






 本文深入探讨了Skywalking APM工具在微服务架构下的应用,特别是在JVM监控和问题排查方面的实践。通过实际案例,展示了如何使用Skywalking监测服务性能、分析调用链,并结合Arthas等工具定位和解决JVM内存泄漏问题。
本文深入探讨了Skywalking APM工具在微服务架构下的应用,特别是在JVM监控和问题排查方面的实践。通过实际案例,展示了如何使用Skywalking监测服务性能、分析调用链,并结合Arthas等工具定位和解决JVM内存泄漏问题。
预计阅读时间: 8 分钟

本文分为上、下两篇围绕以下几点展开:
-
01 Skywalking 调用链简介 (上篇)
-
02 接入 Skywalking Agent 后的服务表现(上篇)
-
03 应用哪些「手段」排查 Jvm 问题的 (上篇)
-
04 结合 Jvm GC 日志分析到底发生了什么(下篇)
-
05 应用哪些 「手段」排查 JVM 内存泄漏的 (下篇)
-
06 Skywalking 官网中是如何修复的(下篇)
01
Skywalking 调用链简介
Skywalking 是一款 APM,英文全称:Application Performance Monitoring System (应用程序性能监控系统),尤其适用于微服务,Cloud Native 和基于容器的架构系统。也称为分布式跟踪系统。
Skywalking 提供了一种自动检测应用程序的方法:无需更改目标应用程序的任何源代码;以及具有高效流媒体模块的收集器。
该项目由国人吴晟基于 OpenTracking 实现的开源项目 Skywalking(github、gitee 码云)。
2017年12月8日,Apache 软件基金会孵化器项目管理委员会 ASF IPMC宣布『SkyWalking全票通过,进入Apache孵化器』。
经过一年半时间的打磨,该项目于2019年04月18日,正式成为 Apache 基金会顶级项目。
其主要特点:
服务、服务实例和 Endpoint(HTTP URI)性能指标监测
数据库服务实例的性能指标监测
服务拓扑图
服务和 Endpoint 依赖分析
慢服务和慢 Endpoint 探查
支持自动探针和手动探针
支持多语言探针
性能好,对服务性能损耗小
分布式追踪和追踪上下文传播
支持根据TraceId检索调用链
告警
大家如果对 Skywalking 项目感兴趣,可访问官网和 github 。
官方网站:
https://skywalking.apache.org/
github 项目地址:
https://github.com/apache/skywalking
我们项目中部署的 Skywalking 控制台,在这里带大家直观感受一下。
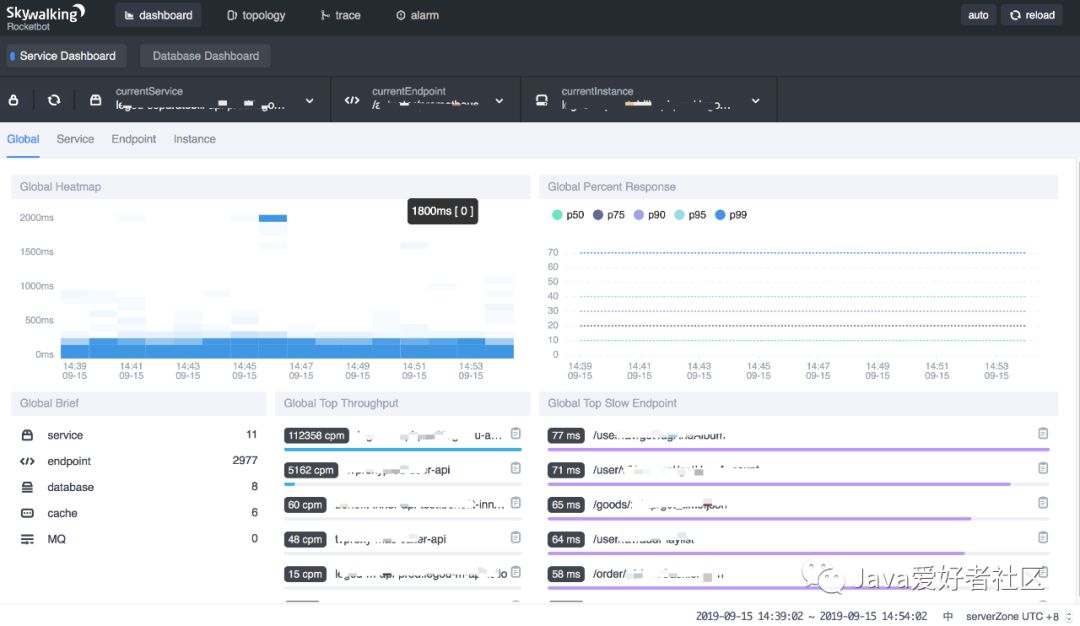
dashboard Global(仪表盘)
吞吐量最大的服务、最慢的 Endpoint 监测。
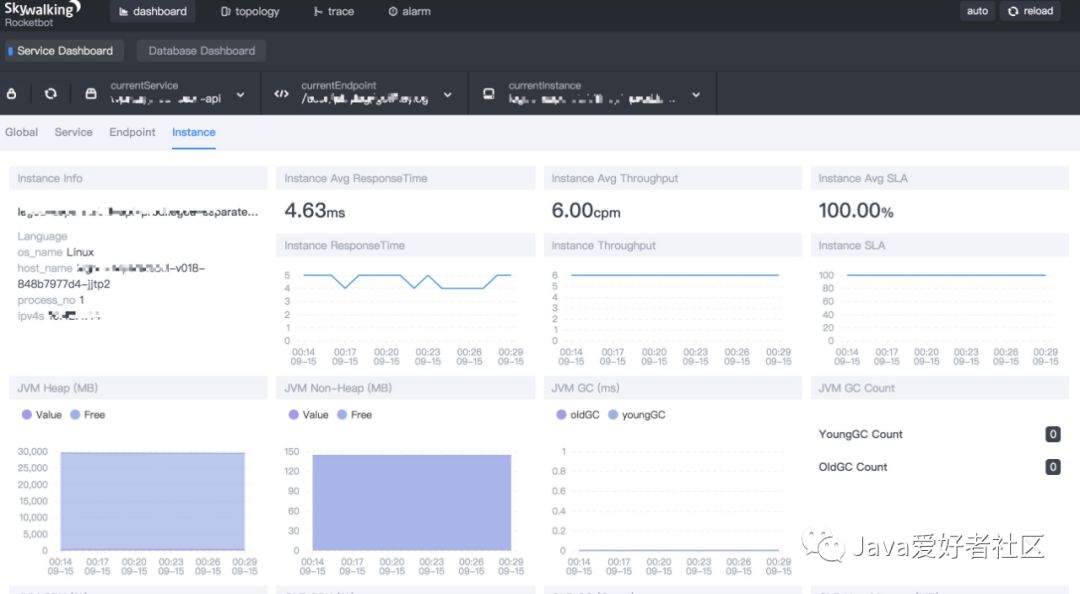
dashboard Instace(仪表盘)
服务实例、JVM 内存及 GC 监测。
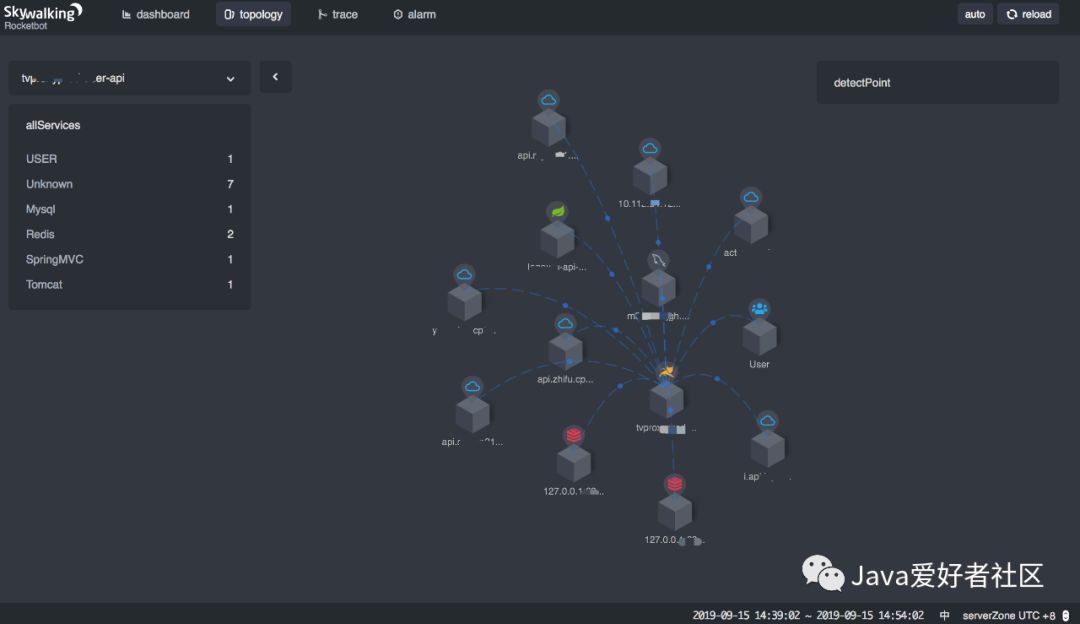
topology(拓扑图)
服务所有依赖服务拓扑图。
trace(追踪)
服务分布式调用链的追踪,支持根据 traceID 检索。

trace list(追踪)
list(列表结构)追踪,可以看到耗时最长的服务。
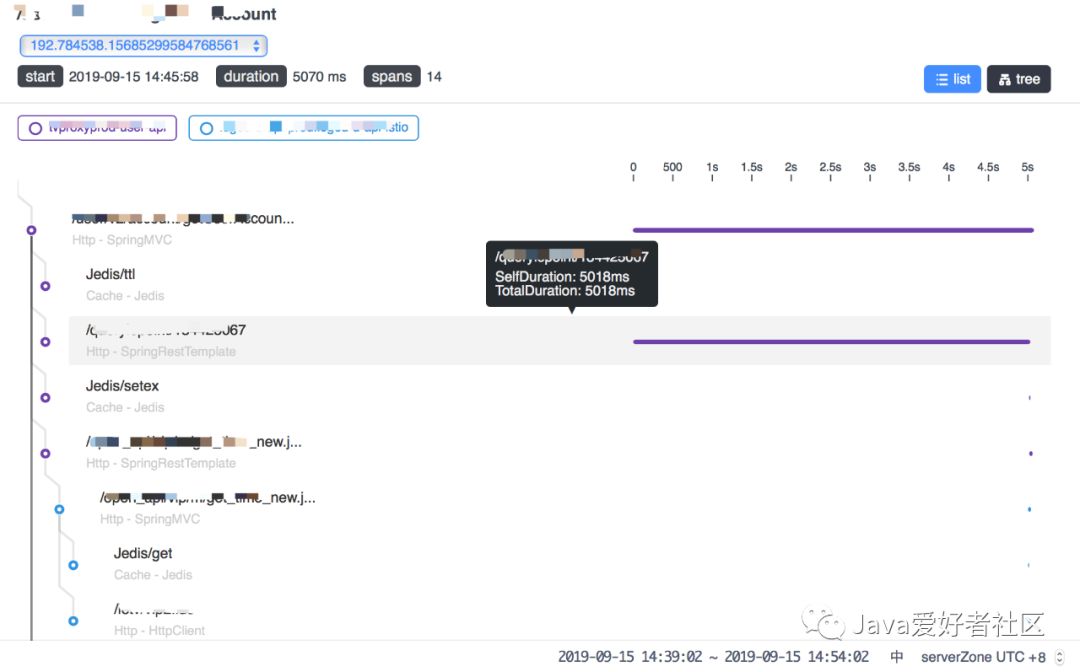
trace tree(追踪)
tree(树形结构)追踪,选中某一服务能看到请求耗时。
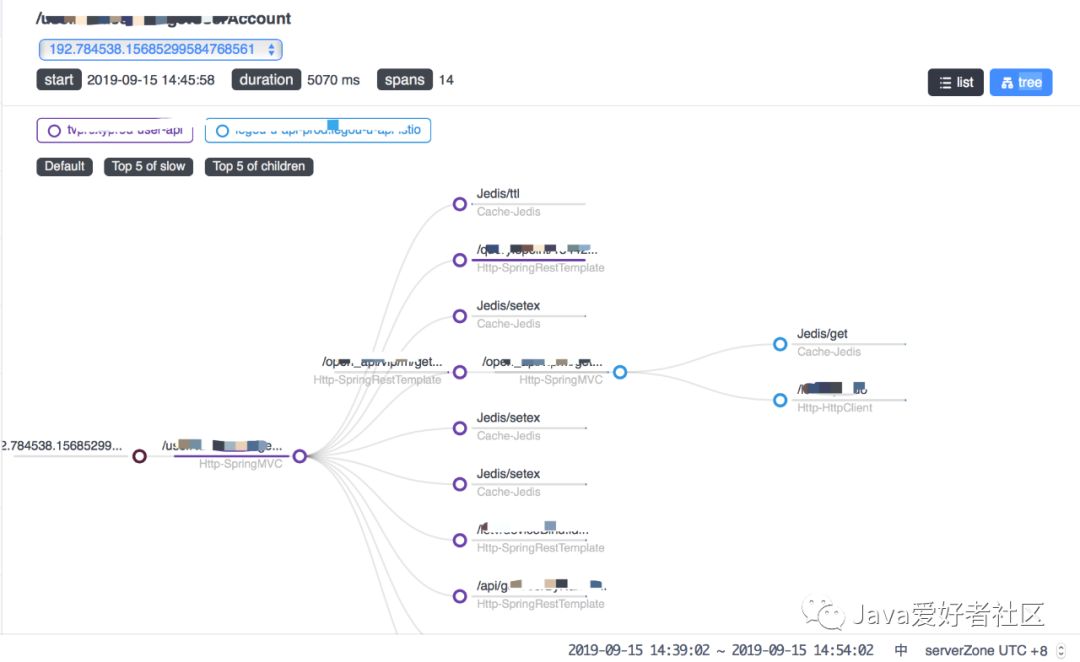
更多细节,大家可以参照官网文档进一步了解。
总之,Skywalking 项目是个很有潜力的项目,值得大家关注。
02
接入 Skywalking Agent 后的服务表现
介绍完 Skywalking,接下来我们进入正题。
项目配置说明
项目接入时,当时使用的版本号:
Skywalking Agent 6.2.0
Skywalking Agent下载地址:
http://skywalking.apache.org/downloads/
项目中目前还在使用 Docker 部署,所以我将 Agent 提前安装到基础镜像中。
项目中使用的 Jdk 版本为 Jdk1.8,Jvm 算法使用经典的 ParNew + CMS 组合,如果有朋友不了解的,可以去 Google 或 Baidu 搜索补充下 Jvm GC 垃圾回收相关知识点。
业务场景介绍
该系统主要是给客户端提供代理服务的,访问高峰一般是在用户观看视频高峰期,比如晚高峰 8 点左右,晚高峰期间并发量最高,QPS (每秒的请求数) 能达到 6000。
当然该系统也是按业务类型,划分为了多个服务模块,按照微服务架构部署的,比如用户服务、播放服务、会员服务等。
问题场景介绍
服务接口上线后,虽然有类似 OpenFalcon、InfluxDB、ELK 日志等监控工具,但作为一名『老司机』,我还是习惯登录到服务器上,通过一些命令查看服务运行情况。常用的比如 jstat 工具去查看下 Young GC 执行频率、GC 回收情况、老年代内存占用等。
jstat 命令如下:
jstat -gcutil $pid 1000 100项目接入 Skywalking Agent 上线后,观察一切都是正常的。过了几天,也要临近周末,手机收到了告警短信,提醒接口耗时,但过一会就不再报了。
根据告警提示,访问该接口发现都是正常的,开始怀疑可能是因为「网络抖动」引起的,挺不好意思又o(*^@^*)o怪「网络」了~
过了一段时间再一次收到了接口超时告警,然后我通过浏览器直接访问该接口,还是正常的,但是访问响应有时会慢很多。出于「职业本能」警觉到一定是服务出问题了,去看看监控是不是有什么异常。此时,正好运维同学反馈说,其中有一台服务器,CPU、Load指标比其他机器要高。
查看了 OpenFalcon 监控,跟运维反馈一致。同时,这台服务器上接口的平均响应时间,也比其他机器要高一些。
另外说明一点,这台服务器我有意调低了老年代内存的,正常配置:
Jvm -Xmx12g -Xms12g -Xmn8g
调整后的配置:
Jvm -Xmx12g -Xms12g -Xmn10g
这个是因为一些特殊原因,所以调低老年代内存,观察内存使用情况。
当时主要分析看,基本都是发生的 Yong GC,晋升到老年代对象很少,老年代内存占用率很低,不到 1g,即使发生了Full GC,会把大部分对象都给回收掉。
03
问题排查现场
接下来,迅速登录到服务器上。
最近比较常用的一个排查 Java 问题工具,是阿里开源的Arthas (阿尔萨斯)诊断工具。

Arthas 在线分析诊断非常受欢迎,github 上的 Star 截止目前已达到 1.6w。
在此,不做过多介绍,强烈推荐大家都使用一下。
Arthas 文档参考:
https://alibaba.github.io/arthas/
Arthas 也支持 Docker 或者 k8s 容器内 Java 应用的诊断。
Arthas 安装文档官网地址:
https://alibaba.github.io/arthas/docker.html
诊断 Docker 里的 Java 进程:
docker exec -it ${containerId} /bin/bash -c "wget https://alibaba.github.io/arthas/arthas-boot.jar && java -jar arthas-boot.jar"注意:
这种方式,进入容器后,会首先通过 wget 命令从官网下载 arthas-boot.jar ,需要你的容器内支持 wget 命令。另外,一种方式可以将 Arthas 提前安装到基础镜像中,方便直接使用。
Arthas 工具接入容器后,默认会进入到它自身的控制台上,在控制台上就可以执行一系列 Arthas 提供的诊断命令了。
进入控制台,我首先执行的就是 dashboard (监控面板),能够直观的看到如下监控数据:
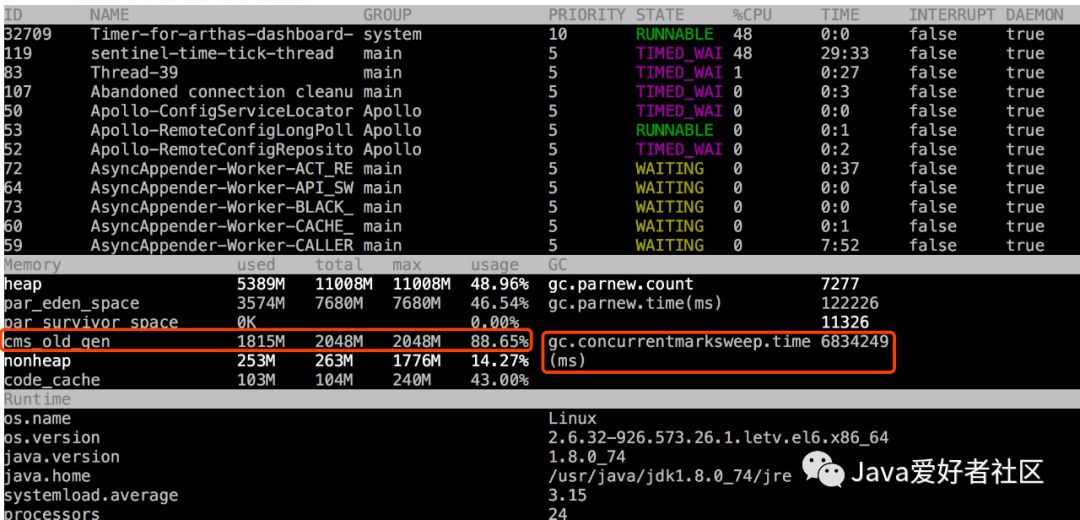
大家看上述截图中的位于左侧的 Memory 监控指标。
内存使用指标:
used (已使用)total(总大小)max(最大内存)usage(内存使用率)
heap:表示 Jvm 堆内存的使用情况
par_eden_space:表示 Jvm 堆中新生代内存 Eden 区使用情况
par_suvivor_space:表示 Jvm 堆中新生代内存 Survivor 区使用情况
cms_old_gen:表示 Jvm 堆中老年代内存使用情况,这里的 cms 是表示老年代使用了 CMS 垃圾回收算法。
nonheap:表示非堆内存使用情况
code_cache:表示 Jvm 生成的 native code 的内存空间使用情况
再看截图中位于右侧 GC 监控指标。
gc.parnew.count:表示 Jvm 新生代内存发生 Yong GC 的垃圾回收次数
gc.parnew.time(ms):表示 Jvm 新生代内存发生 Yong GC 的执行时间
gc.concurrentmarksweep.time:表示 Jvm CMS GC 垃圾回收次数
很明显,Memory 中的 cms_old_gen 占用比例很高,而且更为关键的 GC 监控指标中的 gc.concurrentmarksweep.time 老年代 CMS 垃圾回收时间非常离谱了。
实际上 Jvm 此时是一直在执行 CMS GC,Yong GC 基本不会发生了。
通过前面介绍的 jstat 命令行工具查看:
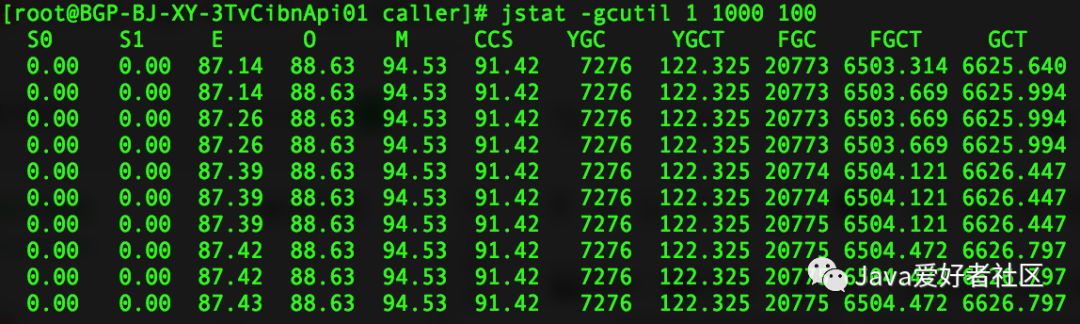 通过 jstat 命令的执行结果看到 FGCT (Full GC发生的时间)跟 Arthas 上的 dashboard 监控中看到的数据基本是吻合的。
通过 jstat 命令的执行结果看到 FGCT (Full GC发生的时间)跟 Arthas 上的 dashboard 监控中看到的数据基本是吻合的。
对 jstat -gcutil 执行结果,关键指标简要说明:
S0 S1: 表示堆中新生代内存的两个 Survivor 区内存使用率
E:表示堆中新生代内存的 Eden 区内存使用率
O:表示堆中老年代内存使用率
M:表示 Metaspace 元空间的内存使用情况
YGC:表示 Yong GC 发生的垃圾回收次数
YGCT:表示 Yong GC 发生垃圾回收执行的时间
FGC:表示 Full GC 发生的垃圾回收次数
FGCT:表示 Full GC 发生垃圾回收执行的时间
GCT:表示 GC 垃圾回收执行的总时间
发生以上问题,肯定怀疑是内存泄漏导致了,因为 O 区(老年代)内存始终无法回收,所以一直在持续的发生 CMS GC,老年代空间不足导致。
最后,考虑到整篇文章字数过多,大家阅读时长的关系。将未完成的文章放到(篇二)来讲解。
欢迎大家持续关注!
下集预告:
-
04 结合 Jvm GC 日志分析到底发生了什么(下篇)
-
05 应用哪些 「手段」排查 JVM 内存泄漏的 (下篇)
-
06 Skywalking 官网中是如何修复的(下篇)




点开,扫码即刻关注
您感觉有价值,点击下『在看』吧


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









