







原因
- 精细化竞争
- 精准
- 用户精准定位
- 列表内容
- 竞争对手、外部情报
- 速度
- 客户需求
- 产品开发
- 市场投放
- 可用
- 时间延长
- 不可用时间减少
- 强度加大
- 精准
- 数据增长
- 来源的多样化
- 人工操作
- PC、手机生成
- 机器生成
- 数据的多样化
- 结构化、半结构、非结构化数据
- 数据量增长
- 每两年翻番
- 数据单位:G->T->P->E
- 软硬件技术进步,价格降价
- 需求带来供给
- 供给带来新需求
- 来源的多样化
总体
- 与OLTP共用到分离
- 硬件使用方式不同
- 处理能力有限
- 从多处OLTP系统获取数据
- 未来会不会合?
- Hana等内存数据库
- 云平台
- Oracle ExaData一体机
dw->dw2.0
- 原因
- 历史数据管理
- 企业精细化竞争需求
- 变化
- 增加了半结构化、非结构化数据
- 分交互层、集成层、近线层、离线层
- 原因
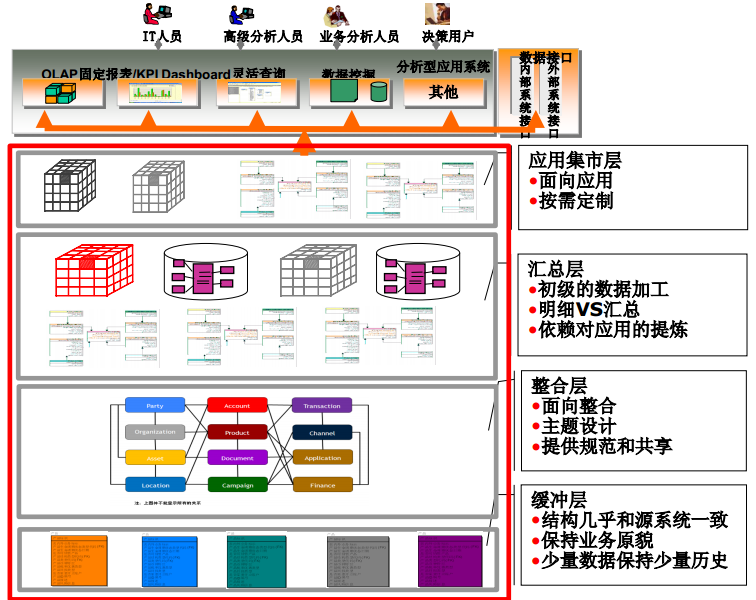
总体-DW架构
- 总体-DW2.0
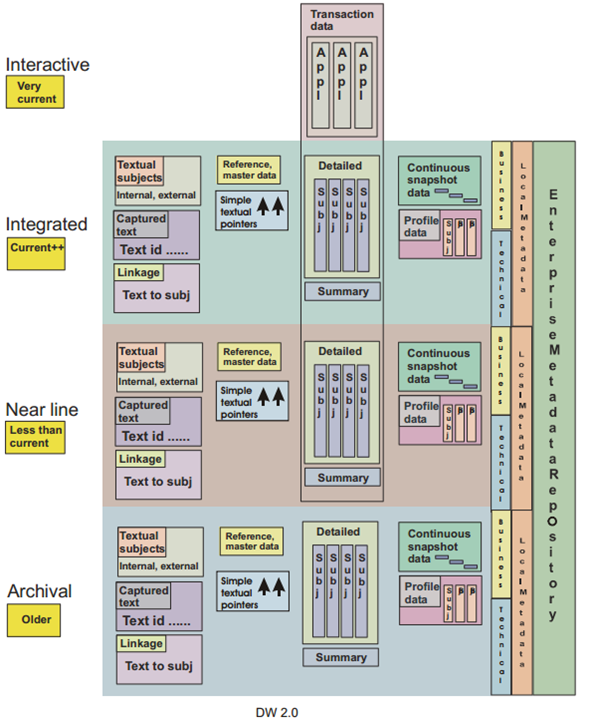
来自:DW 2.0 – The Architecture for the Next Generation of Data Warehouse
dw3.0什么样?
集中式->分布式->云
- 原因
- 单机处理能力有限
- 高可用
- 应用复杂
- 挑战
- 多服务器协作
- 跨服务器数据关联
- 单机不可靠
- 云服务的迁移
- 反向于集中式?
- 云是否合适大数据?
- 原因
结构化数据->半结构化、非结构化数据
- 体量大(Volume)
- 类型多样化(Variety)
- 处理速度快(Velocity)
- 价值密度低(Value)
- 如何高效利用半结构化、非结构化数据?
批处理->实时
- 小时、天、周计算频率到现在的分钟、秒甚至毫秒
- 主要用于决策到用于生产
- 挑战
- 获取数据
- 与历史数据集成、一致性、完整性
- 异常处理
- 提供高并发实时服务
- 批处理、实时可不可以用一套框架处理?

数据库
- SMP->MPP
- SMP代表:oracle、db2、sql server
- MPP代表:teradata、greenplum、netezza
- MPP->NoSQL
- 集群扩展能力有限
- 对非结构化数据支持不好
- 引擎较单一
- NoSQL和MPP会不会融合到一起?
- RDBMS->专有数据库
- 图数据库、多维数据库
- Hadoop
- 优点
- 较早解决了利用PC服务器扩展到上千台服务器
- 生态系统发展良好
- 大量的使用
- 缺点
- MR效率低
- 复杂
- 学习成本高
- 稳定性较差
- 优点
- Spark
- 优点
- 速度快
- 高级API,开发效率高
- 集成流式处理、数据挖掘、SQL
- 缺点
- 快速开发中
- 复杂
- 优点
- 大数据框架的发展方向
- 效率
- 总体效率
- 单机效率
- 规范
- SQL
- 事务
- JDBC、ODBC
- 稳定、易用
- 降低安装复杂度
- 降低维护难度
- 不可用时间减少
- 大一统VS专业化
- 大一统带来易使用、易维护、规范化,同时特定应用效率、成果会比较低
- 专业化带来更专业的处理方式,效率更高,同时部署、维护难度更大
- 效率
- 数据库的发展方向
- 大规模横向扩展
- 半结构、非结构化数据支持
- 与大数据架构的配合
- 数据库配合使用
数据库-其他技术
- 列式存储
- 只扫描用到的列
- 混合使用多种存储介质
- 磁带、光盘、HDD、SSD、内存
- 压缩
- CPU换IO,大部分不是时间换空间
- 分区
- Load
- Bitmap索引
- 无主外键
- 不记日志(弱日志)
- 预统计(inforbright knowledge grid)
- 部分信息统计后放入系统表,查询直接走系统表
- 还有哪些技术可以引入?
Spark是未来吗?
ETL
- 趋势分析->生产应用
- 批处理->实时处理
- 粗略->精准
单一类型->多种类型数据同时使用
- 同时使用文本文件、专有格式文件、多种数据库
ETL工具
- 专有工具,独立服务器
- 代表
- IBM DataStage、Informatica PowerCenter、Pentaho Kettle
- 优点
- 集成度高
- 学习门槛低
- 多种数据源协同工作
- 缺点
- 复杂问题灵活不够
- 单独学习
- 演进同数据库路线类似
- SMP、MPP
- HA
- 多种数据源混合使用
- ETL-数据仓库
- 直接利用数据仓库的存储与计算能力
- 优点
- 学习成本低
- 充分利用资源
- 实现灵活
- 缺点
- 必须入库才可操作
- 调度等需要单独开发
- 与其他服务争抢资源
- 基于工具或数据仓库,哪种方式在大数据处理方面占优势?
BI
- 第三方开发->自服务
- 工具更容易使用
- 用户要求响应时间更短
PC->移动
- 一切前端应用移动化
BI工具
- MOLAP生成Cube文件,需要独立服务器
- 代表
- IBM cognos、SAP BO、oracle BIEE、tableau
- 优缺点同ETL工具
- 自带数据集市
- 专有格式->通用格式
- 专有服务器->通用服务器
- 我们需要什么样的BI?
数据挖掘
- 完整工具->类库
- 工具:SAS、SPSS
- 类库:Apache Mahour、Apache Spark Mllib\ GraphX
- 专有语言->通用语言
- 专有语言:SAS、R
- 通用:Python
- 我们如何进行数据挖掘?
硬件
- 小机+盘阵->PC Server->云
- SMP结构是小型机+盘阵
- MPP也是多台小型机+盘阵
- Hadoop、Spark等使用PC服务器、云
- CPU
- 摩尔定律
- 绿色化
- HDD->SSD->Memory
- HDD存储在线;磁带存储离线数据
- HDD存储顺序访问、速度慢;随机访问且要求高的用SSD硬盘
- HDD存储顺序访问、速度慢;随机访问且要求高的用SSD硬盘;性能要求极高的用内存
- 网络100M->1000M->10G->40G->100G
- 目前主流是1000M向10G迁移阶段,机架交换机
- 40G、100G核心交换机















 5712
5712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









