






文章目录
- 模型分层
- 计算模型
- 分布式缓存
- 管理内存
- `window`出现的数据倾斜
- 使用聚合函数处理热点数据
- `Flink` `vs` `Spark`
- 泛型擦除
- 集群角色
- 部署模式
- `Yarn` 运行模式
- `Flink on K8s`
- 执行图有哪几种
- 分区
- 任务槽`Task slot`
- 并行度
- 窗口理解
- `Flink SQL` 是如何实现的
- 海量数据的高效去重
- `Flink`中`Task`如何做到数据交换
- `Flink`设置并行度的方式
- 水印`watermark`
- 分布式快照
- 状态管理
- 状态机制
- 状态后端的选择
- 状态的过期机制
- 状态的区别
- 状态的TTL
- 状态过期数据处理
- `Flink/Spark/Hive SQL`的执行原理
- 反压(背压)
- 一致性的保持
- 延迟数据的处理
- 双流`join`
- 数据倾斜
- `Flink`任务延时高,如何入手
- 算子链
- `Flink CEP`编程中当状态没有到达的时候会将数据保存在哪里
- aggregate 和 process 计算区别
- 序列化
- 任务的并行度的评估
- 合理评估任务最大并行度
- 保障实时指标的质量
- CDC
- 保存点
模型分层
-
RuntimeFlink程序的最底层入口。提供了基础的核心接口完成流、状态、事件、时间等复杂操作,功能灵活。 -
DataStream API面向开发者,基于
Runtime层的抽象。 -
Table API统一
DataStream/DataSet,抽象成带有Schema信息的表结构. 通过表操作和注册表完成数据计算。 -
SQL面向数据分析和开发人员,抽象为
SQL操作。
计算模型
source支持多数据源输入transformation数据的转换过程sink数据的输出

分布式缓存
目的是在本地读取文件,并把他放在TaskManager节点中,防止task重复拉取
object Distribute_cache {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
//1"开启分布式缓存
val path = "hdfs://hadoop01:9000/score"
env.registerCachedFile(path , "Distribute_cache")
//3:开始进行关联操作
DS<String>.map(new MyJoinmap()).print()
}
}
class MyJoinmap() extends RichMapFunction[Clazz , ArrayBuffer[INFO]]{
private var myLine = new ListBuffer[String]
override def open(parameters: Configuration): Unit = {
val file = getRuntimeContext.getDistributedCache.getFile("Distribute_cache")
}
//在map函数下进行关联操作
override def map(value: Clazz): ArrayBuffer[INFO] = {
}
}
管理内存
Flink是将对象都序列化到一个预分配的内存块上,并且大量使用了堆外内存。如果处理数据超过了内存大小,会使部分数据存储到硬盘上。同时Flink为了直接操作二进制数据而实现了自己的序列换框架。
-
堆内内存
Flink程序在创建对象后,JVM会在堆内内存中分配一定大小的空间,创建Class对象并返回对象引用,Flink保存对象引用,同时记录占用的内存信息。 -
堆外内存
堆外内存其底层调用
基于C的JDK Unsafe类方法,通过指针直接进行内存的操作,包括内存空间的申请、使用、删除释放等
JobManager 内存管理
# JobManager总进程内存
jobmanager.memory.process.size:
# 作业管理器的 JVM 堆内存大小
jobmanager.memory.heap.size:
#作业管理器的堆外内存大小。此选项涵盖所有堆外内存使用。
jobmanager.memory.off-heap.size:
在这里插入图片描述
TaskManager 内存
TaskManager内存包含JVM堆内内存、JVM堆外内存以及JVM MetaData内存三大块。
JVM堆内内存又包含Framework Heap(框架堆内存)和Task Heap(任务堆内存)。JVM堆外内存包含Memory memory托管内存,用于保存排序、结果缓存、状态后端数据等。Direct Memory直接内存Framework Off-Heap Memory:Flink框架的堆外内存。Task Off-Heap:Task的堆外内存Network Memory:网络内存
/ tm的框架堆内内存
taskmanager.memory.framework.heap.size=
// tm的任务堆内内存
taskmanager.memory.task.heap.size
// Flink管理的原生托管内存
taskmanager.memory.managed.size=
taskmanager.memory.managed.fraction=
// Flink 框架堆外内存
taskmanager.memory.framework.off-heap.size=
// Task 堆外内存
taskmanager.memory.task.off-heap.size=
// 网络数据交换所使用的堆外内存大小
taskmanager.memory.network.min: 64mb
taskmanager.memory.network.max: 1gb
taskmanager.memory.network.fraction: 0.1
window出现的数据倾斜
window数据倾斜是指:数据在不同的窗口内堆积的数据量相差过多,本质上还是不同的Task的数据相差太大。
- 在数据进入窗口之前对数据进行预聚合,减少进入窗口的数据量;
- 重新设计窗口聚合的
key,使不同的窗口的数据量尽量相同; - 使用再平衡的算子,如
rebalance,将数据再次打散,均匀发送到下游。
使用聚合函数处理热点数据
- 对热点数据单独处理,可以使热点数据不会影响正常的服务;
- 对热点数据拆分聚合,也是单独对热点数据单独处理;
- 上游的
slot将数据汇聚成一个批次发送到下一个slot中,可以将该批次值设置大点。
Flink vs Spark
Spark | Flink |
|---|---|
| RDD模型 | 基于数据流,基于事件驱动 |
| 微批处理(一个批完成后才能处理下一个) | 无界实时流处理(事件在一个节点处理完后发往下一个节点) |
| 处理时间 | 事件时间,插入时间,处理时间,水印 |
| 窗口必须是批的整数倍 | 窗口类型多 |
| 没有状态 | 有状态 |
| 没有流式SQL | 有流式SQL |
| 提供统一的批处理和流处理API,支持高级编程语言和SQL | 均提供统一的批处理和流处理API,支持高级编程语言和SQL |
| 都基于内存计算,速度快 | 都基于内存计算,速度快 |
| 都支持Exactly-once一致性 | 都支持Exactly-once一致性 |
| 都有完善的故障恢复机制 | 都有完善的故障恢复机制 |
泛型擦除
Flink具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。由于泛型擦除的存在,在某些情况下,自动提取的信息不够精细,需要采取显式提供类型信息,才能使应用程序正常工作。
集群角色
-
**客户端
Client:**代码由客户端获取并装换,然后提交给JobManager; -
JobManager:对作业进行调度管理,对作业转换为任务,并将任务发送给TaskManager, 对失败任务做出反应,协调checkpoint -
**
TaskManager:**处理数据任务,缓存和交换数据流(数据从一个tm传到另一个tm)- **
task slot:**资源调度的最小单位,并发/并行处理 task 的数量,一个task slot中可以执行多个算子。
- **
-
**
RecourceManager:**负责集群中的资源提供、回收、分配、管理Task slots -
Dispatcher:提交Flink应用程序执行,为每个提交的作业启动一个新的JobMaster -
**
JobMaster:**管理单个JobGraph的执行,每个作业都有自己的JobMaster
部署模式
-
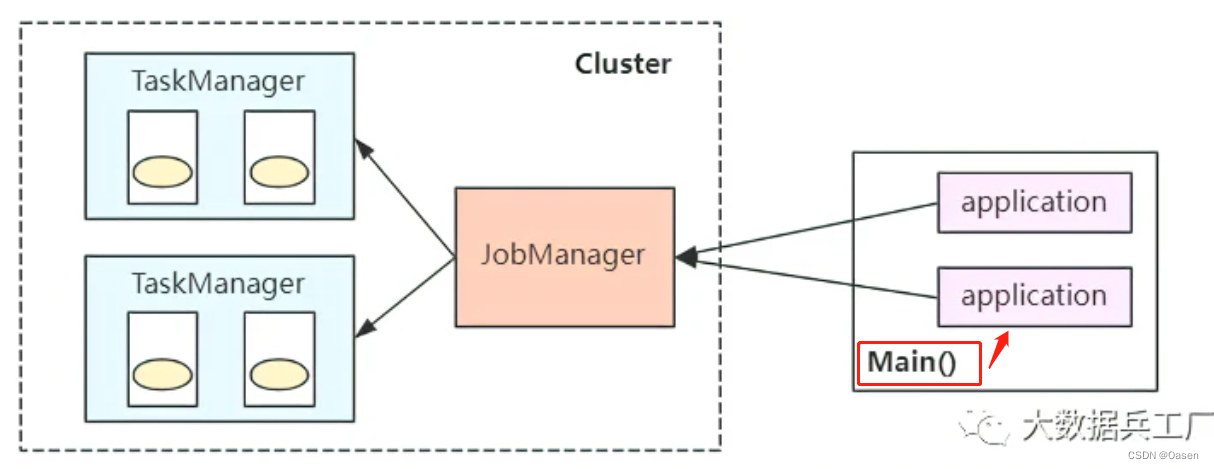
会话模式
所有任务都共享集群中
JobManager,所有任务都会竞争集群的资源-
适用于短周期、小容量的任务
-
减少资源和线程的切换
-
共享一个
jobManager,jobmanager压力大
bin/flink run -c com.wc.SocketStreamWordCount FlinkTutorial-1.0.jar -
-
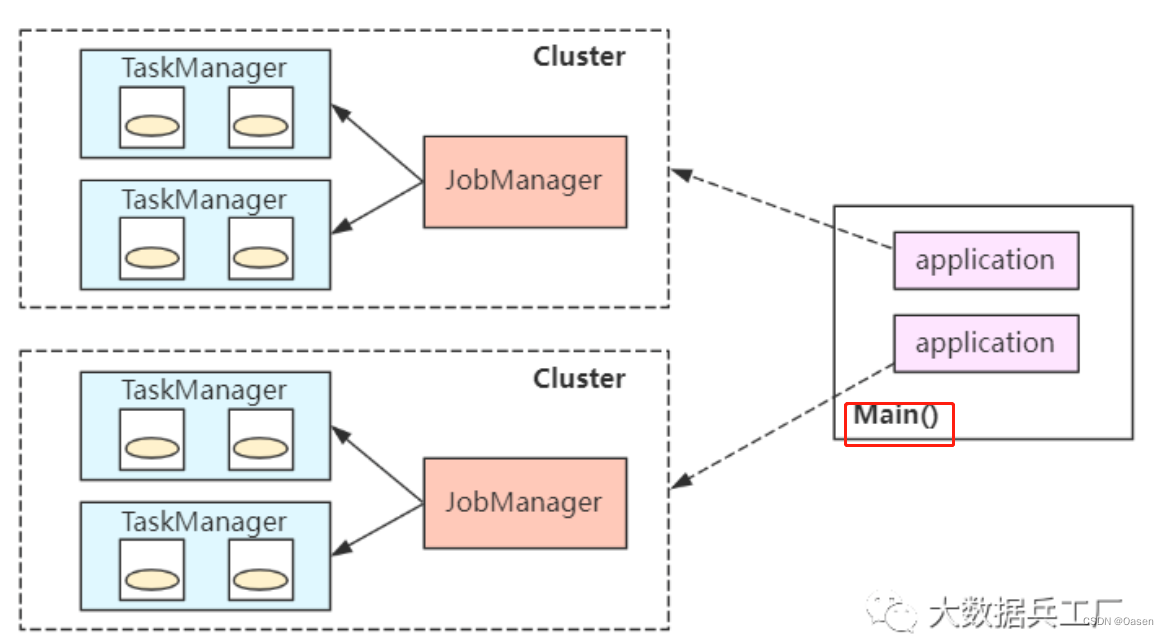
单作业模式
每个任务都会启动一个单独的集群,集群之间相互独立。
- 每个任务完成后销毁,最大限度保障资源隔离
- 每个
Job均衡分发自身的JobManager,单独进行job的调度和执行 - 每个
job均维护一个集群,启动、销毁以及资源请求消耗时间长,因此比较适用于长时间的任务执行
bin/flink run -d -t yarn-per-job -c com.wc.SocketStreamWordCount FlinkTutorial-1.0.jar
-
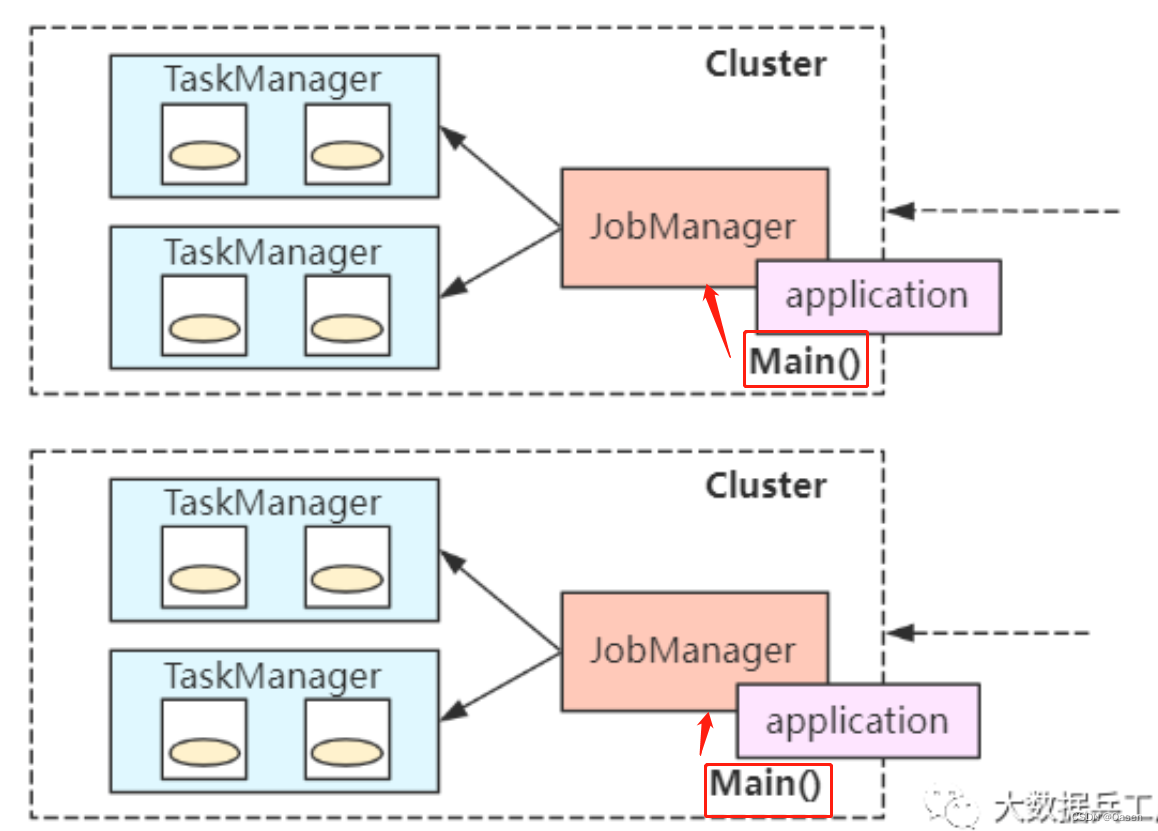
应用模式
每个任务都会启动一个
jobManager,只是**Application与JobManager合二为一。Main方法此时在JobManager中执行**。bin/flink run-application -t yarn-application -c com.wc.SocketStreamWordCount FlinkTutorial-1.0.jar
Yarn 运行模式
YARN上运行过程是:客户端Client把Flink应用程序提交给YARN的ResourceManager, YARN的ResourceManager会向NM申请容器,启动JobManager和TaskManager的实例,从而启动集群。Flink会根据运行在JobManager上的作业所需要的Slot数量动态分配TaskManager资源。
- 通过脚本启动执行。客户端
Client基于用户代码,生成流图(StreamGraph),再在JobManager中生成工作图(JobGraph), 同时将任务提交给ResourceManager; ResourceManager选择一个启动NM,启动ApplicaitonMaster;ApplicationMaster启动JobManager, 并将工作图(JobGraph)生成执行图(ExecutionGraph);JobManager向ResourceManager申请资源,资源被封装在slot槽;ResourceManager启动一定数量的TaskManager,分配一定的slotTaskManager向JobManager注册;JobManager将要执行的任务分发到TaskManager,执行任务。
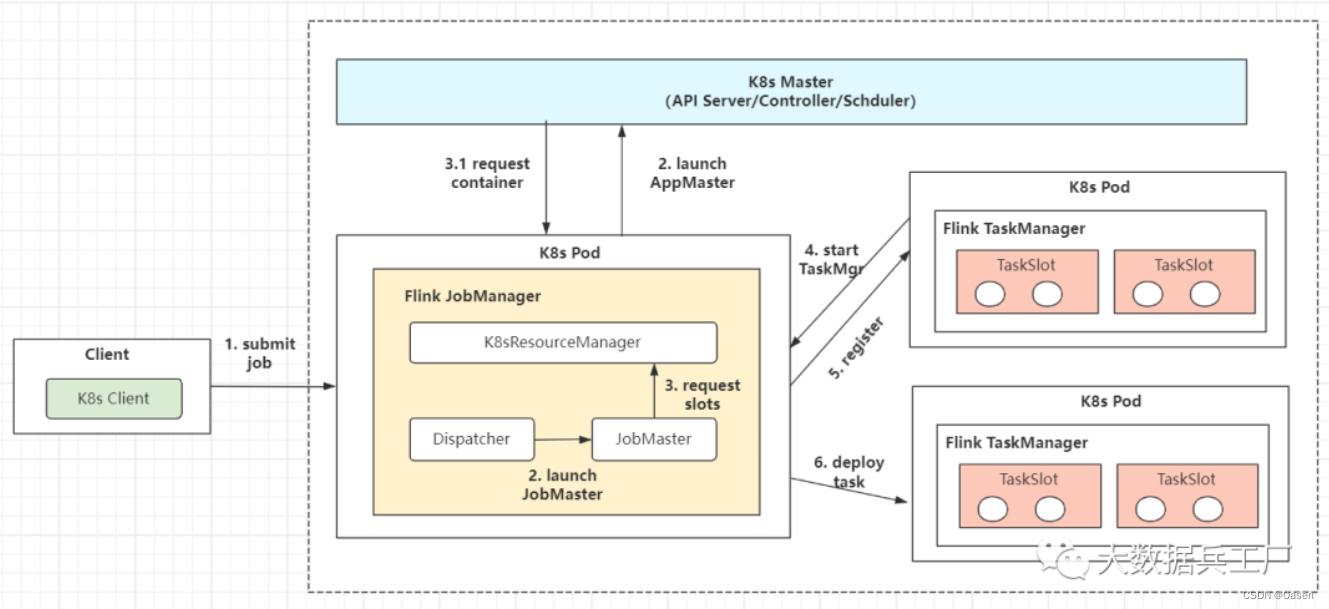
Flink on K8s
k8s是一个强大的,可移植的高性能的容器编排工具。这里的容器指的是docker容器化技术,它通过将执行环境和配置打包成镜像服务,在任务环境下快速部署docker容器,提供基础的环境服务。解决之前部署服务速度慢,迁移难,高成本的问题。
k8s提供了一套完整地容器化编排解决方案,实现容器发现和调度,负载均衡,弹性扩容,数据卷挂载等服务。
Flink on k8s与Flink on yarn提交比较类似,TaskManager和JobManager等组件变成了k8s pod角色
K8s集群根据提交的配置文件启动K8sMaster和TaskManager(K8s Pod对象)- 依次启动
Flink的JobManager、JobMaster、Deploy和K8sRM进程(K8s Pod对象);过程中完成slots请求和ExecutionGraph的生成动作。 TaskManager注册Slots、JobManager请求Slots并分配任务- 部署
Task执行并反馈状态
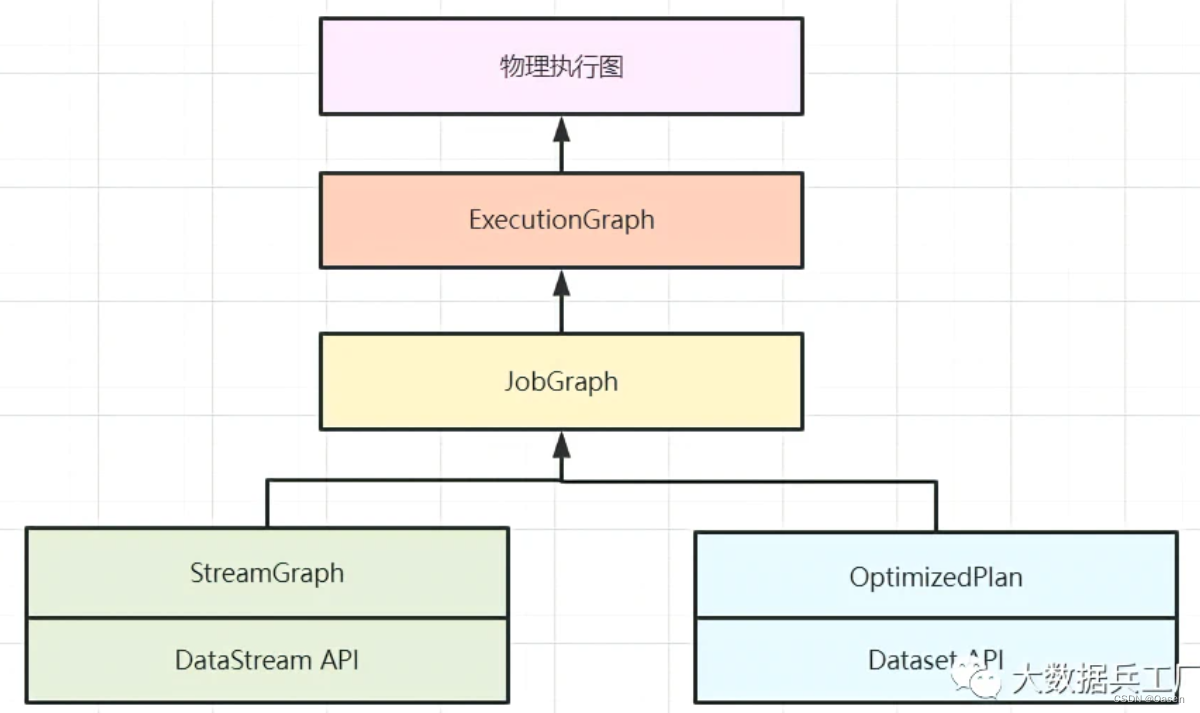
执行图有哪几种
-
**
StreamGraph**(Client)编写的流程图,通过
Stream API生成,是执行图的最原始拓扑数据结构 -
**
JobGraph**(Client->JobManager)StreamGraph在Client中经过算子chain链做合并优化,将其转换为JobGraph拓扑图。并被提交到JobManager。 -
ExecutionGraph(JobManager)JobManager中将JobGraph进一步转换为ExecutionGraph,此时ExecutuonGraph根据算子配置的并行度转变为并行化的Graph拓扑结构。 -
物理执行图 (
JobManager->TaskManager)JobManager进行Job调度,TaskManager最终部署Task的图结构。
分区
Flink在消费Kafka数据时,最好是保持上下游并行度一致。即;Kafka有多少个分区,那么Flink消费者的并行度与之相同。
K
a
f
k
a
的分区数
=
F
l
i
n
k
的并行度
Kafka的分区数= Flink的并行度
Kafka的分区数=Flink的并行度
不过,在某些情况下,为了提高数据的处理速度,需要将Flink消费者的并行度设置得大于Kafka分区数。但是这样设置是有某些消费者是无法消费到数据,那么需要对消费者之后的数据处理进行重分区。
K
a
f
k
a
的分区数
<
=
F
l
i
n
k
的并行度
+
重分区
Kafka的分区数 <= Flink的并行度 + 重分区
Kafka的分区数<=Flink的并行度+重分区
-
随机分配 –
shuffle数据随机的分配到下游算子的并行任务中,使用的均匀分配,数据随机打乱,均匀传递到下游任务。所以每次分配在下游分区时,数据是不相同的。
-
轮询分配 –
rebalance数据按照先后顺序依次分发分配,按照轮询的方式,将数据平均分配到下游的并行任务中。
-
重缩放 –
rescala按照轮询的方式,将数据的发送到下游的一部分任务中。(不完全覆盖所有下游分区)
-
广播 –
broadcast数据在不同的分区中都保留一份,可能会被重复处理
-
全局分区 –
global数据被分配到下游的第一个子任务中
-
自定义分区 –
partitioner
任务槽Task slot
为了控制并发量,需要在TaskManager上对每个任务运行所占用的资源做出明确的划分,这就是任务槽(task slots)。
任务槽决定了TaskManager能够并行处理的任务数量。
任务槽(task slot)表示了 TaskManager 拥有固定大小集合的计算资源,这些资源就是用来独立执行一个子任务的。
slot目前仅仅用来隔离内存,不会涉及CPU的隔离。在具体应用时,可以将slot数量配置为机器的CPU核心数,尽量避免不同任务之间对CPU的竞争
TaskManager具有的并发执行能 力,可以通过参数 taskmanager.numberOfTaskSlots 进行配置
并行度
一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)
包含并行子任务的数据流,就是并行数据流,它需要多个分区(stream partition)来分配并行任务。
并行度是动态概念,也就是 TaskManager 运行程序时实际使用的并发能力,可以通过参数 parallelism.default进行配置
窗口理解
窗口可以理解成一个桶, 在Flink中,窗口可以把流切割成有限大小的多个“存储桶”(bucket);每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。
Flink 中窗口并不是静态准备好的,而是动态创建——当有落在这个窗口区间范围的数据达到时,才创建对应的窗口。
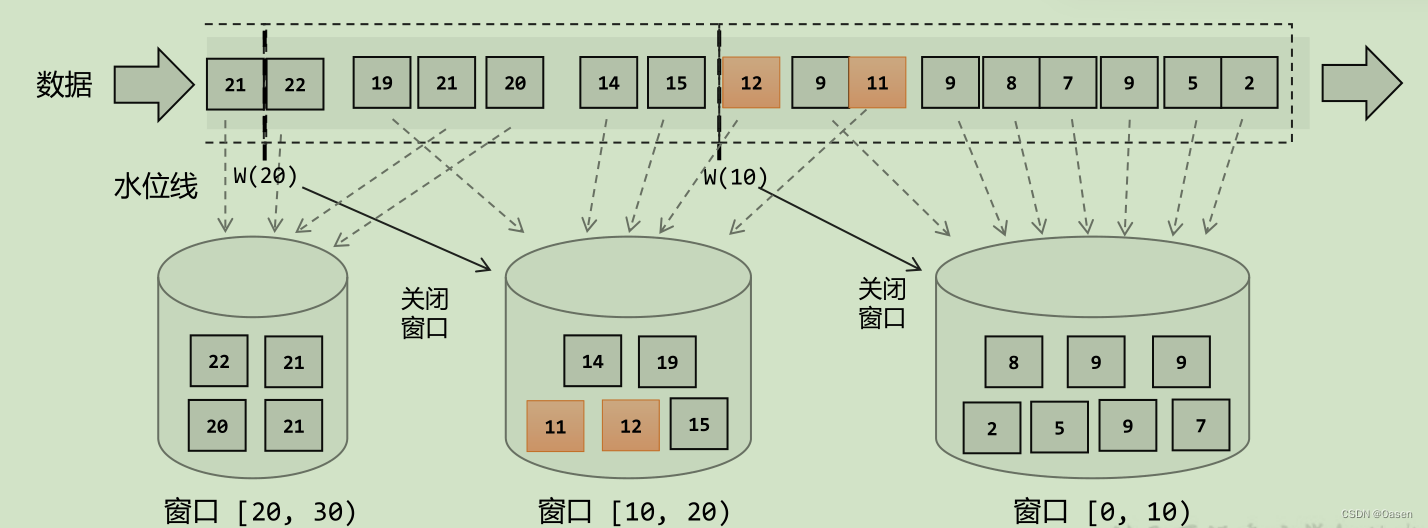
- 滚动窗口
- 滑动窗口
- 会话窗口
- 全局窗口
Flink SQL 是如何实现的
SQL query经过Calcite解析转换成SQL节点树,通过验证后构建成Calcite的抽象语法树(Logical plan)。Table API上的调用会构建成Table API的抽象语法树,并通过Calcite提供的RelBuilder转变成Calcite的逻辑计划(Logical plan)。- 逻辑计划被优化器优化后,转化成物理计划和
JobGraph; - 在提交任务后会分发到各个
TaskManager中运行,在运行时会使用Janino编译器编译代码后运行。

解析 -> 编译 -> 优化 -> 执行
抽象语法树 -> 逻辑计划 -> 执行计划
海量数据的高效去重
- 基于状态后端,内存去重。采用
Hashset等数据结构,读取数据中类似主键等唯一性标识字段,在内存中存储并进行去重判断。 - 基于
HyperLog,不是精准的去重 - 基于布隆过滤器,快速判断一个key是否存在于某容器,不存在就直接返回。
- 基于
BitMap,用一个bit位来标记某个元素对应的Value,而Key即是该元素。由于采用了Bit为单位来存储数据,因此可以大大节省存储空间。 - 基于外部数据库,选择使用
Redis或者HBase存储数据,我们只需要设计好存储的Key即可,不需要关心Flink任务重启造成的状态丢失问题。使用Redis Key去重。借助Redis的Hset等特殊数据类型,自动完成Key去重。 DataFrame/SQL场景,使用**group by、over、window开窗**等SQL函数去重- 利用**
groupByKey**等聚合算子去重
Flink中Task如何做到数据交换
在一个Flink Job中,数据需要在不同的task中进行交换,整个数据交换是有TaskManager负责的,TaskManager的网络组件首先从缓冲buffer中收集 records,然后再发送。Records并不是一个一个被发送的,是积累一个批次再发送,batch 技术可以更加高效的利用网络资源。
Flink设置并行度的方式
- 代码层面:操作算子层面
map().setParallelism(10) - 执行环境层面
./flink -p 10 - 客户端层面
env.setParallelism(10) - 系统层面
fink-conf.yaml
优先级依次降低
水印watermark
Flink中的水印是处理延迟数据的优化机制。当这类数据因为某些原因导致乱序或延迟到达,这类数据不能丢弃也不能无限等待。
在一个窗口内,当位于窗口(最大事件时间戳 - watermark)>= (当前窗口最小时间戳 + 窗口大小) 的数据到达后,表明该窗口内的所有数据均已到达,此时不会再等待,直接触发窗口计算。
作用
- 规定了数据延迟处理的最优判定,即
watermark时间间隔; - 较为完善的处理了数据乱序问题,从而输出预期结果;
- 结合最大延迟时间和侧输出流机制,彻底解决数据延迟。
形式
-
有序流中内置水位线设置
对于有序流,主要特点就是时间戳单调增长,所以永远不会出现迟到的数据。WatermarkStrategy.forMonotonousTimestamps() -
乱序流中内置水位线设置
由于乱序流中需要等待迟到数据到齐,所以必须设置一个固定的延迟时间。WatermarkStrategy. forBoundedOutOfOrderness(Duration.ofSeconds(3)) -
自定义水位线生成器
-
周期性水位线生成器(Periodic Generator)
周期性生成器一般是通过onEvent()观察判断输入的事件,而在onPeriodicEmit()里发出水位线。 -
断点式水位线生成器 (Punctuated Generator)
断点式生成器会不停地检测onEvent()中的事件,当发现带有水位线信息的事件时,就会立即 发出水位线。 -
在数据源中发送水位线
自定义的数据源中抽取事件时间,然后发送水位线
-
水位线的传递
在流处理中,上游任务处理完水位线、时钟改变之后,要把当前的水位线再次发出,广播给所有的下游子任务。而当一个任务接收到多个上游并行任务传递来的水位线时,应该以最小的那个作为当前任务的事件时间。
比如:有两条流在进行join时,A流的时间为1,B流的时间为2,那么此时当前的事件时间最小为1。接下来A流时间为3,而B流的时间没有变,那么此时当前的事件时间最小为2。当前的事件时间只会递增而不是减少。
分布式快照
分布式快照 ,一致性检查点 Checkpoint,某个时间点上所有任务(一个完整的Job)状态的一份拷贝,该时间点也是所有任务刚好处理完一个相同数据的时间。该行为是采取一步插入barrier检查点的方式。
- 触发检查点:
JobManager向source发送barrier; barrier发送:向下游广播发送;barrier对齐:下游需要收到上游所有并行度传递过来的barrier才可以做状态的保存;- 状态保存:有状态的算子将状态保存持久化;
- 先处理缓冲区的数据(在等待其他
barrier时的,该分区已经来的数据,在对齐barrier分区中不会被处理后面barrier的数据,除非其他barrier都已经完成,完成快照后),然后再正常继续处理。 - 当
JobManager收到所有算子任务成功保存状态的信息,就可以确认当前检查点已经保存成功了。
-
对齐
barrier
等待上游多个barrier全部到齐处理后,才能将该算子进行状态的保存。 -
非对齐
barrier当流速快的Barrier流到下游算子当中,此时不理会此
Barrier,正常进行后续数据的计算。当流速慢的Barrier到来的时候,才完成进行快照,但是不会将后续数据快照,而是仍作为后续的Barrier中的数据。
状态管理
在 Flink 中状态管理的模块就是我们所熟知的 Checkpoint \ Savepoint。
状态机制
- 状态:本质上是数据,包括
MapState,ValueState,ListState - 状态后端:
HashState,FileState,RocksDBState; - 状态管理:定时将状态后端中存储的状态同步到远程的存储系统的组件中。在任务故障转移时,从远程将状态数据恢复到任务中。
RocksDBState只会影响任务中的keyed-state存储的方式和地方,对operator-state不会受到影响。
-
keyed-state键值状态以
k-v形式存储,状态值和key绑定,紧跟在keyBy之后才能使用的状态。 -
operator-state操作状态非
k-v形式的算子结构,状态值与算子绑定,如kafkaoffset被保存在ListState
状态后端的选择
-
MemoryStateBackend-
运行时的状态数据保存在
TaskManager JVM堆上内存 (保证TaskManager的堆上内存可用) -
执行
Checkpoint时,将快照数据保存到JobManager进程的内存中 (需要保证JobManager的内存可用) -
在执行
Savepoint时,将快照存储到文件系统。
使用环境:在本地开发调试测试,生产环境基本不用。
-
-
FSStateBackend-
运行时将状态数据保存到
TaskManager的内存中; -
Checkpoint时,将状态快照保存到配置的文件系统中; -
TaskManager异步将状态数据写入外部存储
使用环境:用于处理小状态、短窗口、或者小键值状态的有状态处理任务
-
-
RocksDBStateBackend- 使用本地数据库
RocksDB将流计算数据状态存储在本地磁盘中 Checkpoint时,将整个RocksDB中保存的State数据全量或者增量持久化到配置的文件系统中
使用环境:处理大状态、长窗口,或大键值状态的有状态处理任务;唯一支持增量检查点的后端;大状态的任务都建议直接使用
RocksDB状态后端 - 使用本地数据库
状态的过期机制
Flink的过期机制支持onCreateAndWrite和onReadAndWrite 两种,默认为 onCreateAndWrite
onCreateAndWrite在创建和写入时更新TTLonReadAndWrite在访问和写入时更新TTL
状态的区别
| keyed state | operator state |
|---|---|
仅keyedStream的算子 | 所有算子 |
ValueState:简单的存储一个变量,不要保存集合之类的,这样序列化和反序列化成本很高。TTL针对整个 ValueListStateMapState:和HashMap的使用方式一样,TTL只针对一个keyReducingStateAggregatingState | ListState:均匀划分到算子的每个 sub-task 上,每个状态的数据不相同BroadcastState:每个 sub-task 的广播状态都一样,每个状态的数据相同UnionListState:合并后的数据每个算子都有一份全量状态数据,每个状态的数据相同 |
RichFunction 从 context 获取 | 重写Checkpointed Function或ListCheckpointed |
以单key粒度访问、变更状态 | 以单算子并发粒度访问,变更状态 |
状态随keyGroup在算子上进行重分配。当任务并行度变化时,会将 key-group 重新划分到算子不同的 sub-task 上,任务启动后,任务数据在做 keyby 进行数据 shuffle 时,依然能够按照当前数据的 key 发到下游能够处理这个 key 的 key-group 中进行处理 | 均匀分配,合并后到每个得到全部 |
状态的TTL
- 更新TTL的时机;
- 访问到已过期数据的数据可见性;
- 只支持处理时间语义;
- lazy处理,后台线程
StateTtlConfig.Builder builder = StateTtlConfig
// ttl 时长
.newBuilder(Time.milliseconds(1))
// 更新类型
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
// 创建和写入更新
.updateTtlOnCreateAndWrite()
// 读取和写入更新
.updateTtlOnReadAndWrite()
// 过期状态的访问可见性
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
// 如果还没有被删除就返回
.returnExpiredIfNotCleanedUp()
// 过期的永远不返回
.neverReturnExpired().cleanupFullSnapshot()
// 过期的时间语义
.setTtlTimeCharacteristic(StateTtlConfig.TtlTimeCharacteristic.ProcessingTime)
.useProcessingTime()
// 清除策略
// 从 cp 或 sp 恢复时清除过期状态
.cleanupFullSnapshot()
// 增量删除,只有有状态记录访问时,才会做删除,并且他会加大任务处理时延
// 增量删除仅仅支持 HeapStateBeckend, 不支持 Rocksdb
// 每访问1次State,遍历相应次数删除
.cleanupIncrementally(1000)
// Rocksdb状态后端在rocksdb做compaction时清除过期状态
//做compaction时每隔3个entry,重新更新时间戳,(用于判断是否过期)
.cleanupInRocksdbCompactFilter(3)
// 禁用 cleanup
.disableCleanupInBackground()
.build();
状态过期数据处理
- 如果状态
State TTL没有设置时, 直接将数据存储在State - 如果状态
State TTL设置时,会以<value, ts>保存,ts是时间戳
任务设置了 State TTL 和不设置 State TTL 的状态是不兼容的,防止出现任务从 Checkpoint 恢复不了的情况。但是你可以去修改 TTL 时长,因为修改时长并不会改变 State 存储结构。
-
懒删除策略
访问
State的时候根据时间戳判断是否过期,如果过期则主动删除State数据。这个删除策略是不需要用户进行配置的,只要你打开了
State TTL功能,就会默认执行。 -
全量快照清除策略
从状态恢复(
checkpoint、savepoint)的时候采取做过期删除,但是不支持rocksdb增量ck -
增量快照清除策略
访问
state的时候,主动去遍历一些state数据判断是否过期,如果过期则主动删除State数据- 如果没有
state访问,也没有处理数据,则不会清理过期数据。 - 增量清理会增加数据处理的耗时。
- 现在仅
Heap state backend支持增量清除机制。在RocksDB state backend上启用该特性无效。 - 因为是遍历删除
State机制,并且每次遍历的条目数是固定的,所以可能会出现部分过期的State很长时间都过期不掉导致Flink任务OOM。
- 如果没有
-
rocksdb合并清除策略rockdb做compaction的时候遍历进行删除。仅仅支持rocksdbrocksdb compaction时调用TTL过滤器会降低compaction速度。因为TTL过滤器需要解析上次访问的时间戳,并对每个将参与压缩的状态进行是否过期检查。对于集合型状态类型(比如ListState和MapState),会对集合中每个元素进行检查。
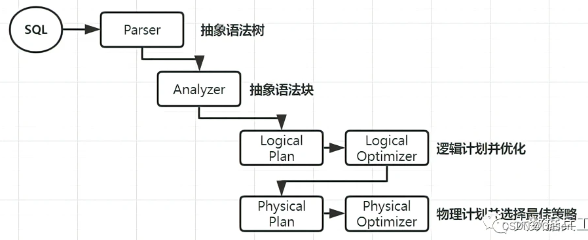
Flink/Spark/Hive SQL的执行原理
Hive SQL
Hive SQL是Hive提供的SQL查询引擎,底层是MR实现的,Hive根据输入的SQL语句执行词法分析、语法树构建、编译、逻辑计划、优化逻辑计划、物理计划,转化为MR Task最终交由MR引擎执行。
- 执行引擎。具有
mapreduce的一切特性,适合大批量数据离线处理,相较于Spark而言,速度较慢且IO操作频繁 - 有完整的
hql语法,支持基本sql语法、函数和udf - 对表数据存储格式有要求,不同存储、压缩格式性能不同
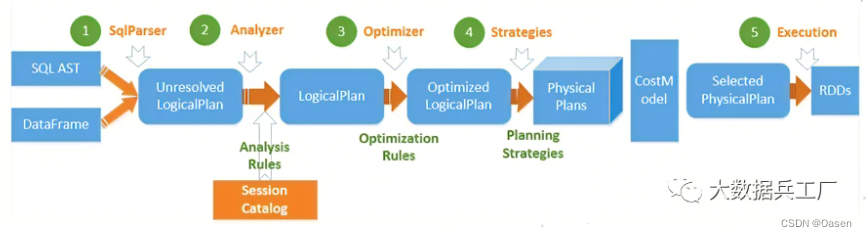
Spark SQL
Spark SQL底层基于Spark引擎,使用Antlr解析语法,编译生成逻辑计划和物理计划。
- 输入编写的
Spark SQL SqlParser分析器。进行语法检查、词义分析,生成未绑定的Logical Plan逻辑计划(未绑定查询数据的元数据信息,比如查询什么文件,查询那些列等)Analyzer解析器。查询元数据信息并绑定,生成完整的逻辑计划。此时可以知道具体的数据位置和对象,Logical Plan形如from table -> filter column -> select形式的树结构Optimizer优化器。选择最好的一个Logical Plan,并优化其中的不合理的地方。常见的例如谓词下推、剪枝、合并等优化操作Planner使用Planing Strategies将逻辑计划转化为物理计划,并根据最佳策略选择出的物理计划作为最终的执行计划- 调用
Spark PlanExecution执行引擎执行Spark RDD任务
Flink SQL
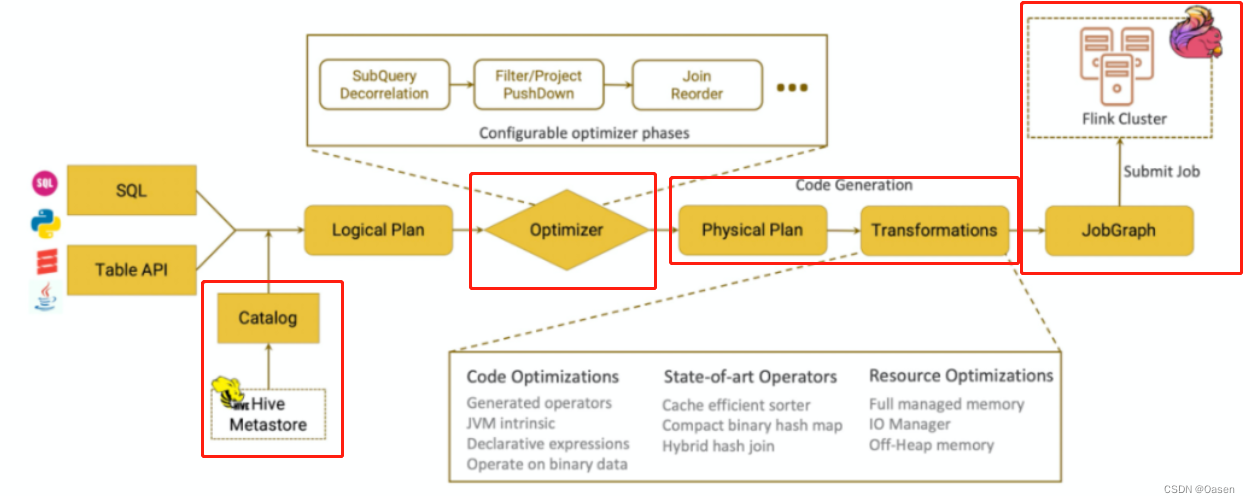
Parser:SQL解析。底层通过JavaCC解析SQL语法,并将SQL解析为未经校验的AST语法树。Validate:SQL校验。这里会校验SQL的合法性,比如Schema、字段、数据类型等是否合法(SQL匹配程度),过程需要与sql存储的元数据结合查验。Optimize:SQL优化。Flink内部使用多种优化器,将前面步骤的语法树进一步优化,针对RelNode和生成的逻辑计划,随后生成物理执行计划。Produce:SQL生成。将物理执行计划生成在特定平台的可执行程序。Execute:SQL执行。执行SQL得到结果。
总结
均存在解析、校验、编译生成语法树、优化生成逻辑计划等步骤,都是将物理执行计划使用相应的引擎做计算
反压(背压)
表现
- 运行时是正常的,但是会出现大量
Task任务等待; - 少数
Task任务开始报checkpoint超时问题; - 大量
Kafka数据堆积,导致消费不及时; WEB UI的BackPressure页面会显示High标识
原因
- 算子性能问题:
当前Task任务处理速度慢,比如task任务中调用算法处理等复杂逻辑,导致上游申请不到足够内存。 - 数据倾斜问题:
下游Task任务处理速度慢,比如多次collect()输出到下游,导致当前节点无法申请足够的内存。
影响
频繁反压会导致流处理作业数据延迟增加,同时还会影响到Checkpoint。
Checkpoint时需要进行Barrier对齐,此时若某个Task出现反压,Barrier流动速度会下降,导致Checkpoint变慢甚至超时,任务整体也变慢。
机制

反压时一般下游速度慢于上游速度,数据久积成疾,需要做限流。Task任务需要保持上下游动态反馈,如果下游速度慢,则上游限速;否则上游提速。实现动态自动反压的效果。
- 每个
TaskManager都有一个Network buffer pool,该内存在堆外内存申请的; - 同时每个
Task创建自身的Local BufferPool(本地内存),并于Network BufferPool交换内存; - 上游
Record Writer向Local BufferPool申请内存写数据,如果该内存不足,则向共享内存Network BufferPool申请内存写数据,如果使用完毕,则会释放。 - 本次
Task任务会将内存中的发送到网络,然后下游端按照类似的机制进行处理; - 当下游申请
buffer失败,表示当前节点内存不足(反压了),则发送反压信号给上游,上游减慢数据的处理发送,直到下游恢复。
总结:下游由于各种原因导致当前任务申请内存不足,使得上游数据缓慢发送过来。这个过程就是反压上传。
处理
缓解处理
OK: 0 <= Ratio <= 0.10,表示状态良好正;
LOW: 0.10 < Ratio <= 0.5,表示有待观察;
HIGH: 0.5 < Ratio <= 1,表示要处理了(增加并行度/subTask/检查是否有数据倾斜/增加内存)
- 事前:解决上述介绍到的
数据倾斜、算子性能问题。 - 事中:在出现反压时:
- 限制数据源的消费数据速度。比如在事件时间窗口的应用中,可以自己设置在数据源处加一些限流措施,让每个数据源都能够匀速消费数据,避免出现有的
Source快,有的Source慢,导致窗口input pool打满,watermark对不齐导致任务卡住。 - 关闭 Checkpoint。关闭
Checkpoint可以将barrier对齐这一步省略掉,促使任务能够快速回溯数据。我们可以在数据回溯完成之后,再将Checkpoint打开。
- 限制数据源的消费数据速度。比如在事件时间窗口的应用中,可以自己设置在数据源处加一些限流措施,让每个数据源都能够匀速消费数据,避免出现有的
处理过程
- 查看
Flink UI界面,定位哪些Task出现反压问题 - 查看代码和数据,检查是否出现数据倾斜
- 如果发生数据倾斜,进行预聚合
key或拆分数据 - 加大执行内存,调整并发度和分区数
一致性的保持
-
输入端
保证数据可重复读,不丢失数据。
对数据进行持久化保存,并且可以重设数据的读取位置
Flink通过内部记录维护Kafka的offset, 可以实现精确一次的处理语义 -
转换端
基于一致性快照机制,实现一致性语义
通过定期自动执行一致性检查点。异步在数据中插入
barrier检查点分界线,整个流程所有操作均会进行barrier对齐->数据完成确认->checkpoints状态保存,从而保证数据被精确一次处理。 -
输出端
保证幂等性或事务性,可以使用二阶段事务提交机制来实现。
幂等写入就是多次写入会产生相同的结果,结果具有不可变性。在Flink中saveAsTextFile算子就是一种比较典型的幂等写入。其需要限制在于外部存储系统必须支持这样的幂等写入。事务用一个事务来进行数据向外部系统的写入,这个事务是与检查点绑定在一起的。当 Sink 任务遇到 barrier 时,开始保存状态的同时就开启一个事务,接下来所有数据的写入都在这个事务中;待到当前检查点保存完毕时,将事务提交,所有写入的数据就真正可用了(遇到barrier -> 开启事务 -> 完成检查点 -> 提交事务 )
二阶段提交则对于每个checkpoint创建事务,先预提交数据到sink中,然后等所有的checkpoint全部完成后再真正提交请求到sink, 并把状态改为已确认,从而保证数据仅被处理一次(先开启事务,等到数据到了sink端后,完成预提交,接着等到真正提交,提交完成后,当前事务也关闭了)。
总结:
- Source 引擎可以重新消费,比如 Kafka 可以重置 offset 进行重新消费
Flink任务配置 exactly-once,保证Flink任务 State 的 exactly-once- Sink 算子支持两阶段或者可重入,保证产出结果的 exactly-once
Sink两阶段:由于两阶段提交是随着Checkpoint进行的,假设Checkpoint是5min做一次,那么数据对下游消费方的可见性延迟至少也是5min,所以会有数据延迟等问题,目前用的比较少。Sink支持可重入:举例:Sink为MySQL:可以按照key update数据Sink为Druid:聚合类型可以选用longMaxSink为ClickHouse:查询时使用longMax或者使用ReplacingMergeTree表引擎将重复写入的数据去重,可能会担心ReplacingMergeTree会有性能问题,其实性能影响不会很大,因为failover导致的数据重复其实一般情况下是小概率事件,并且重复的数据量也不会很大,也只是一个Checkpoint周期内的数据重复,所以使用ReplacingMergeTree是可以接受的)Sink为Redis:按照key更新数据
Flink怎么保证exactly-once
端到端的exactly-once对sink要求比较高,具体实现主要有幂等写入和事务性写入两种方式。
-
幂等写入的场景依赖于业务逻辑。
-
事务性写入又有预写日志(
WAL)和两阶段提交(2PC)两种方式。
如果外部系统不支持事务,那么可以用预写日志的方式,把结果数据先当成状态保存,然后在收到 checkpoint 完成的通知时,一次性写入 sink 系统。
二阶段提交
开始事务:创建一个临时文件夹,来写把数据写入到这个文件夹里面
预提交:将内存中缓存的数据写入文件并关闭
正式提交:将之前写完的临时文件放入目标目录下。这代表着最终的数据会有一些延迟
丢弃:丢弃临时文件
若失败发生在预提交成功后,正式提交前。可以根据状态来提交预提交的数据,也可删除预提交的数据。
延迟数据的处理
Flink中watermark 和window机制解决了流式数据的乱序问题,对于因为延迟而顺序有误的数据,可以根据事件时间进行业务处理,对于延迟的数据Flink也有自己的解决办法,主要的办法是给定一个允许延迟的时间,在该时间范围内仍可以接受处理延迟数据:
Flink内置watermark机制,可在一定程度上允许数据延迟- 程序可在
watermark的基础上再配置最大延迟时间 - 开启侧输出流,将延迟的数据输出到侧输出流
- 程序内部控制,延迟过高的数据单独进行后续处理
具体操作:
- 设置允许延迟的时间是通过
allowedLateness(lateness: Time)设置; - 保存延迟数据则是通过
sideOutputLateData(outputTag: OutputTag[T])保存; - 获取延迟数据是通过
DataStream.getSideOutput(tag: OutputTag[X])获取。
双流join
实现原理:底层原理依赖Flink的State状态存储,通过将数据存储到State中进行关联join, 最终输出结果。
-
基于原生
State的connect算子对两个
DataStream执行connect操作,将其转化为ConnectedStreams, 生成的Streams可以调用不同方法在两个实时流上执行,且双流之间可以共享状态。两个数据流被
connect之后,只是被放在了同一个流中,内部依然保持各自的数据和形式,两个流相互独立。orderStream.connect(orderDetailStream) -
窗口
join将两条实时流中元素分配到同一个时间窗口中完成
Join。两条实时流数据缓存在Window State中,当窗口触发计算时执行join操作。orderDetailStream .coGroup(orderStream) .where(r -> r.getOrderId()) .equalTo(r -> r.getOrderId()) .window(TumblingProcessingTimeWindows.of(Time.seconds(60))) orderStream.join(orderDetailStream) .where(r => r._1) //订单id .equalTo(r => r._2) //订单id .window(TumblingProcessTimeWindows.of(Time.seconds(60))) -
间隔
join根据右流相对左流偏移的时间区间(
interval)作为关联窗口,在偏移区间窗口中完成join操作。根据一条流的某个数据,基于这个数据的时间点,在另一条流上选择这个时间段区间的所有数据关联orderStream.keyBy(_.1) // 调用intervalJoin关联 .intervalJoin(orderDetailStream._2) // 设定时间上限和下限 .between(Time.milliseconds(-30), Time.milliseconds(30)) .process(new ProcessWindowFunction())
双流可能问题
-
为什么我的双流
join时间到了却不触发,一直没有输出检查一下watermark的设置是否合理,数据时间是否远远大于watermark和窗口时间,导致窗口数据经常为空 -
state数据保存多久,会内存爆炸吗state自带有ttl机制,可以设置ttl过期策略,触发Flink清理过期state数据。建议程序中的state数据结构用完后手动clear掉。 -
我的双流
join倾斜怎么办join倾斜三板斧: 过滤异常key、拆分表减少数据、打散key分布。当然可以的话我建议加内存!加内存!加内存!! -
想实现多流
join怎么办目前无法一次实现,可以考虑先union然后再二次处理;或者先进行connnect操作再进行join操作 -
join过程延迟、没关联上的数据会丢失吗这个一般来说不会,join过程可以使用侧输出流存储延迟流;如果出现节点网络等异常,Flink checkpoint也可以保证数据不丢失。
数据倾斜
数据倾斜一般都是数据Key分配不均,比如某一类型key数量过多,导致shuffle过程分到某节点数据量过大,内存无法支撑。
排查
监控某任务Job执行情况,可以去Yarn UI或者Flink UI观察,一般会出现如下状况:
- 发现某
subTask执行时间过慢 - 传输数据量和其他
task相差过大 BackPressure页面出现反压问题(红色High标识)
结合以上的排查定位到具体的task中执行的算子,一般常见于Keyed类型算子:比如groupBy、rebance等产生shuffle过程的操作。
处理
- 数据拆分。如果能定位的数据倾斜的
key,总结其规律特征。比如发现包含某字符,则可以在代码中把该部分数据key拆分出来,单独处理后拼接。 key二次聚合。两次聚合,第一次将key加前缀聚合,分散单点压力;随后去除前缀后再次聚合,得到最终结果。- 调整参数。加大
TaskManager内存、keyby均衡等参数,一般效果不是很好。 - 自定义分区或聚合逻辑。继承分区划分、聚合计算接口,根据数据特征和自定义逻辑,调整数据分区并均匀打散数据
key。
总结: 在数据进入窗口前做预聚合、重新设计窗口聚合的key、使用再平衡算子rebalance等
算子
- 数据读取:
fromElements、readTextFile、socketTextStream、createInput - 处理数据:
map、flatMap、filter、keyBy、reduce、window、connect
Flink任务延时高,如何入手
主要的手段是资源调优和算子调优。
- 资源调优即是对作业中的
Operator的并发数parallelism、CPU、堆内存heap_memory等进行调优。 - 作业参数调优包括:并行度的设置,
State的设置,checkpoint的设置。
算子链
为了更高效地分布式执行,Flink 会尽可能地将 operator 的 subtask 链接chain在一起形成task。每个 task 在一个线程中执行。将operators 链接成 task 是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。这就是我们所说的算子链。
Flink CEP编程中当状态没有到达的时候会将数据保存在哪里
在流式处理中,CEP 当然是要支持EventTime的,那么相对应的也要支持数据的迟到现象,也就是watermark的处理逻辑。CEP对未匹配成功的事件序列的处理,和迟到数据是类似的。在Flink CEP的处理逻辑中,状态没有满足的和迟到的数据,都会存储在一个**Map数据结构**中,也就是说,如果我们限定判断事件序列的时长为5分钟,那么内存中就会存储5分钟的数据。
aggregate 和 process 计算区别
- aggregate:是增量聚合,来一条数据计算完了存储在累加器中,不需要等到窗口触发时计算,性能较好;
- process:全量函数,缓存全部窗口内的数据,满足窗口触发条件再触发计算,同时还提供定时触发,窗口信息等上下文信息;
- 应用场景:
aggregate一个一个处理的聚合结果向后传递一般来说都是有信息损失的,而process则可以更加定制化的处理。
序列化
摒弃了Java原生的序列化方法,以独特的方式处理数据类型和序列化,包含自己的类型描述符,泛型类型提取和类型序列化框架。
TypeInformation 是所有类型描述符的基类。它揭示了该类型的一些基本属性,并且可以生成序列化器。
为什么 Flink 要用到 Java 序列化机制。和 Flink 类型系统的数据序列化机制的用途有啥区别
Flink 写的函数式编程代码或者说闭包,需要 Java 序列化从JobManager 分发到 TaskManager,而 Flink 类型系统的数据序列化机制是为了分发数据,不是分发代码,可以用非Java的序列化机制,比如Kyro。
非实例化的变量没有实现 Serializable 为啥就不报错,实例化就报错
编译期不做序列化,所以不实现 Serializable 不会报错,但是运行期会执行序列化动作,没实现 Serializable 接口的就报错了
为啥加transient 就不报错
Flink DataStream API 的 Function 作为闭包在网络传输,必须采用 Java 序列化,所以要通过 Serializable 接口标记,根据 Java 序列化的规定,内部成员变量要么都可序列化,要么通过 transient 关键字跳过序列化,否则Java 序列化的时候会报错。静态变量不参与序列化,所以不用加 transient。
任务的并行度的评估
Flink 任务并行度合理行一般根据峰值流量进行压测评估,并且根据集群负载情况留一定量的 buffer 资源。
- 如果数据源已经存在,则可以直接消费进行测试
- 如果数据源不存在,需要自行造压测数据进行测试
对于一个Flink任务来说,一般可以按照以下方式进行细粒度设置并行度:
- source 并行度配置:以
kafka为例,source的并行度一般设置为kafka对应的topic的分区数 - transform(比如
flatmap、map、filter等算子)并行度的配置:这些算子一般不会做太重的操作,并行度可以和source保持一致,使得算子之间可以做到forward传输数据,不经过网络传输 - ***
keyby之后的处理算子***:建议最大并行度为此算子并行度的整数倍,这样可以使每个算子上的keyGroup是相同的,从而使得数据相对均匀shuffle到下游算子,如下图为shuffle策略 - sink 并行度的配置:
sink是数据流向下游的地方,可以根据sink的数据量及下游的服务抗压能力进行评估。如果sink是kafka,可以设为kafka对应topic的分区数。注意sink并行度最好和kafka partition成倍数关系,否则可能会出现如到kafka partition数据不均匀的情况。但是大多数情况下sink算子并行度不需要特别设置,只需要和整个任务的并行度相同就行。
合理评估任务最大并行度
-
前提:并行度必须 <= 最大并行度
-
最大并行度的作用:合理设置最大并行度可以缓解数据倾斜的问题
-
根据具体场景的不同,最大并行度大小设置也有不同的方式:
-
在
key非常多的情况下,最大并行度适合设置比较大(几千),不容易出现数据倾斜,以Flink SQL场景举例:row_number = 1 partition key user_id的Deduplicate场景(user_id一般都非常多) -
在
key不是很多的情况下,最大并行度适合设置不是很大,不然会加重数据倾斜,以Flink SQL场景举例:group by dim1,dim2聚合并且维度值不多的group agg场景(dim1,dim2可以枚举),如果依然有数据倾斜的问题,需要自己先打散数据,缓解数据倾斜 -
最大并行度的使用限制:最大并行度一旦设置,是不能随意变更的,否则会导致检查点或保存点失效;最大并行度设置会影响
MapState状态划分的KeyGroup数,并行度修改后再从保存点启动时,KeyGroup会根据并行度的设定进行重新分布。 -
最大并行度的设置:最大并行度可以自己设置,也可以框架默认生成;默认的算法是取当前算子并行度的 1.5 倍和 2 的 7 次方比较,取两者之间的最大值,然后用上面的结果和 2 的 15 次方比较,取其中的最小值为默认的最大并行度,非常不建议自动生成,建议用户自己设置。
保障实时指标的质量
-
事前:
- 任务层面:根据峰值流量进行压力测试,并且留一定
buffer,用于事前保障任务在资源层面没有瓶颈 - 指标层面:根据业务要求,上线实时指标前进行相同口径的实时、离线指标的验数,在实时指标的误差不超过业务阈值时,才达到上线要求
- 任务层面:根据峰值流量进行压力测试,并且留一定
-
事中:
- 任务层面:贴源层监控
Kafka堆积延迟等报警检测手段,用于事中及时发现问题。比如的普罗米修斯监控 Lag 时长 - 指标层面:根据指标特点实时离线指标结果对比监控。检测到波动过大就报警。比如最简单的方式是可以通过将实时结果导入到离线,然后定时和离线指标对比
- 任务层面:贴源层监控
-
事后:
- 任务层面:对于可能发生的故障类型,构建用于故障修复、数据回溯的实时任务备用链路
- 指标层面:构建指标修复预案,根据不同的故障类型,判断是否可以使用实时任务进行修复。如果实时无法修复,构建离线恢复链路,以便使用离线数据进行覆写修复
CDC
监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
保存点
-
保存点的原理和算法与检查点完全相同,只是多了一些额外的元数据。
-
必须由用户明确地手动触发保存操作,所以就是“手动存盘”。
-
保存点能够在程序更改的时候依然兼容,前提是状态的拓扑结构和数据类型不变
-
保存点中状态都是以算子 ID-状态名称这样的 key-value 组织起来的,需要.uid()方法来进行指定
-
如果停止作业时,忘了触发保存点也不用担心,现在版本的 flink 支持从保留在外部系统的 checkpoint恢复作业,但是恢复时不支持切换状态后端。(需保留ck最后一次)















 1103
1103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









