







l> 我的新书《Android App开发入门与实战》已于2020年8月由人民邮电出版社出版,欢迎购买。点击进入详情
1.开发环境
- IDE: PyCharm 2021.2.1 (Professional Edition)
- Python: 3.9.7
2.第三方库
- urllib.request:网络请求
- re:正则表达式
- os:创建本地文件夹
3.实现
1.分析url格式
我们随便找一个看妹子图片的网站,看到第一页的格式是https://pic.netbian.com/4kmeinv/index.html,
第二页开始页面的格式是https://pic.netbian.com/4kmeinv/index_{N}.html。
我们需要针对这两种情况提供对应的url。
2.分析图片格式
我们通过chrome的查看网页源代码,可以看到图片的格式:
<img src="/uploads/allimg/210920/180538-1632132338b0a0.jpg" alt="cos 白发美女 4k高清壁纸" />
那我们可以通过正则表达式将图片的src的值过滤出来:
reg = r'src="(.+?\.jpg)" alt='
imgreg = re.compile(reg)
imglist = imgreg.findall(requesthtml)
3.保存图片到本地
urllib.request.urlretrieve
这个函数可以将图片保存在本地,它有两个参数,第一个是图片url,第二个是本地路径。
图片url就是我们上面回去到的src里面的值,外加前面网站域名。
本地路径我们可以通过下面的方法创建:
path = 'C:\\meinv'
if not os.path.isdir(path):
os.makedirs(path)
paths = path + '\\'
4.输入页数
我们可以通过下面的代码在用户运行python的时候让用户自己输入想要下载哪些页的妹纸图片:
pages = int(input("请输入总页数:"))
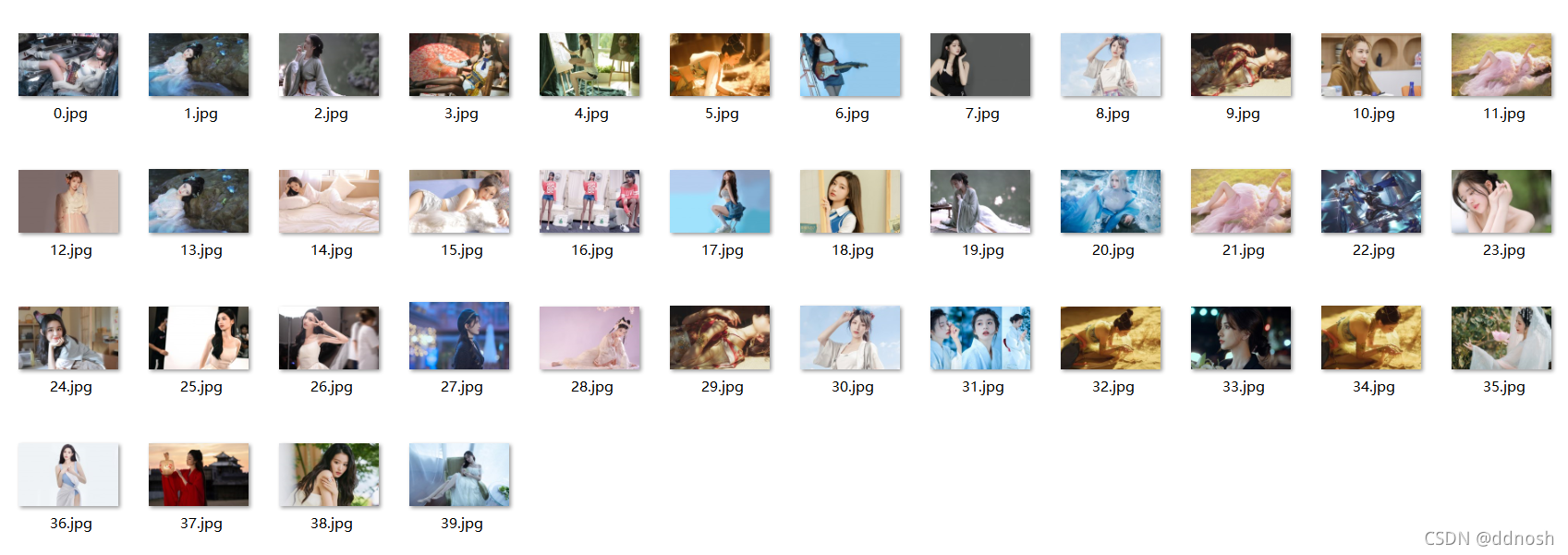
4.效果
5.Github源码
6.增强版
https://blog.csdn.net/ddnosh/article/details/120738036
欢迎关注我的技术公众号:国民程序员,我们的目标:输出干货
- 每天分享原创技术文章
- 海量免费技术资料和视频学习资源
- 分享赚钱门道,带领程序员走向财务自由




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









