







1.批量爬取中国工程院院士信息,把每位院士的文字介绍保存到该院士名字为名的记事本文件中,照片保存到该院士名字为名的jpg文件中。
注意事项要安装各种数据库
比如,下面的代码用pycharm运行的话先安装数据库。
1.先打开朋友charm->
2.按terminal按键以后就会发现一个这样的窗口
在这里要输入开始安装数据库。
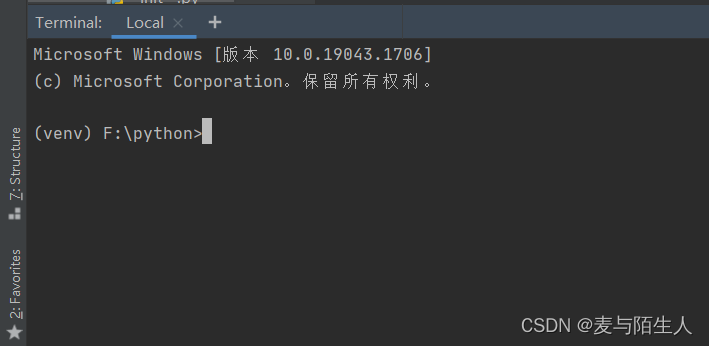
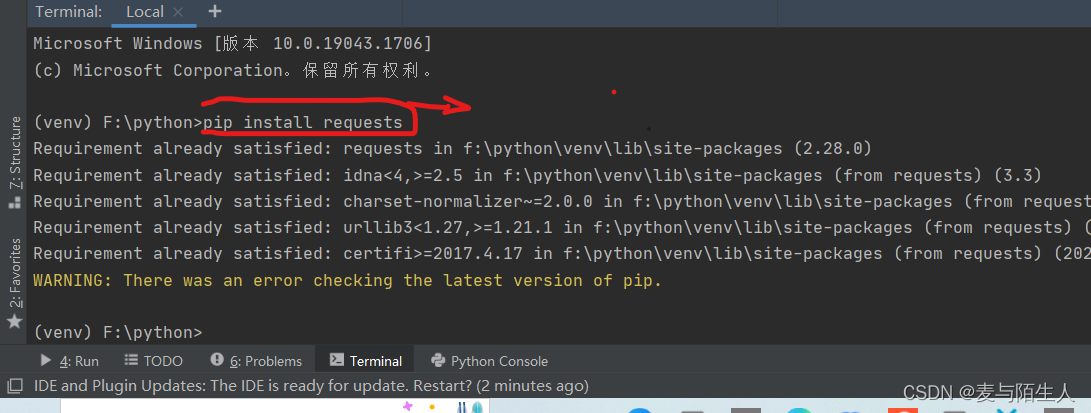
pip install pandas
pip install requests
安装完两个数据库以后可以用下面的d
import time
import requests
import re
from multiprocessing import Pool
import os
import pandas as pd
def to_exel(result_list, columns, file):
writer = pd.ExcelWriter(file)
df = pd.DataFrame(result_list, columns=columns)
# logging.info("df = pd.DataFrame(result_list, columns=columns)")
df.to_excel(writer, startrow=0, startcol=0, sheet_name='院士信息', index=False)
writer.save()
writer.close()
def run(a_url, headers):
print("子进程ID号:%d\n" % (os.getpid())) # os.getpid()进程ID
# 获取院士详细资料的页面
new_url = "https://ysg.ckcest.cn" + a_url
r = requests.get(new_url, headers)
# print(r.text)
try:
# 获取院士姓名
name = re.findall('<div><h4\sclass="row">姓名</h4><span>:</span><h4>(.*?)</h4></div>', r.text)[0]
# 性别
sex = re.findall('<div><h4\sclass="row">性别</h4><span>:</span><h4>(.*?)</h4></div>', r.text)[0]
# 族别
nation = re.findall('<div><h4\sclass="row">民族</h4><span>:</span><h4>(.*?)</h4></div>', r.text)[0]
# 本科院校
college = re.findall('<span>(.*?) .*?\s*?学士学位\s*?</span>', r.text)[0]
# 入选院士年份
year = re.findall('<div><h4 class="row">当选年份</h4><span>:</span>\s*?<h4 style="width: 300px;">\s*?中国工程院院士 \s*(.*?)<br>\s*.*?</h4>\s*?</div>', r.text, re.S)[0]
# 为每个院士创建文件夹
os.makedirs("./院士/%s" % name)
picture_url = re.findall('<img\sclass="img_fit_cover"\ssrc="(.*?)">', r.text)
picture = requests.get("http:" + picture_url[0], headers)
with open("./院士/%s/%s.jpg" % (name, name), 'wb') as f:
f.write(picture.content)
introduce_num = re.findall('html/details/(.*?)/index.html', a_url)[0]
# print(introduce_num)
introduce_url = "https://ysg.ckcest.cn/html/details/subnav/content/" + introduce_num + "/detail_grxx_grjj"
introduce_page = requests.get(introduce_url, headers)
introduce = re.findall('<div class="container"><p>(.*?)</p>', introduce_page.text)[0]
with open("./院士/%s/%s.txt" % (name, name), 'w', encoding='utf-8') as f:
f.write(introduce)
print(name, sex, nation, college, year)
print("%s院士保存成功!"%name)
return [name, sex, nation, college, year]
except (FileExistsError, IndexError) as e:
print(str(e))
if __name__ == "__main__":
# 计算耗时
end1 = time.time()
print("父进程启动:%d" % os.getpid())
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
}
results = []
for i in range(0, 1):
print("第{}轮".format(i))
url = "https://ysg.ckcest.cn/ysgList/api/index?pageSize=113&pageNum="+str(i)+"&_=1655211977545"
req = requests.get(url, headers)
# 原本re正在表达式中'\\'匹配'\',但是python中反斜杠本身就用于转义,故使用'\\\\'匹配'\'
url_lists = re.findall('<a\shref=\\\\"(.*?)\\\\"\starget=\\\\"_blank\\\\">', req.text, re.S)
# 去重
url_lists = list(set(url_lists))
processes = []
pool = Pool(10) # 设置最大进程数设置为10
for a_url in url_lists:
# 创建子进程
try:
p = pool.apply_async(func=run, args=(a_url, headers)) # func进程执行的任务, args传参数(元组)
processes.append(p)
except:
print("进程启动失败!")
pool.close()
pool.join()
for p in processes:
if p.get() is not None:
results.append(p.get())
# 等待一段时间,防止被网站认为认为是攻击而强制关闭连接
time.sleep(1)
# 写入Exel
to_exel(results, ['姓名', '性别', '族别', '本科学校', '入选院士年份'], "院士信息汇总.xlsx")
end2 = time.time()
print("耗时:%.2f秒" % (end2 - end1))
成功运行后:
2.根据院士名单,爬取该院士性别,族别信息;根据院士简介提取该院士就读本科学校,入选院士年份;将院士姓名,性别,族别信息,本科学校,入选院士年份信息写入excel文件。
代码就上面的那个。
做这个作业时遇到了不少的问题,比如exel表格输出每次这样,这让我崩溃了,因此我做了不少的功课。最终还是失败了,但灵机一动用了一下别人代码就成功了哈。
如果你们也遇到了上面的问题找办法解决,能解决的跟我说一声
谢谢大家的浏览。

















 4819
4819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











