







1 流计算中流的状态
1.1 数据状态
首先是流数据状态。在流计算过程中,我们需要处理事件窗口、时间乱序、多流关联等问题。解决这些问题,通常需要对部分流数据进行临时缓存,并在计算完成时再将这些临时缓存清理掉。因此,我们将这些临时保存的部分流数据称为“流数据状态”。
1.2 信息状态
在流计算过程中,我们会得到一些有用的业务信息,比如时间维度的聚合值、关联图谱的一度关联节点数、CEP 的有限状态机等,这些信息会在后续被继续使用,从而需要将它们保存下来。同时在之后的流计算过程中,这些信息还会被不断地查询和更新。因此,我们将这些分析所得并保存下来的业务信息称为“流信息状态”。
信息状态的存储,通常是依赖于数据库完成的。这有三方面的原因。
一是,“流信息状态”通常需要保存较长时间,数据量也不小,还需要频繁查询和更新,将它存放在数据库中,能方便地长期保存和增删查改。
二是,“流信息状态”存在“数据变冷”和“过期淘汰”的问题,使用数据库的“热数据缓存”和“TTL 机制”,能方便有效地解决这两个问题。
三是,“流信息状态”通常数据量会很大,单个存储节点往往是不够用的,选择合适的数据库能够方便地扩展为集群。
2. Flink的状态操作和无状态操作
- 无状态
每一条输入对应一个输出,幂等,可重复操作。
- 有状态
多个输入对应一个输出,非幂等,不可重复操作。
3. Flink的checkpoint的过程
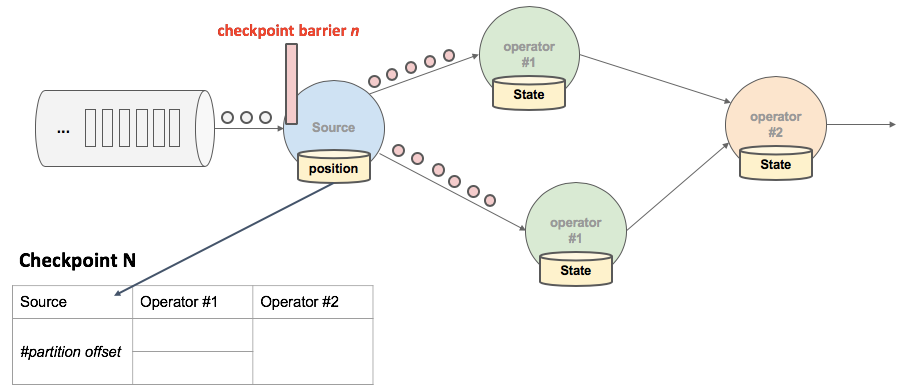
- JobManager有一组件checkpoint coordinator向SourceTask 发送 CheckPointTrigger,SourceTask 会在数据流中安插 CheckPoint barrier。

- Source Task 自身做快照,并保存到状态后端。
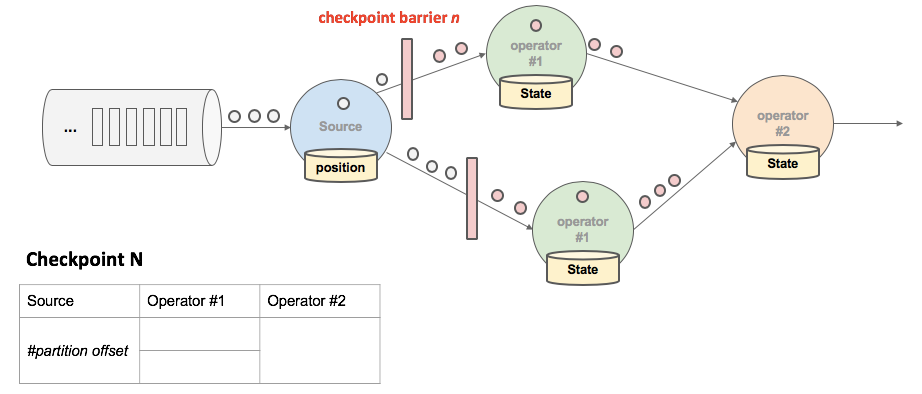
- SourceTask 将 barrier 跟数据流一块往下游发送。
- 当下游的 Operator 实例接收到 CheckPointbarrier 后,对自身做快照。
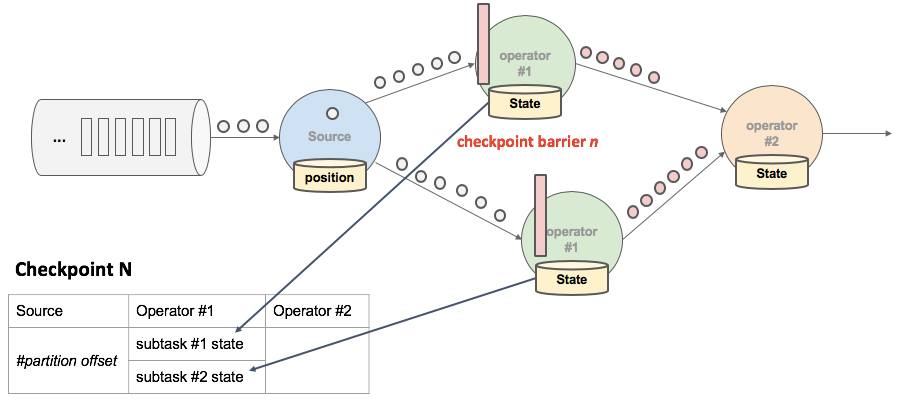
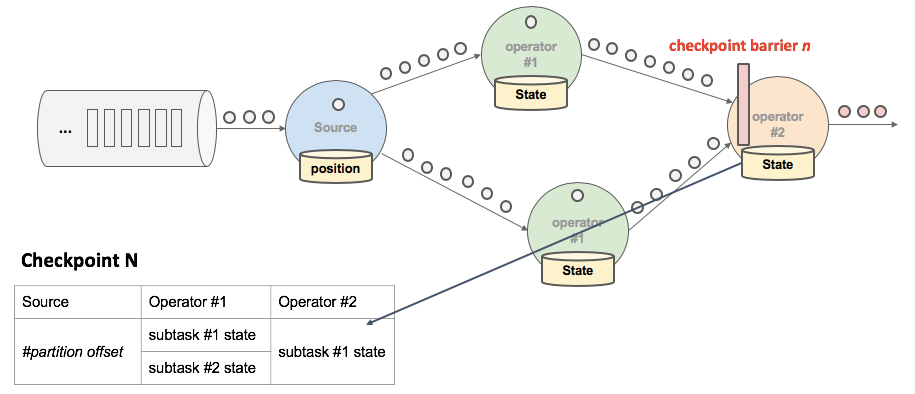
上述图中,有 4 个带状态的 Operator 实例,相应的状态后端就可以想象成填 4 个格子。整个 CheckPoint 的过程可以当做 Operator 实例填自己格子的过程,Operator 实例将自身的状态写到状态后端中相应的格子,当所有的格子填满可以简单的认为一次完整的 CheckPoint 做完了。
总结整个 CheckPoint 执行过程如下:
-
JobManager 端的 CheckPointCoordinator 向所有 SourceTask 发送 CheckPointTrigger,Source Task 会在数据流中安插 CheckPoint barrier。
-
当 task 收到所有的 barrier 后,向自己的下游继续传递 barrier,然后自身执行快照,并将自己的状态异步写入到持久化存储中。
-
增量 CheckPoint 只是把最新的一部分更新写入到 外部存储;
-
为了下游尽快做 CheckPoint,所以会先发送 barrier 到下游,自身再同步进行快照;
-
当 task 完成备份后,会将备份数据的地址(state handle)通知给 JobManager 的 CheckPointCoordinator。
-
如果 CheckPoint 的持续时长超过了 CheckPoint 设定的超时时间,CheckPointCoordinator 还没有收集完所有的 State Handle,CheckPointCoordinator 就会认为本次 CheckPoint 失败,会把这次 CheckPoint 产生的所有状态数据全部删除。
-
最后 CheckPointCoordinator 会把整个 StateHandle 封装成 completed CheckPoint Meta,写入到 hdfs。
4. 精准一次消费和至少一次消费
// 最少一次 CheckpointingMode.AT_LEAST_ONCE // 精确一次 CheckpointingMode.EXACTLY_ONCE
4.1 barrier 对齐
当还有其他输入流的 barrier 还没有到达时,会把已到达的 barrier 之后的数据 1、2、3 搁置在缓冲区,等待其他流的 barrier 到达后才能处理。
在Flink的检查点机制中,屏障(barrier)是划分快照(状态)的边界。在启用exactly once语义的条件下,当一个算子有多个输入流时,需要等待所有输入流中当前检查点N的屏障都到达其输入缓冲区,才能安全地触发检查点。屏障对齐不仅保证了状态的准确性,还巧妙地消去了原生C-L算法中记录输入流状态的步骤(之前说过,即使作业执行计划是有环图,也只需要记录回边流的状态),十分轻量级。
**存在的问题:**效率低,影响反压
屏障对齐是阻塞式的,在作业出现反压时可能会成为不定时炸弹。我们知道,检查点屏障是从Source端产生并源源不断地向下游流动的。如果作业出现反压(哪怕整个DAG中的一条链路反压),数据流动的速度减慢,屏障到达下游算子的延迟就会变大,进而影响到检查点完成的延时(变大甚至超时失败)。如果反压长久不能得到解决,快照数据与实际数据之间的差距就越来越明显,一旦作业failover,势必丢失较多的处理进度。另一方面,作业恢复后需要重新处理的数据又会积压,加重反压,造成恶性循环。
4.2 barrier不对齐
不对齐就是指当还有其他流的 barrier 还没到达时,为了不影响性能,也不用理会,直接处理 barrier 之后的数据。等到所有流的 barrier 的都到达后,就可以对该 Operator 做 CheckPoint 了。
**存在的问题:**非精确一次消费,是最少一次
假如我们从chk-100恢复。CheckPoint 的目的就是为了保存快照,如果不对齐,那么在 chk-100 快照之前,已经处理了一些 chk-100 对应的 offset 之后的数据,当程序从 chk-100 恢复任务时,chk-100 对应的 offset 之后的数据还会被处理一次,所以就出现了重复消费。
4.3 非对齐检查点
// enables the experimental unaligned checkpoints env.getCheckpointConfig().enableUnalignedCheckpoints();
Flink 1.11版本引入的新功能
简单解说:
a) 当算子的所有输入流中的第一个屏障到达算子的输入缓冲区时,立即将这个屏障发往下游(输出缓冲区)。
b) 由于第一个屏障没有被阻塞,它的步调会比较快,超过一部分缓冲区中的数据。算子会标记两部分数据:一是屏障首先到达的那条流中被超过的数据,二是其他流中位于当前检查点屏障之前的所有数据(当然也包括进入了输入缓冲区的数据)。
既然不同检查点的数据都混在一起了,非对齐检查点还能保证exactly once语义吗?
答案是肯定的。当任务从非对齐检查点恢复时,除了对齐检查点也会涉及到的Source端重放和算子的计算状态恢复之外,未对齐的流数据也会被恢复到各个链路,三者合并起来就是能够保证exactly once的完整现场了。
非对齐检查点目前仍然作为试验性的功能存在,并且它也不是十全十美的(所谓优秀的implementation往往都要考虑trade-off),主要缺点有二:
需要额外保存数据流的现场,总的状态大小可能会有比较明显的膨胀(文档中说可能会达到a couple of GB per task),磁盘压力大。当集群本身就具有I/O bound的特点时,该缺点的影响更明显。
从状态恢复时也需要额外恢复数据流的现场,作业重新拉起的耗时可能会很长。特别地,如果第一次恢复失败,有可能触发death spiral(死亡螺旋)使得作业永远无法恢复。
所以,官方当前推荐仅将它应用于那些容易产生反压且I/O压力较小(比如原始状态不太大)的作业中。















 1322
1322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









