






中文乱码之填坑Java web
导言
在java web项目中,中文乱码问题屡见不鲜,继N+1次后的踩坑,我终于舍得做出了这次总结,请容许我默默擦干眼泪再娓娓道来~
常见的编码格式
first,第一个问题,为什么要有编码各种这种东西?
答:其实根本原因就是计算机不能理解我们人类的自然语言。所以为了让计算机能够理解人类的语言,并且以人类能够理解的符号表示出来——这样子,编码就诞生了!除了,计算机和人类的交流以外,不同地方的人们语言也并不完全一致,因此交流是存在多大的障碍啊~
总结下编码的的原因如下:
- 计算机是以二进制的形式存储信息的,其最小存储单元为1个字节(
byte),即8个bit,所以能够表示的字符范围为0~255个 - 人类要表示的符号太多,无法用1个字节完全表示,因此新的数据结构
char出现了,而char到byte必须编码!!!
各种语言需要交流,就必须经过翻译,而编码格式就是定义了计算机和人类语言的翻译方式,他们根据不同的编码格式按照不同的规则进行转化(类似翻译的过程),常见的编码格式有:ASII、ISO-8859-1、GB2312、GBK、UTF-8、UTF-16等。
接着,我会详细的介绍常见的编码格式:
ASCII码
ASCII是“美国信息交换标准编码”的英文字头缩写,可称之为“美标”。美标规定了用从0到127的128个数字来代表信息的规范编码,用1个字节的低7位(即除了第一个bit位)表示,
0~31是控制字符如换行、回车、删除等,32~126是打印字符,可以通过键盘输入并且能够显示出来。
显然ASCII只能表示128个字符,明显是不够用的,所以ISO组织又制订了新的编码标准……
ISO-8859-1
ISO组织为了扩展ASCII码,执行了一系列新的标准,它们就是ISO-8859-1至ISO-8859-15,其中ISO-8859-1涵盖了大多数西欧国家的语言字符,所以应用最广泛。但是ISO-8859-1仍然是单字节编码,它总共能够表示256个字符。(其实本质就是启用了ASCII码的第一个bit)
但是啊,ISO组织的制定的一系列标准虽然已经能够表示大多数西欧国家的语言字符,然而儿~他们明显没想到中文的博大精深……所以计算机遇到中文毫无疑问是gg的,呵呵~
GB2312
GB2312的全称是《信息交换用汉字编码字符集》,由中国国家标准总局1980年发布。它是双字节编码,总编码范围是
A1~F7,其中A1~A9是符号区,总共包含682个符号;B0~F7是汉字区,包含6763个汉字。GB2312编码适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312
GBK
GBK全称《汉字内码扩展规范》(GBK即“国标”、“扩展”汉语拼音的第一个字母,英文名称:Chinese Internal Code Specification) ,中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订。它的出现是为了扩展GB2312,并加入更多的汉字。它的编码范围是
8140~FEFE(去掉XX7F),总共23940个码位,它能够表示21003个汉字,它的编码是和GB2312兼容的,也就是说GB2312编码的汉字可以用GBK解码,并且不会有乱码
GB18030
国家标准GB18030《信息技术 中文编码字符集》是我国继GB2312和GB13000.1之后最重要的汉字编码标准,是我国计算机系统必须遵循的基础性标准之一.它可能是单字节、双字节或者四字节编码,与GB2312兼容,但在实际应用系统中使用得并不广泛
Unicode
Unicode(Universal Code 统一码),ISO试图创建一个全新的超语言字典,世界上的所有语言都可以通过这个字典来相互翻译。而Unicode又是Java和XML的基础
UTF-16
UTF-16具体定义了Unicode字符在计算机的存储方法。UTF-16是用2个字节来表示Unicode的转化格式,它采用定长的表示方法,即不论什么字符都用2个字节来表示。2个字节是16个bit,所以叫UTF-16。UTF-16表示字符非常方便,这就大大简化了字符串的操作,这也是Java以UTF-16作为内存的字符串存储格式的很重要的原因
UTF-8
UTF-16虽然表示上非常简单,但是有很多字符用1个字节就可以表达了,而UTF-16采用定长的方式,即1个字节可以表示的字符也用2个字节表示,导致存储空间放大了一倍,在网络带宽有限的条件下,会增大网络传输的流量。因此UTF-8采用了变长字节技术,弥补了其缺陷,UTF-8的编码字符可以由1~6个字节组成。
UTF-8编码规则如下:
- 如果是1个字节,最高位(第8位)为0,则表示这是1个ASCII字符(00~7F),可见所有的ASCII编码已经是UTF-8了
- 如果是1个字节,以
11开头,则连续的11个数暗示这个字符的字节数,例如110XXXXX代表它是双字节的UTF-8字符的首字节- 如果是1个字节,以
10开始,表示它不是首字节,则需要向前查找才能够得到当前字符的首字节
嗯嗯,花了一大堆的时间去解释各种的编码格式,这些也许看起来很乏味,而且晦涩难懂不易记忆,但是这恰恰是底层的原理实现。不过,你如果只是为了寻找java web中文的乱码的解决方案的话,可以略过,想深入了解的童鞋,欢迎详读~[耶]
大大的栗子
用于说明个各编码的转换,以及为下文做铺垫~
ISO-8859-1编码
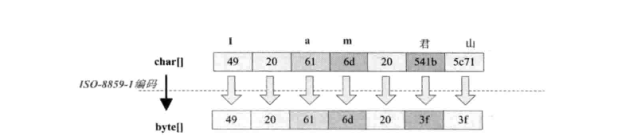
GB2312编码

GBK编码

UTF-16编码

UTF-8编码

deng…deng~ 下面进入这篇文章的主题
中文乱码?Java web中如何填坑?
数据经过网络传输都是以字节为单位的,所以所有数据都必须被序列化为字节。
一次HTTP请求的编码示例图
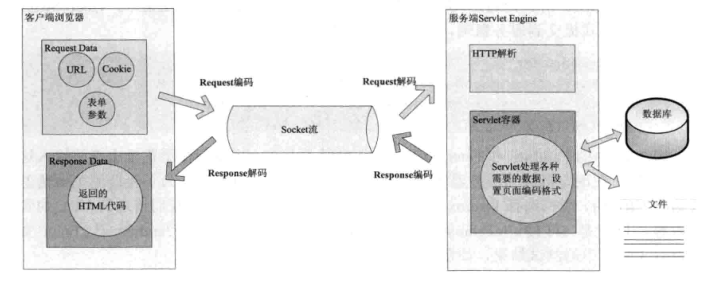
URL的编解码
举个栗子,例如以下URL:
http://localhost:8080/examples/servlets/servlet/君山?author=君山
图示:
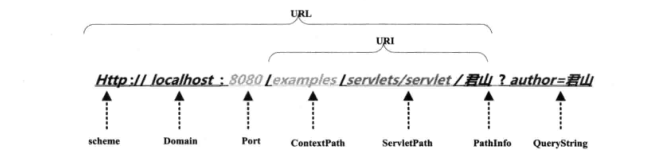
URL说明:
- Port对应Tomcat的server.xml文件的
<Connector port="8080" />中的配置 - Context Path对应Tomcat的context.xml文件的
<Context path="/examples/">中的配置 - Servlet Path 在对应的web项目下的web.xml文件的
<url-pattern>中配置 - PathInfo 是我们请求的具体Servlet
- QueryString 是要传递的参数
???那么上面的http请求中PathInfo和QueryString部分出现了中文,当这个URL在网络传输的时候会怎么编码和解析呢
chrome 54.0结果如下:
Request URL:http://localhost:8080/examples/servlets/servlet/%E5%90%9B%E5%B1%B1?author=%E5%90%9B%E5%B1%B1
- PathInfo的“君山”编码为E5 90 9B E5 B1 B1
- QueryString的“君山”编码为E5 90 9B E5 B1 B1
由上面可以知道,这两处的中文编码格式一样(不同浏览器结果不一定相同),至于为什么会有%?这是由于RFC3986编码规范定义的,浏览器编码URL是将非ASCII字符按照某种编码格式编码成16进制的数字后将每个16进制表示的字节前面加上%!而且不同浏览器对PathInfo的编码也可能不一样……呵呵,是不是有种gg的感觉?
下面我们以Tomcat为例,讲解服务端是如何对客户端(浏览器端)传送过来的URL进行解析的
- PathInfo解析
这部分解析较简单,进行解码的编码格式是在
<Connector port="8080" URIEncoding="UTF-8" />中定义的,如前面定义的解码方式是UTF-8,如果没有定义则以服务器自身默认的编码进行解码,Tomcat默认的编码是ISO-8859-1
- QueryString解析
GET方式:QueryString的解码方式要么是ContentType定义的Charset,要么使用服务器默认编码,Tomcat默认的编码是ISO-8859-1。如果要使用ContentType定义的Charset,就要在Tomcat设置
<Connector port="8080" useBodyCharacterEncoding="true" />
HTTP Header的编解码
当客户端(浏览器端)发起一个http请求时,除了URL外,Header中传递的其他的参数也可能会存在解码问题,例如Cookie,redirectPath等,这些参数的解码是在调用request.getHeader时进行的。如果请求的Header没有解码则使用服务器自身默认的编码进行解码,Tomcat默认的编码是ISO-8859-1,所以要在Header传递非ASCII字符时,先用
org.apache.catalina.util.URLEncoder编码,之后再用相应的编码格式解码即可。
PSOT表单编解码
首先,POST表单提交的参数传递方式与QueryString不同,它是通过http的body传递到服务器端的。在提交表单时,POST传递的参数客户端会按照ContentType的Charset编码格式进行编码,服务器端进行解码时也是按照ContentType的Charset编码格式进行解码(前提是设置了
useBodyCharacterEncoding="true"),所以一般不会出现问题,另外这个解码格式我们可以自己设置request.setCharacterEncoding(charset)——不过谨记的一点是要在request.getParameter调用之前设置
HTTP BODY的编解码
用户请求的资源成功获取后,这些内容将通过Response返回客户端(浏览器)。这个过程要先经过编码,再到浏览器进行解码。编解码的编码格式可以通过
response.setCharacterEncoding(charset)来设置,并且通过Header的Content-Type返回客户端,浏览器接收到返回的Socket流时将通过Content-Type的charset来解码。如果Content-Type没有定义,则通过HTML的<meta http-equiv="content-type" content="text/html;charset=utf-8">中的charset来解码
注意:
访问数据库时都是通过客户端的JDBC驱动来完成的,用JDBC来存取数据时也要和数据库内置编码保持一致,可以通过设置JDBC URL来指定,如
MySQL:url="jdbc:mysql://localhost:3306/DB?useUnicode=true&characterEncoding=utf-8"
在JS中的编解码
<html>
<head>
<script src="statics/javascript/script.js" charset="GBK"></script>
</head>script.js如下:
document.write("这是中文");
document.getElementById("testid").innerHTML = "这是中文";如果外部引用的script.js编码格式与当前页面的不一致,也会发生中文乱码问题!!!此时可以在引用外部js文件的标签里设置解码格式charset。避免中文的乱码
JS的URL编码
当js使用ajax方式向服务器端发送请求时,URL的默认编码也是受客户端(浏览器端)影响的。js的URL编码问题,掌握以下三个函数即可:
- escape()
这个函数是将ASCII字母、数字、标点符号(*+-./@_)之外的其他字符转化为Unicode编码值,并且在编码前加上
%u,解码用unescape()。不过这对函数在ES v3标准中删除了,用encodeURI()和encodeURIComponent()代替
- encodeURI()
与escape()不同,该函数对整个URL的字符进行UTF-8编码(一些特殊字符除外,例如
!,#,$,&,',(),*,+...0-9,A-z),并且在每个码值之前面加上%,解码使用decodeURI()
3.encodeURIComponent()
与encodeURI()相比,该函数彻底,除了(
!,',(),*,+,-,.,_,~,0-9,A-z)以外的所有字符均进行UTF-8编码,并且在每个码值之前面加上%,解码使用decodeURIComponent()
Java与JS编解码
java.net.URLEncoder对应encodeURIComponentjava.net.URLDecoder对应decodeURIComponent- 前端使用encodeURLComponent编码后,服务端使用URLDecoder解码可能会出现乱码问题,这一定是两端使用的编码格式不一致造成的。JS默认是UTF-8编码,而Java中文解码一般是GBK或者GB2312。解决方法如下:
前端使用encodeURIComponent(encodeURIComponent(str)),服务端使用request.getParameter用GBK解码即可获得UTF-8编码的字符串,如果Java端需要使用这个字符串,则在用UTF-8再解码一次。
其他需要编码的地方
xml:
<?xml version="1.0" encoding="UTF-8">
jsp:
<%@page contentType="text/html" pageEncoding="UTF-8" %>
参考文献
深入分析之Java Web技术内幕(修订版)——徐令波 著
更多原创文章请关注博主个人独立博客——zifengBlog














 92
92











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









