







【本案例完成于DeepSeek发布之前。相信未来会有更多的落地案例可以分享】
从2022年底全新对话式AI模型ChatGPT的面世到如今Deepseek爆火出圈,不过2年有余,我们足以看到未来AI/LLM对社会发展和科技创新带来了巨大前瞻性。
对金融行业而言,随着多云架构的普及和业务复杂度的提升,对系统的稳定性和高可用性要求只会愈来愈高。大模型技术与智能运维的紧急结合,已经是在发展快轨上可见的必然趋势。
公司与某上市证券企业共同携手,深度探索LLM与运维之间的合作方式,推动二者的融合创新,并以此为基底成功构建了一套全新的数智化运维告警处理体系。
客户现状与痛点
证券行业的特殊性对IT系统提出了极高的要求。我们在对客户日常运维工作的调研中发现,随着业务规模扩大,系统告警数量是呈指数级增长的。比如,去年十一前后行情火热,仅是核心交易系统就产生了超过10万条告警信息。面对如此庞大的告警量,现有的运维能力体系已经显得力不从心。
我们发现,在告警处理中存在三个典型问题:
01 告警信息碎片化
告警处理所需内容分散在各个子系统中,经常需要运维人员在多个平台间切换查找相关信息。有时候处理一个告警,需要查阅十几个文档才能找到完整的解决方案。
02 知识沉淀困难
虽然客户有知识库平台,但是大量的运维经验都以非结构化的方式存在,如工单记录、运维文档等。这些经验很难被有效利用,每次遇到类似问题还是要重新查找解决方案。
03 人员经验差异大
资深运维人员积累了丰富的处理经验,但新人往往需要很长时间才能完全掌握。当遇到复杂问题时,常需要反复咨询资深同事,这不仅降低了处理效率,还增加了人力成本。
实践分享
为了解决这些问题,我们开始探索将大模型技术应用到运维告警处理中。经过反复论证,最终选择了基于RAG(检索增强生成)等技术构建和优化智能告警处理系统。
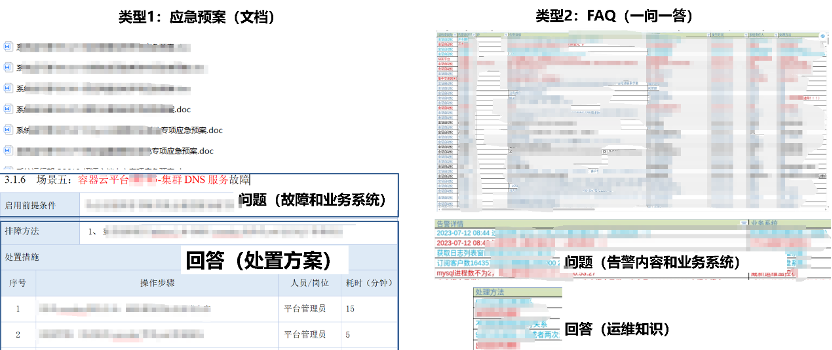
第一步:优化知识库架构
首先,我们与客户一起对现有的运维知识进行了全面梳理和重构。通过设计特定的文档结构和标签体系,将分散的运维知识进行标准化处理。例如,我们将应急处理文档统一划分为"问题描述"、"影响范围"、"处理步骤"和"注意事项"等标准化字段。
同时,我们开发了自动化的文档处理工具,能够智能识别Word、PDF等多种格式的文档内容,并将其转换为结构化的知识条目。
第二步:构建智能检索引擎
在完成知识库重构后,我们基于RAG技术构建了私域知识检索引擎。这个引擎最大的特点是采用了"双层检索"策略:
预检索优化:当收到告警时,系统会先对告警内容进行智能分析,提取关键信息并进行语义扩展。例如,当收到"数据库连接超时"告警时,系统会自动关联"数据库性能"、"网络延迟"等相关主题。
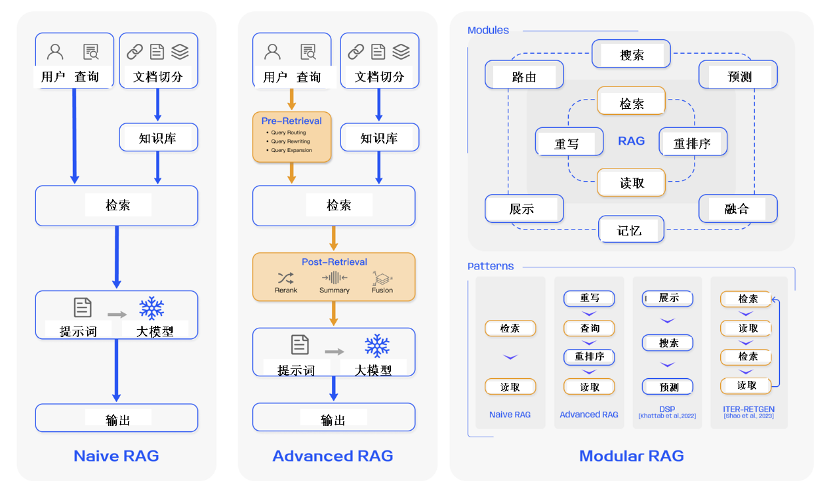
精确匹配:基于扩展后的检索词,系统会在知识库中进行多维度的相似度匹配,不仅考虑文本相似度,还会考虑历史处理记录、处理效果等因素。除了考虑技术因素,同时也会考虑不同角色的实际处理动作。

第三步:智能建议生成
检索到相关知识后,系统不是简单地展示原始文档,而是会结合当前场景进行智能总结和建议生成。这个过程包括且不限于:
上下文理解:分析告警发生的具体环境,包括系统负载、近期变更、相关告警等信息。
方案整合:将检索到的多个相关文档进行整合,生成完整的处理建议。
风险提示:自动识别处理步骤中的风险点,并给出相应的预警提示。
实践收益
1 告警平均一线处理时间从10分钟降低到3分钟,处理效率提升了67%。
2 通过智能检索和建议生成,告警处理的准确率从85%提升到95%。
错误操作导致的事故数量同比下降了80%。(初步估算)。
3 运维人员的工作负担明显减轻,特别是值守人员,不再需要经常电话请教同事或者查阅文档。初级运维人员的能力提升速度明显加快,从入职到能独立处理常见问题的时间从3个月缩短到1个月。
该合作案例,不仅让我们看到了在LLM技术的支撑下数智化运维可以发挥的巨大潜力,也印证了大模型与金融运维深度融合的必然趋势。未来,我们将继续携手合作伙伴,探索更多可能性,共同推动金融运维领域的创新发展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









