







万维网Web自动搜索引擎(技术报告)
邓雄(Johnny Deng) 2006.12
网络时代的信息量每8个月翻一番,如今的网页以100亿来计算;网络搜索已成为仅次于电子邮件的第二大网络应用。2005年中国互联网发展状况统计报告中也指出,用户在互联网上获取信息最常用的方法中,通过搜索引擎查找相关的网站占58.2%。对于有效的搜索引擎技术的研究将具有巨大的学术及商业价值。
搜索引擎技术源自于信息获取(Information Retrieval)这个学科。信息获取技术包含了信息的表述、存储、组织和对信息的访问方法。一般的信息获取系统(基于文本的)通常只提供信息的获取,而对于基于超文本的系统来说,它可以方便将信息获取与浏览结合起来,同时由于万维网信息的规模大、内容不稳定、高度的数字化和网络化,这给万维网的信息获取带来了巨大困难。目前的万维网Web搜索引擎可以分为三大类:
全文检索搜索引擎:全文搜索引擎是名副其实的搜索引擎,国外具代表性的有Google (http://www.google.com) 、yahoo(http://search.yahoo.com) 、AllTheWeb (http://www.alltheweb.com ) 等,国内著名的有百度(http://www.Baidu.com)、中搜(http://www.zhongsou.com)。它们都是通过从互联网上提取的各个网站的信息(以网页文字为主)而建立的数据库,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户,也是目前常规意义上的搜索引擎。
目录搜索引擎:目录索引虽然有搜索功能,但在严格意义上算不上是真正的搜索引擎,仅仅是按目录分类的网站链接列表而已。用户完全可以不用进行关键词查询,仅靠分类目录也可找到需要的信息。国外比较著名的目录索引搜索引擎有yahoo(http://www.yahoo.com)Open Directory Project(DMOZ)(http://www.dmoz.com/)、LookSmart(http://www.looksmart.com)等。国内的搜狐(http://www.sohu.com)、新浪(http://www.sina.com)、网易(http://www.163.com)搜索也都具有这一类功能。
元搜索引擎:元搜索引擎在接受用户查询请求时,同时在其它多个引擎上进行搜索,并将结果返回给用户。著名的元搜索引擎有Dogpile(http://www.dogpile.com)、Vivisimo(http://www.vivisimo.com)等,国内元搜索引擎中具代表性的有搜星搜索引擎(http://www.soseen.com/),优客搜索(http://www.yok.com)。在搜索结果排列方面,有的直接按来源引擎排列搜索结果,如Dogpile,有的则按自定的规则将结果重新排列组合,如Vivisimo。
其他的像新浪(http://search.sina.com.cn)、网易(http://search.163.com)、A9(http://www.A9.com)等搜索引擎都是调用其它全文检索搜索引擎,或者在其搜索结果的基础上做了二次开发。
Web搜索引擎,这里,是指一种在Web上应用的软件系统,它以一定的策略自动地,在Web上搜集和发现信息,在对信息进行处理和组织后,为用户提供Web信息的查询服务。在使用者的角度看,这种软件系统提供一个网页界面,让他通过一个浏览器提交一个查询关键词或短语,然后很快返回一个可能和用户输入内容相关的信息列表。这个列表的每个条目代表一篇网页,每个条目至少包含三个元素:1)标题:该网页内容的标题。2)URL:网页对应的全球统一定位地址。3)摘要:该网页内容的概述。即前述第一类搜索引擎。
一、 Web搜索引擎基本原理与技术
1. 搜索引擎的历史
搜索引擎技术部分源自于信息获取技术。这里我们仅阐述搜索引擎的发展历史。
1990年,为了搜集散布于网络上的FTP资源,加拿大McGill大学的计算机学院开发了名为Archie的FTP搜索引擎。此时,Web尚未出现,Archie被公认为现代搜索引擎的鼻祖。1993年,Matthew Gray开发了World Wide Web Wanderer,它是世界上第一个利用HTML网页之间的链接关系来监测Web发展规模的机器人(robot)程序。1994年7月,Michael Mauldin将John Leavitt的蜘蛛程序(spider, crawler, robot)接入到其索引程序中,创建了著名的Lycos,这是第一个现代意义的搜索引擎。1998年,Google正式诞生。Google起源于斯坦福大学的BackRub项目。1999年推出的AlltheWeb目前由Yahoo!运行。1998年左右的Ask Jeeves是一个自然搜索引擎,它能让用户输入问题来获取查询结果。此外,还有著名的HotBot,temoa,Overture,AltaVista,Metacrawler, SavvySearch等搜索引擎。
在中国,1997年,诞生了国内最早的搜索引擎天网,并于2004年推出了其更新版本,它是一个公益性质的搜索引擎。2000年,由华人学者创立的百度商业搜索引擎,至今仍然处于中国搜索引擎的领先地位。
2. Web搜索引擎工作原理与体系结构
如果将搜索引擎看作一个黑盒,那么,我们可以这样定义一个搜索引擎的功能:
在一个可以接受的时间内返回一个和用户查询(记作q)匹配的网页信息的列表(记作L)。如图1。
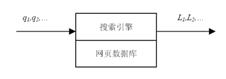
图1 搜索引擎示意图
现代大规模高质量搜索引擎一般采用如图2所示的工作流程:

图2 搜索引擎的三段式工作流程
网页搜集阶段:搜索引擎服务的基础是一大批预先搜集好的网页,获取这些网页就是在网页搜集阶段需要完成的工作。严格来讲,网页搜集阶段只考虑对海量网页数据的抓取和原始存储两个关键活动。对于网页的抓取可以利用先深/先宽以及其他组合策略(目的是搜集到尽量重要尽量多的网页);对于抓取网页的维护可以采取定期搜集,增量搜集等方式。
预处理阶段:预处理过程主要指从网页集合形成倒排文件的过程(倒排文件(inverted file)是目前公认最有效的搜索引擎索引数据结构,是用文档中所包含关键词作为索引,文档作为索引项的一种数据结构),主要包括四个方面:关键词提取(提取能够代表网页内容的一些特征,对中文而言主要采用“切词软件”切出关键词),网页消重(尽可能过滤“镜像网页”和“转载网页”),链接分析(通过对词频,文档频率,HTML标记,链接信息等分析来指示文档的相对重要性和内容的相关性等)和网页重要程度计算(预处理阶段的重要程度计算主要通过链接引用,网页自身的某些特点建立重要性指标)。
服务阶段:查询服务负责依据用户提交的查询词或短语生成一个满足一定排序要求的结果网页列表(我们假设用户是希望结果网页包含所输入查询文字的),主要实现三个方面的主要功能:查询词切分(查询词切分词表理论上必须包含在倒排文件词表中),结果排序(依据诸如查询词、用户背景、查询历史等建立查询过程中相关性指标,并与与处理阶段的文档重要性指标一起形成一个排序结果),文档摘要(包括了静态方式和动态方式,前者独立于查询,按照某种规则,实现预处理网页获取摘要;后者在响应查询时,依据查询词在文档中的位置,提起周围文字,并标亮查询词)。
基于上述流程,现代大规模高质量搜索引擎的体系结构示意如图 3a 及图3b:
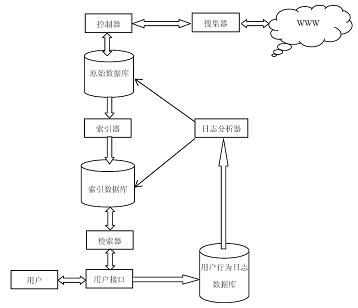
图 3a :搜索引擎的体系结构
其中大部分模块和前面的原理有直接对应。所以仅着重讨论“控制器”模块。为了向大规模搜索引擎稳定地提供网页数据,通常需要每天搜集千万级网页(Sogo搜索目前已能到达亿级的更新量),而且是持续进行,核心是要综合解决效率、质量、“礼貌”等问题。这就是控制器的作用,即:利用控制器来综合控制抓取时利用的资源(计算机设备、网络带宽、时间等),控制与被抓取网站的关系(既不要过于密集抓取一个网站,又不会漏点重要的站点),控制在有限的时间搜集的网页的重要程度(相对更“重要”的网页),控制相同网页不被重复抓取等等细节问题。
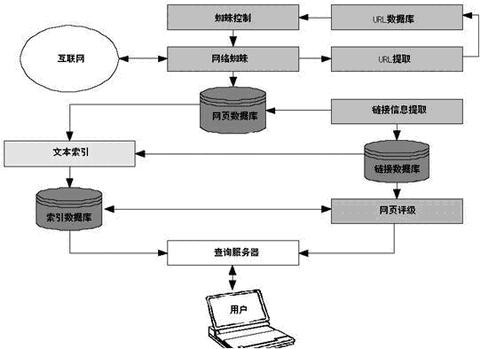
图3b搜索引擎的体系结构
“网络蜘蛛”从互联网上抓取网页,把网页送入“网页数据库”,从网页中“提取URL”,把URL送入“URL数据库”,“蜘蛛控制”得到网页的URL,控制“网络蜘蛛”抓取其它网页,反复循环直到把所有的网页抓取完成。
系统从“网页数据库”中得到文本信息,送入“文本索引”模块建立索引,形成“索引数据库”。同时进行“链接信息提取”,把链接信息(包括锚文本、链接本身等信息)送入“链接数据库”,为“网页评级”提供依据。
“用户”通过提交查询请求给“查询服务器”,服务器在“索引数据库”中进行相关网页的查找,同时“网页评级”把查询请求和链接信息结合起来对搜索结果进行相关度的评价,通过“查询服务器”按照相关度进行排序,并提取关键词的内容摘要,组织最后的页面返回给“用户”。
上述体系结构可以进一步细化为如下所示的示意性系统结构,如图4: 以一个简化了的搜索引擎将上述体系结构进一步细化,目的是突出大规模高级搜索引擎的关键技术点:
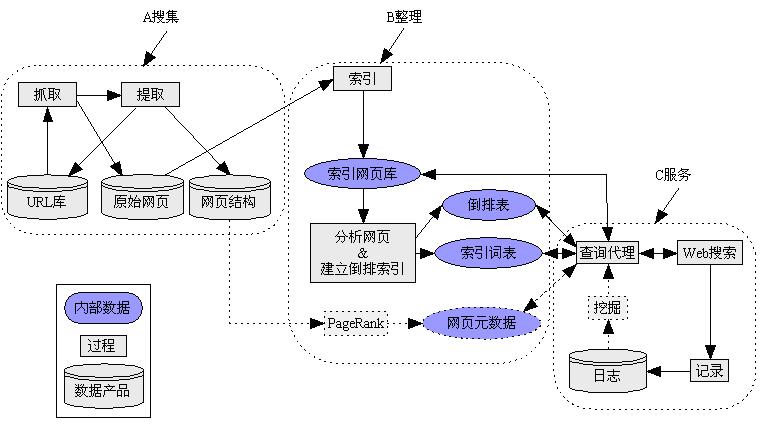
图4 搜索引擎设计模块结构
图中A表示搜集部分,B表示整理(即预处理),C代表服务部分。
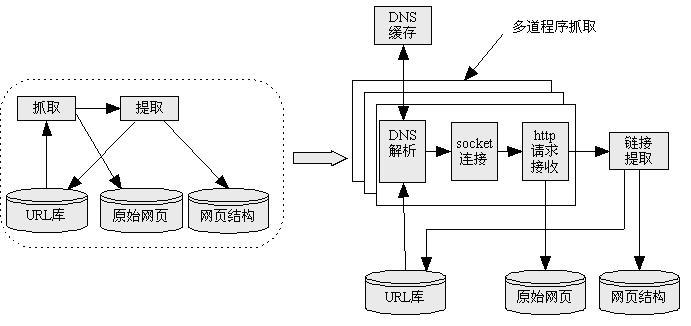
图 4C 网页搜集模块结构
l 其中A部分可以进一步细化为图 4C 所示的信息搜集模块。网页的搜集从URL库中获得输入,解析URL中标明得Web服务器地址、建立连接、发送请求和接受数据,将获得得网页数据存储在原始网页库,并从其中提取链接信息放入网页结构库,同时将待抓取的URL放入URL库,保证整个过程迭代进行,知道URL库为空。这里需要尤其提到如下4个问题:1)网页得原始网页存储库一般不能利用传统的大型关系数据库实现,这是因为,一般的大型关系数据库不能满足大规模搜索引擎的对原始网页信息处理要求,主
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1023
1023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









