标题 -->
<style>
body {
font-family: Arial, sans-serif;
line-height: 1.5;
color: #333;
background-color: #f5f5f5;
margin: 0;
padding: 20px;
}
.header {
display: flex;
justify-content: space-between;
align-items: center;
margin-bottom: 20px;
}
.file-info {
font-weight: bold;
font-size: 18px;
}
.refresh-btn-container {
display: flex;
align-items: center;
}
.refresh-btn {
padding: 8px 16px;
background-color: #4CAF50;
color: white;
border: none;
cursor: pointer;
border-radius: 4px;
font-size: 14px;
}
.refresh-btn:hover {
background-color: #45a049;
}
.countdown {
margin-left: 10px;
font-size: 14px;
color: #555;
}
.current-time {
font-size: 16px;
font-weight: bold;
}
table {
width: 100%;
border-collapse: collapse;
margin-bottom: 20px;
}
th, td {
padding: 8px 12px;
border: 1px solid #ddd;
text-align: left;
white-space: pre-line; /* 支持换行显示 */
}
th {
background-color: #f4f4f4;
font-weight: bold;
}
tr:nth-child(even) {
background-color: #f9f9f9;
}
.highlight {
background-color: yellow;
}
.url-cell {
max-width: 100px; /* 将 URL 列的最大宽度设置为100px */
word-wrap: break-word; /* 强制换行 */
overflow-wrap: break-word;
}
.url-container {
display: inline-flex; /* 确保 URL 和按钮在同一行 */
align-items: center;
}
.copy-btn {
margin-left: 10px;
padding: 5px 10px;
font-size: 12px;
cursor: pointer;
}
</style>
</head>
<body>
<div class="header">
<div class="file-info">文件名: {{ file_name }}</div>
<div class="refresh-btn-container">
<button class="refresh-btn" οnclick="location.reload();">刷新页面</button>
<div class="countdown">下次刷新倒计时: <span id="countdown">120</span> 秒</div>
</div>
<div class="current-time">当前时间: <span id="currentTime"></span></div>
</div>
<table>
<thead>
<tr>
<th>发布时间</th>
<th>URL</th>
<th>标题</th>
<th>摘要</th>
</tr>
</thead>
<tbody>
{% for row in data %}
<tr class="{% if 'china' in row[2].lower() or 'china' in row[3].lower() or 'chinese' in row[2].lower() or 'chinese' in row[3].lower() %}highlight{% endif %}">
<td>{{ row[0] }}</td>
<td class="url-cell">
<div class="url-container">
<a href="{{ row[1] }}" target="_blank">URL</a> <!-- 使用 URL 替代完整链接文本 -->
<button class="copy-btn" οnclick="copyToClipboard('{{ row[1] }}')">复制</button>
</div>
</td>
<td>{{ row[2] }}</td>
<td>{{ row[3] }}</td>
</tr>
{% endfor %}
</tbody>
</table>
<script>
function updateTime() {
const now = new Date();
const timeString = now.toLocaleTimeString();
document.getElementById('currentTime').textContent = timeString;
}
setInterval(updateTime, 1000); // 每秒更新一次时间
function copyToClipboard(text) {
const tempInput = document.createElement('input');
tempInput.value = text;
document.body.appendChild(tempInput);
tempInput.select();
document.execCommand('copy');
document.body.removeChild(tempInput);
alert('URL 已复制到剪贴板');
}
function startCountdown(duration) {
let timer = duration, seconds;
const countdownElement = document.getElementById('countdown');
setInterval(() => {
seconds = parseInt(timer, 10);
countdownElement.textContent = seconds;
if (--timer < 0) {
location.reload();
}
}, 1000);
}
window.onload = () => {
startCountdown(120); // 设定倒计时时间为120秒
};
</script>
</body>
</html>
补充:
程序从Windows上移到 Linux Docker上后,会缺少字库,HTML解释的表现也会不同,在最后显示结果差异很大,原本在Windows上格式字体完美,在Linux上会重来。 为此,安装了自库,多次修改HTML内容,花了学习+拼代码的2倍时间。
代码送到Nas的Docker/Container上运行
我不想让我的Laptop 24小时转,在NAS上跑是最好的安排
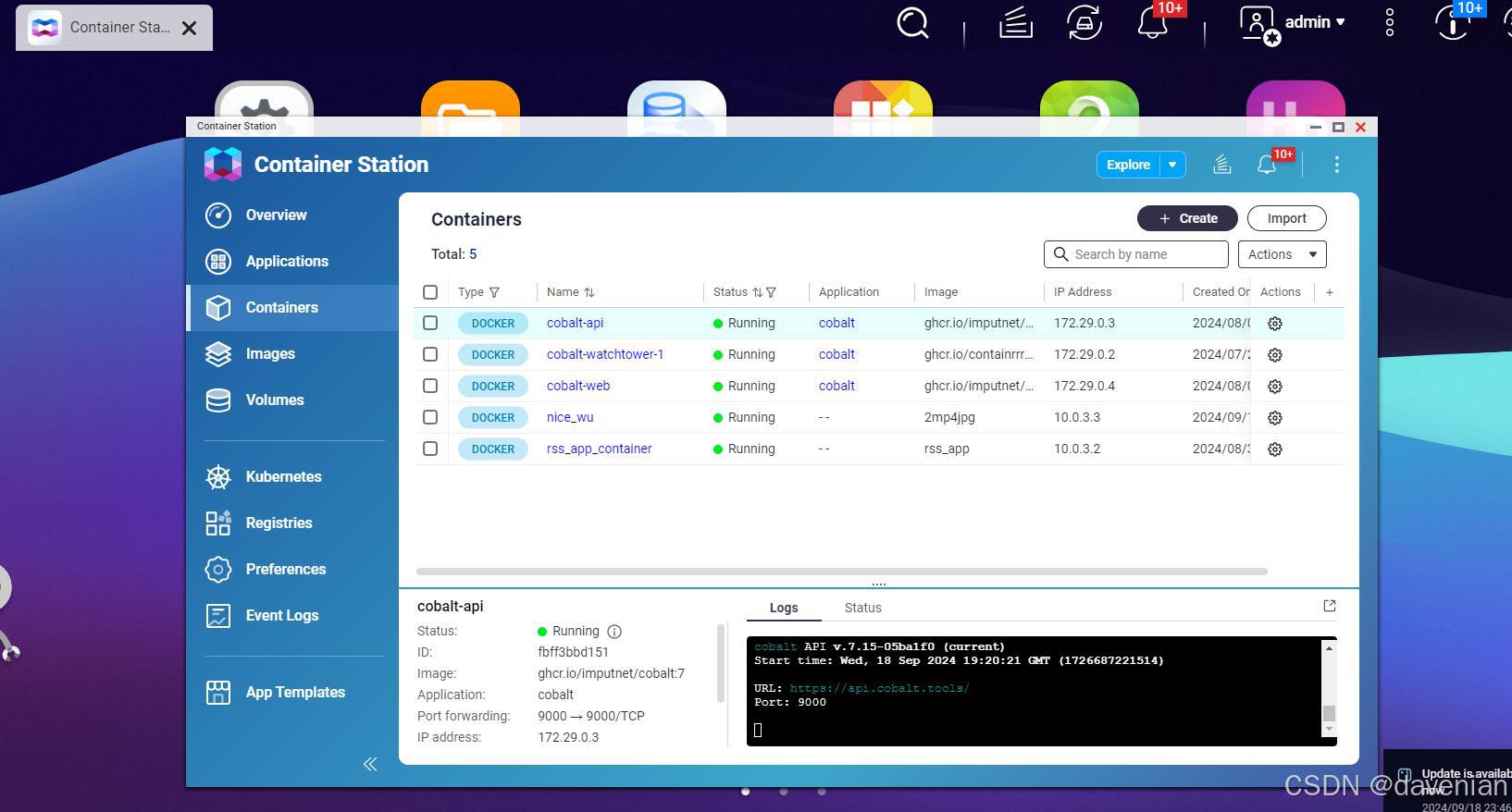
我用的是QNAP 4硬盘位家用NAS, 它上面有 Container Station(下面中间白色背景 app), 功能是半价的Docker 跑小程序没问题。
之前有个从github 复制来的(ghcr.io/imputnet/cobalt),用于下载 youtube视频,后来也移到NAS Container上,都是Web 服务。它给我的启发,也做个浏览器可以使用的程序。
制作Docker配置所需的文件
Dockerfile 内容:
# 使用官方的 Python 3.12 基础镜像
FROM python:3.12-slim
# 设置工作目录
WORKDIR /usr/src/app
# 复制当前目录的内容到工作目录
COPY . .
# 安装依赖
RUN pip install --no-cache-dir -r requirements.txt
# 启动应用
CMD ["python", "app.py"]
requirements.txt 内容:
Flask
pandas
feedparser
googletrans==4.0.0-rc1
python-dateutil
pytz
webbrowser描述:
pytz是Linux下字体库。在NAS上第一次运行,发现字体变化后手动安装,所以列到需求清单里。
这小段写了这么多,这两文件几乎不用。我用docker 命令操作的,因为nas上的app有bug
登录到NAS
现在你需要一个工具,可以连接NAS的SSH 服务的客户端。NAS也需要打开SSH服务,默认是不启用的。
半料子解读 Docker
在这个实践中,用不到 docker-compose.yml
简单介绍一下:Docker与家用NAS里的Container差不多,后者是在家用NAS上实现Docker所有功能的APP,就是Docker在NAS上产品名。
docker/container: 理解为阉割的虚拟机平台,它与主机共享OS内核,所以即使相同的操作系统,但由于版本不同,对docker平台上的程序会有很大的影响。
Image: 只读的完美计算机(虚拟机 virtualization machine)环境,就跟光蝶一样,一切都在里面,移到任何的 Docker/Container这个播放器上,都通用。但在上面添加与修改的内容,下次启动就清零。
Application: Container容器中的具体软件或服务,列如 word,execel,sql 这类独立软件或服务,跑在各自的 container容器中,互相不会干扰。就如同这个 项目的程序集。
在我的实践里,让程序在容器中跑就行了,不需要过多的配置。类似于一个批处理命令,循环不退出。
常用的Docker命令:
docker ps # 查看OS上正在运行的容器
docker kill #中止运行的容器
docker stop <container_id> # 停止容器
docker start <container_id> # 启动容器
docker build -t <container中的名字 我用的是 rss_app_container> . (这里有个 “点”)
docker rm <container_name> #删除容器
docker exec -it <container_name> /bin/bash 进入容器内部 排错主要靠这行
docker cp 文件名 <container_name>:/容器内的路径
这些命令已经足够了
后续操作:
所有的文件放到nas上 rss_to_csv.py app.py 就这两个
用ssh客户端链接NAS,并找到上面两个文件所在的目录里,执行命令如下:
docker build -t rss_app_container . #创建一个 rss_app_container容器
docker cp rss_to_csv.py rss_app_container:/usr/src/app #把两个文件分别复制到容器 /usr/src/app 目录, 也可以用通配符来多选,我只是列出来清楚些
docker cp app.py rss_app_container:/usr/src/app
Done: 创建 rss_app_container 容器,复制两个文件到上面目录, 在NAS container Station里能看到它, 如下图:

红框里就是新建的容器 rss_app_container (我也不知道为什么写这么长的名字,已经在container里的,还要写同名。)
flask框架跑这个轻程序没问题, 也指定了端口 5000, 在启动时,给它一个端口映射如图:

代码已经跑快4天,NAS不关机 只要打开 http://nas:5000 就能快速看WSJ新闻。 NAS重启 Container Center 也会启动,并运行这些 容器: rss_app_container, 还有之前提到的 github image
下面是浏览器中看到的内容: http://192.168.1.8:5000 我的NAS IP,与 这个映射的端口。 我有安装证书,但要有DNS名字,不露怯了。

上面黄色行,代表里面有出发关键词:China / Chinese
如果想分享出去,点复制按钮就获得了当条的链接。如果需要详细阅读,可以点URL,如下:
推荐这款终端软, 一次性购买 SecureCRT  想演示进入 docker container, 没人开门算了
想演示进入 docker container, 没人开门算了
补充:
在Linux里,要注意权限问题。在容器里,你传递进来的文件的权限,往往是 root root | 用户 用户组
可能程序在访问 CSV文件时,不能打开。 需要分配到适当的组。 还有文件读写权限。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









