









介绍
FSE是近年来在熵编码领域的一个重大成果,它有着算术编码的压缩率和哈夫曼编码的速度,热度很大,据说被用在了FaceBook的Zstd中,很是值得学习。于是花了一天时间看了很多国外的博客。可能是方法不对的原因,跳来跳去地看导致我一整天都是懵的,几乎什么也没懂。于是今天又一次静下心来回头看,认真思考后算是有了一点理解。由于没有找到足够细致的汉语资料,所以我决定记录下自己学习过程中的一些理解,既便于自己以后回顾,也有可能帮到其他人。当然,这些都是个人理解,我自己讲得通不代表就对,但我会继续学习下去直到正确理解。
主要参考以下国外的博客:
原作者的博客:http://fastcompression.blogspot.com/2013/12/finite-state-entropy-new-breed-of.html
其他国外博客:http://cbloomrants.blogspot.com/2014/02/02-18-14-understanding-ans-conclusion.html
http://www.ezcodesample.com/abs/abs_article.html
我自己没看但是为表敬意,放上ANS原论文:http://arxiv.org/abs/1311.2540
——2020疫情长假期间于成都双流
正文
FSE其实是ANS(Asymmetric Numeral System,introduced by Jarek Duda)的一种实现,其基础在于ANS。
我们首先从FSE的解码开始说起。
利用FSE 编码、解码的过程需要用到一个表FSETable,不妨设为下表所示:
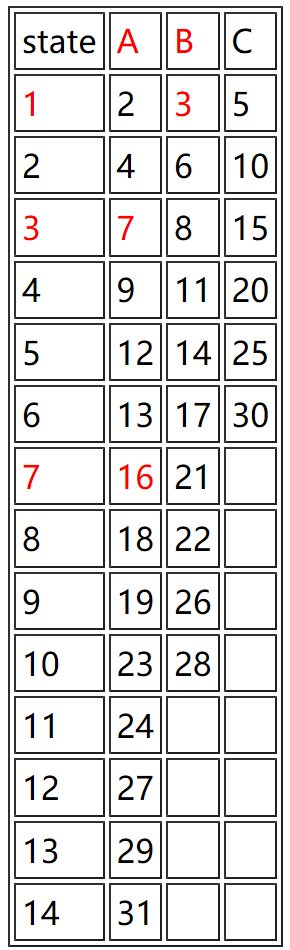
假设我们现在要解码二进制串11000011110,由于表中状态最大可达到31,所以我们需要至少5位来表示状态。第一步时,取二进制串的最后5位11110,对应十进制30,查表得到其对应的字符为C,于是解码出一个字符并得到其对应的中间状态6,110.为了得到一个5位的状态,需要再读入2位,即00,得到11000,十进制为24,查表得到其对应字符A,中间状态11,1011.需要补一个位,即10110,十进制22.由此重复下去,直到最后得到状态值为31时,即全1,我们知道状态达到了一个初始预设值,认为解码到此结束。
由此我们可以反其道得到编码的过程。假设默认初始状态为全1,即31.第一个要编码的字符为A,输出最后两个bit即11得到比特流11和中间状态7,查表得到下一个待处理的状态16;16遇到的字符为B,则输出最后一个比特0,得到新比特流110和中间状态8,查表得下一个待处理状态为22;22遇到的字符为A,于是输出最后一个比特0,得到新比特流1100和中间状态11,查表得下一个待处理状态24;24遇到字符C输出最后两个比特00得到110000和中间状态6,查表得下一个待处理状态为30.由于此时已经处理完所有的字符,于是把最终的状态30,也就是11110完全输出到比特流,于是就得到了11000011110.
当然,看完上面的编码解码过程后,又有许多新的疑问出现了。比如:编码时如何确定该输出多少个比特?这个FSETable又是如何得到的?为什么这套流程会有压缩效果?后面我会逐一解答,但前提是要先记住以上这些解码、编码的流程。
FSE作者给出的博客里有解码过程的伪代码,如下:
// One persistent variable across all loops : int state
outputSymbol (decodeTable[state].symbol);
int nbBits = decodeTable[state].nbBits;
int rest = getBits (bitStream, nbBits);
update (bitStream, nbBits);
state = decodeTable[state].newState + rest;
与上述文字描述的流程相符。
这里的状态state的个数是有限的,在FSE中默认设为4096.state可以取0到4095中的任意一个值,共12位。得到一个state后,可以通过它解码出一个字符和下一个状态。而这些信息都存储在表中。如果我们有足够多的状态数和其对应的表,那么整个解码过程将变得非常简单:
outputSymbol (decodeTable[state].symbol);
state = decodeTable[state].newState;
但显然我们不可能维持这么多的状态数,因为那将产生一个无比巨大的表,这是不现实的。FSE用12位来表示256个字符的状态,于是上述的方法便产生了。
现在请注意,我们此时一定可以意识到每次输出的比特其实就是压缩当前字符所付出的代价。只要输出的平均比特数达到它的信息熵,那么压缩的目的就达到了。
但我们会注意到,每次输出的比特数都是整数;但假如字符的频率不是2次幂的话,它的信息熵就不是整数,而是带有小数,我们该如何输出小数个比特呢?其实很简单,举个例子,假如信息熵是3.2的话,那我们就可以输出一部分3比特,再输出一部分4比特,这样平均下来就可以得到3.2比特。就好比上图那个例子,在编码字符A的时候有时候输出2个比特有时候又输出1个比特。那该如何决定输出多少个n比特和多少个n+1比特呢?
回到state上来,FSE用12位表示状态,共4096个。而被编码的字母表中的每个字母都有其统计概率。假如某字符的统计概率为5/4096,其信息熵为-log2(5/4096)=9.68。该字符总共分得4096个状态中的5个状态,而我们希望编码后它的平均码长为9.68。编码的过程中,我们必须要通过当前状态和待编码字符来确定输出多少个比特。现在,我们把状态区间分成5个部分:
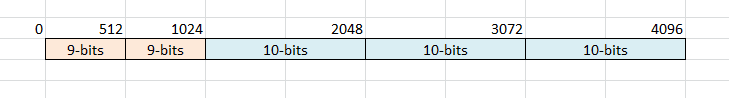
这样一来,当需要编码这个字符时,如果state在第一个和第二个小区间中,就编码为9个比特,否则编码为10个比特。如此一来,假如state是等概率出现在区间中的,则平均码长为(103/4 + 91/4)=9.75比特。可以看到,这依然比理想的熵值稍微大了一些,但已经非常接近理想熵值了,已经达到了比整数个比特要好的效果了;而且这个问题实际上可以得到一定程度的缓解,后面我会再说。
如此一来,编码过程如何确定输出比特数便知晓了,只需要为每个字符保存一个临界值,比如此例中临界值即为1024,当state>1024时,输出10位编码,否则9位。那么跟着编码的流程继续走,接下来该确定下一个状态的值了。这该如何进行呢?
实际上,状态和区间是一一对应的。对应规则是这样的:小区间在前,大区间在后,先将大区间从1开始编号,然后再编号小区间,状态从左到右依次与剩下的最小的编号对应:

这样,当编码器输出比特后得到一个中间状态,这个中间状态必然属于这之中的某一个区间,利用这个一一对应关系,可以利用这个中间状态找到一个新的状态,作为下一个状态。在第一个例子中,向左查表其实就代表了这个映射。到此,解码和编码的所有流程就都清楚了。但还有很多问题没有解决:该如何为字符分配状态值呢?
这一套分配理论是基于ANS的,涉及原理性的证明,需要看相关论文,分配的策略原理我也没理解,留待以后解答。但结论就是要尽量均匀分配最好,比如下图为16状态下为不同概率的ABCD四个字符分配的状态值:

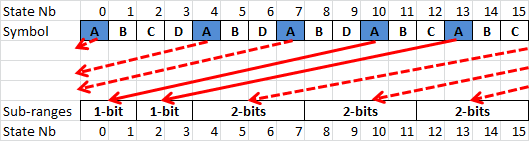
至此,这个流程应该就全部明了了。
编码:先为每个字符分配状态使其分布均匀,按照信息熵划分状态区间,并建立好一一映射关系,从一个初始码值开始。然后循环:读第一个字符,根据字符的临界值和当前状态值确定应该输出多少比特,输出比特时原状态会减去这些比特得到一个新值,根据这个新值及映射关系可以得到一个新的状态值,即为下一次的状态。巧妙的是,这个一一映射关系是“斜着的”,这就意味着,当你这次输出了一个长编码时,你的下一个状态会被向前映射,从而你下次输出短编码的几率会得到一定提升,反之亦然。这样一来,编码长度会更趋向于熵值。另外,由于在为字符分配状态时会使其尽可能地平均,因此会校准平均码长偏移问题。像之前提到过的,平均码长9.75>9.68,这种情况总会发生,当短编码区间更大时平均码长就会比理论值小,当长编码区间更长时吗就会比理论值大。但由于状态是均匀分布的且与区间一一对应,那么小区间其实是“占了便宜”的:比如5/4096的例子中,两个9比特区间只占了1/4却占了2/5的几率被中间状态映射回来,因此其实际码长其实会稍微向9比特回倾一些,就是说不会有9.75那么大。
int nbBitsOut = symbolTT[symbol].minBitsOut; // n
if (state >= symbolTT[symbol].threshold) nbBitsOut++; // or n+1
int rest = newState & mask[nbBits];
writeBits(bitStream, rest, nbBits);
intermediateState = newState - rest = decodeTable[oldState].baseline;//这里就在生成FSETable
解码过程就是反着来,利用编码输出的比特流:取最后五位作为初始状态,查表看这个状态属于哪个字符,然后循环:输出字符,查表得到当前状态的中间状态和比特数,从比特流读取比特然后加在中间状态上得到下一个状态。直到状态值为预设的初始值。
FSE只所以有压缩效果,在于它巧妙地利用变化的码长将每个字符的平均码长都变成了熵值。同时,由于它没有复杂的乘除运算,只有简单的加法、移位、逻辑运算和查表,因此速度也非常快。
此外,这些都是FSE的原理,原作者博客还有两篇讲实现上的工程技巧的,还没来得及看。这部分和ANS的状态分配原理有时间再补吧。
补充_0
疫情假期后变忙了,都忘了博客这回事了。。。回来发现评论有不少人提问,被晾了几个月。
又看了一下自己的这篇博客,确实是比较混乱,许多前面的问题要在后面解答,后面其实埋藏了很多晦涩的伏笔,但我没时间,只能这样了。只是建议一定要先通读完(不管前面的懂没懂),然后再回头看。
这里补充一点说明,编码时的中间状态其实就是一一映射后的区间号。某字符被分配了M个状态,那就会将状态分为M个区间,因此可以将状态和区间一一对应,且中间状态总会不超过最大区间号。
——2020.11.04于哈深














 6568
6568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









