







建表:
-- ----------------------------
-- Table structure for duplicaterow
-- ----------------------------
DROP TABLE IF EXISTS `duplicaterow`;
CREATE TABLE `duplicaterow` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`value` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of duplicaterow
-- ----------------------------
INSERT INTO `duplicaterow` VALUES ('1', 'a', 'aa');
INSERT INTO `duplicaterow` VALUES ('2', 'a', 'aa');
INSERT INTO `duplicaterow` VALUES ('3', 'b', 'bb');
INSERT INTO `duplicaterow` VALUES ('4', 'b', 'bb');
INSERT INTO `duplicaterow` VALUES ('5', 'b', 'zz');
INSERT INTO `duplicaterow` VALUES ('6', 'c', 'cc');
INSERT INTO `duplicaterow` VALUES ('7', 'c', 'cc');
INSERT INTO `duplicaterow` VALUES ('8', 'c', 'xx');
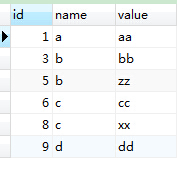
INSERT INTO `duplicaterow` VALUES ('9', 'd', 'dd');SELECT * from duplicaterow;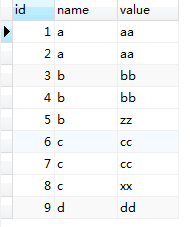
(一)单列重复
1、查询单列name重复记录:
SELECT * FROM duplicaterow WHERE name in
(SELECT name from duplicaterow GROUP BY name HAVING count(name) > 1)
2、删除单列name有重复的记录:
DELETE FROM duplicaterow WHERE name in
(SELECT name from duplicaterow GROUP BY name HAVING count(name) > 1);
(MySQL不支持,报了1093的错)
可以通过建临时表来实现
create table tmp
SELECT name as col1 from duplicaterow GROUP BY name HAVING count(name) > 1;
DELETE from duplicaterow where name in (SELECT col1 from tmp);
drop table tmp;
执行后的结果:
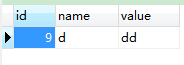
3、删除单列name有重复,且保留一条:
create table tmp
SELECT name as col1 from duplicaterow GROUP BY name HAVING count(name) > 1;
create table tmp2
SELECT min(id) as col1 from duplicaterow GROUP BY name HAVING count(name) > 1;
DELETE from duplicaterow where name in
(SELECT col1 from tmp) and id not in (SELECT col1 from tmp2);
drop table tmp;
drop table tmp2;执行后的结果:
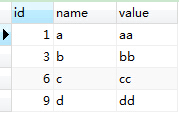
(二)多列重复
1、查询表中name和value重复的记录:
SELECT * from duplicaterow WHERE (name,value) in
(select name, value from duplicaterow GROUP BY name,value having count(*)>1);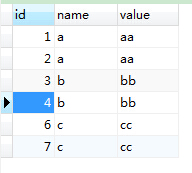
2、删除表中name和value重复的记录:
create table tmp
select name as col1, value as col2 from duplicaterow GROUP BY name, value HAVING count(*)>1;
DELETE from duplicaterow WHERE (name,value) in (select col1, col2 from tmp);
drop table tmp;
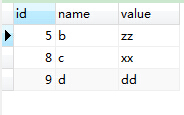
3、删除表中name和value重复的,且保留一条:
create table tmp1
SELECT name as col1,value as col2 from duplicaterow GROUP BY name,value HAVING count(*)>1;
create table tmp2
select min(id) as col1 from duplicaterow GROUP BY name,value HAVING count(*)>1;
delete from duplicaterow where (name, value) in
(select col1,col2 from tmp1) and id not in
(select col1 from tmp2);
drop table tmp1;
drop table tmp2;















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









