







首先介绍一下federation的作用,每一个hdfs系统,都有一个namenode,namenode存放的都是datanode数据的相关信息,见下图,这个就是只有一个namenode的结构图
Background
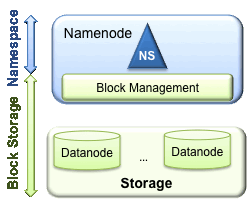
HDFS has two main layers:
- Namespace
- Consists of directories, files and blocks.
- It supports all the namespace related file system operations such as create, delete, modify and list files and directories.
Block Storage Service, which has two parts:
- Block Management (performed in the Namenode)
- Provides Datanode cluster membership by handling registrations, and periodic heart beats.
- Processes block reports and maintains location of blocks.
- Supports block related operations such as create, delete, modify and get block location.
- Manages replica placement, block replication for under replicated blocks, and deletes blocks that are over replicated.
- Storage - is provided by Datanodes by storing blocks on the local file system and allowing read/write access.
The prior HDFS architecture allows only a single namespace for the entire cluster. In that configuration, a single Namenode manages the namespace. HDFS Federation addresses this limitation by adding support for multiple Namenodes/namespaces to HDFS.
- Block Management (performed in the Namenode)
Multiple Namenodes/Namespaces
In order to scale the name service horizontally, federation uses multiple independent Namenodes/namespaces. The Namenodes are federated; the Namenodes are independent and do not require coordination with each other. The Datanodes are used as common storage for blocks by all the Namenodes. Each Datanode registers with all the Namenodes in the cluster. Datanodes send periodic heartbeats and block reports. They also handle commands from the Namenodes.
Users may use ViewFs to create personalized namespace views. ViewFs is analogous to client side mount tables in some Unix/Linux systems.
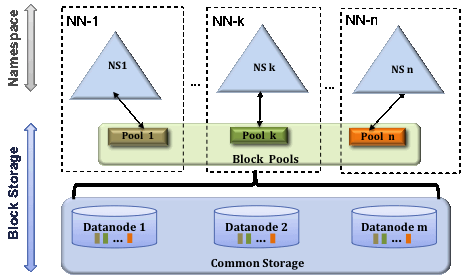
Block Pool
A Block Pool is a set of blocks that belong to a single namespace. Datanodes store blocks for all the block pools in the cluster. Each Block Pool is managed independently. This allows a namespace to generate Block IDs for new blocks without the need for coordination with the other namespaces. A Namenode failure does not prevent the Datanode from serving other Namenodes in the cluster.
A Namespace and its block pool together are called Namespace Volume. It is a self-contained unit of management. When a Namenode/namespace is deleted, the corresponding block pool at the Datanodes is deleted. Each namespace volume is upgraded as a unit, during cluster upgrade.
ClusterID
A ClusterID identifier is used to identify all the nodes in the cluster. When a Namenode is formatted, this identifier is either provided or auto generated. This ID should be used for formatting the other Namenodes into the cluster.
可以看到其实配置多个namenode,就是为了缓解单点热点,如果一个集群很大的话,那么namenode需要维护的信息也是很大的,通过以上的架构,就可以对单个热点进行分压,构造一个大的block pool提供服务。
当前架构
namenode
192-168-100-142
secondarynamenode
192-168-100-217
现在把192-168-100-217也转为namenode
配置hdfs-site.xml,加入以下参数
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>192-168-100-142:9999</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>192-168-100-142:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns1</name>
<value>192-168-100-142:9001</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>192-168-100-217:9999</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>192-168-100-217:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns2</name>
<value>192-168-100-217:9001</value>
</property>
同步hdfs-site.xml到每个节点
scp hdfs-site.xml root@192-168-100-217:/usr/local/hadoop-2.7.6/etc/hadoop
scp hdfs-site.xml root@192-168-100-225:/usr/local/hadoop-2.7.6/etc/hadoop
scp hdfs-site.xml root@192-168-100-34:/usr/local/hadoop-2.7.6/etc/hadoop
修改192-168-100-217的core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://192-168-100-217:9999</value>
</property>
停止hdfs
stop-dfs.sh
在192-168-100-217上格式化
查看clusterId
cat /opt/hadoop/dfs/name/current/VERSION
格式化新的节点
hdfs namenode -format -clusterId CID-d2640b94-0ea4-42f5-8eb9-8822f9a56765
启动hdfs
start-dfs.sh
通过jps可以查看到已经启动
[root@192-168-100-142 hadoop]# jps
8275 Jps
7830 NameNode
8087 SecondaryNameNode
[root@192-168-100-217 current]# jps
515 NameNode
902 Jps
825 SecondaryNameNode
652 DataNodeviewFS使用
现在两个namenode,那么现在问题来了,如果想要在一个namenode访问到所有nameode的路径怎么办
只能这么访问
hadoop fs -mkdir -p hdfs://192-168-100-217:9999/data01/jett
hadoop fs -put cobbler.ks hdfs://192-168-100-217:9999/data01/jett
hadoop fs -ls hdfs://192-168-100-217:9999/data01/jett
Found 1 items
-rw-r--r-- 3 root supergroup 11742 2018-06-21 14:21 hdfs://192-168-100-217:9999/data01/jett/cobbler.ks
接下来viewFS就派上用场了,实例往下看
停止HDFS
stop-dfs.sh
修改core-site.xml
<configuration xmlns:xi="http://www.w3.org/2001/XInclude">
<xi:include href="mountTable.xml"/>
<property>
<name>fs.default.name</name>
<value>viewfs://my-cluster</value>
</property>
</configuration>
创建映射表
mountTable.xml
<configuration>
<property>
<name>fs.viewfs.mounttable.my-cluster.link./data01/hank</name>
<value>hdfs://192-168-100-142:9999/data01/hank</value>
</property>
<property>
<name>fs.viewfs.mounttable.my-cluster.link./data01/jett</name>
<value>hdfs://192-168-100-217:9999/data01/jett</value>
</property>
</configuration>
修改完配置后,同步到每个节点
scp core-site.xml mountTable.xml root@192-168-100-217:/usr/local/hadoop-2.7.6/etc/hadoop
scp core-site.xml mountTable.xml root@192-168-100-225:/usr/local/hadoop-2.7.6/etc/hadoop
scp core-site.xml mountTable.xml root@192-168-100-34:/usr/local/hadoop-2.7.6/etc/hadoop
启动HDFS
start-dfs.sh
可以通过一个节点,可以看到每个namenode节点的数据
hadoop fs -ls /data01
Found 2 items
-r-xr-xr-x - root root 0 2018-06-21 14:44 /data01/hank //192-168-100-142的目录
-r-xr-xr-x - root root 0 2018-06-21 14:44 /data01/jett //192-168-100-217的目录
其实就是走了这个viewfs
hadoop fs -ls viewfs://my-cluster/data01
Found 2 items
-r-xr-xr-x - root root 0 2018-06-21 14:54 viewfs://my-cluster/data01/hank
-r-xr-xr-x - root root 0 2018-06-21 14:54 viewfs://my-cluster/data01/jett













 5129
5129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









