







文章目录
简介
SparkSQL是 Spark 计算框架的一个模块,与基础 Spark RDD API 不同,SparkSQL 为 Spark 提供了更多 数据结构schema 信息,在内部,SparkSQL 使用这些额外的数据结构信息做进一步的优化操作,与 SparkSQL 交互的方式有多种,包括 SQL语句交互、DatasetAPI 交互。当使用 SparkSQL 获取数据处理结果时,无论使用什么样的交互方式,无论采用什么样的语言编写程序,其底层的执行引擎都是相同的。

SparkSQL 是以SparkRDD 为基础,以SQL方式做大数据分析。其只能针对结构化数据或半结构化数据做分析,无法对非结构化数据做分析。
数据处理
对数据的处理方式上大致可以划分为 SQL 和 命令式 两种
SQL
SQL 擅长数据分析和通过简单的语法表示查询。
- 优点
- Spark SQL 使用 Hive 解析 SQL 生成 AST 语法树, 将其后的逻辑计划生成, 优化, 物理计划都自己完成, 而不依赖 Hive。
- 执行计划和优化交给优化器 Catalyst。
- 内建了一套简单的 SQL 解析器, 可以不使用 HQL, 此外, 还引入和 DataFrame 这样的 DSL API, 完全可以不依赖任何 Hive 的组件。
- Spark SQL 可以直接降查询作用于 RDD。
命令式
命令式操作适合过程式处理和算法性的处理。
- 优点
- 操作粒度更细, 能够控制数据的每一个处理环节
- 操作更明确, 步骤更清晰, 容易维护
- 支持非结构化数据的操作
DataFrame & Dataset
DataFrame
DataFrame(Dataset<Row>)是一个由命名列组成的 Dataset(Row 类型的 Dataset)。概念上相当于关系型数据库中的一个表,但底层提供了丰富的优化操作。DataFrames 可以从一系列广泛的数据来源中构建,如结构化数据文件,Hive 中的表、外部数据库、或者已有的 RDD。
DataFrame:DataFrame 每一行的类型固定为 Row,只有通过解析才能获取各个字段的值;是分布式的 Row 对象的集合。
- DataFrame 是从 Spark1.3 开始引入了一个名为 DataFrame 的表格式数据抽象;
- DataFrame 是用于处理结构化和半结构化数据的数据抽象;
- DataFrame 利用其 Schema 以比原始 RDDs 更有效的方式存储数据;
- DataFrame 利用 RDD 的不可变性、内存计算、弹性的、分布式的和并行的特性,变成数据应用一个成为 schema 的数据结构,允许 spark 管理 schema, 以比 java序列化更有效的方法在集群节点之间进行数据的传递。
- 与 RDD 不同,DataFrame 中的数据被组织到指定的 columns 中,就像噶UN系数据库中的表一样。
- DataFrame 是一个类似于关系型数据库表的函数式组
- DataFrame 一般处理结构化数据和半结构化数据
- DataFrame 具有数据对象的 Schema 信息
- 可以使用命令式的 API 操作 DataFrame, 同时也可以使用 SQL 操作 DataFrame
- DataFrame 可以由一个已经存在的集合直接创建, 也可以读取外部的数据源来创建
Dataset
Dataset 是一个分布式的数据集合。在Spark1.6版本中,Dataset 作为一个新街口添加进来,兼具有 RDD 的优点(强类型、使用强大的Lambda 函数的功能)和 SparkSQl 优化引擎的优势。Dataset 可以从 JVM 对象来构建,然后使用一系列转换函数进行计算。
Dataset: 具有强类型的特定。Dataset 中,每一行是什么类型是不一定的,在自定义了case class之后可以很自由的获得每一行的信息。
- 面向对象的编程风格;
- 像 RDD API 一样的编译时类型安全;
- 利用 schema 处理结构化数据的优势;
- Dataset 是结构化数据集,数据集泛型可以是 Row (DataFrame),也可以是特定的数据类型;
- Java 和 Spark 在编译时将知道数据集中数据的类型。
- Dataset 是一个新的 Spark 组件, 其底层还是 RDD
- Dataset 提供了访问对象中某个特定字段的能力, 不用像 RDD 一样每次都要针对整个对象做操作
- Dataset 和 RDD 不同, 如果想把 Dataset[T] 转为 RDD[T], 则需要对 Dataset 底层的 InternalRow 做转换, 是一个比价重量级的操作
DataFrame和DataSet可以相互转化,df.as[ElementType]这样可以把DataFrame转化为DataSet,ds.toDF()这样可以把DataSet转化为DataFrame。
一般来说,结构化数据具有固定的 Schema。
schema
schema 定义了 DataFrame 的列名和类型。可以手动定义 schemas 模式或从数据源读取 schemas 模式。 Schema包含列类型,用于申明什么列存储了什么类型的数据。
Row
Row 对象表示一个 【行】其操作类似于 Scala 中的 Map 数据类型。
// 一个对象就是一个对象
val p = People(name = "zhangsan", age = 10)
// 同样一个对象, 还可以通过一个 Row 对象来表示
val row = Row("zhangsan", 10)
// 获取 Row 中的内容
println(row.get(1))
println(row(1))
// 获取时可以指定类型
println(row.getAs[Int](1))
// 同时 Row 也是一个样例类, 可以进行 match
row match {
case Row(name, age) => println(name, age)
}
列的数据类型

SparkSession
SparkSession 提供了与底层 Spark功能交互的入口,允许使用 DataFrame 和 Dataset API 对 Spark 进行编程。最重要的是:它限制了概念的数量(SparkContext,SQLContext,HiveContext),并构建了开发人员与 Spark 交互时必须兼顾的结构。
注册为表或视图
既然 SparkSQL 可以使用 SQL 来进行操作,那么就需要一张表来被进行查询等操作,但是 SparkSQL 不存在表的概念。但是 DataFrame 可以被近似的看成一张表。可以通过一个简单的方法调用将任何 DataFrame 转换为一个表或视图:
myData.createOrReplaceTempView("myData”);
现在可以通过使用 SQL来查询我们的数据了。使用 spark.sql 函数,这里是返回一个新的 DataFrame。
SparkSQL 实现流程
为了解决过多依赖 Hive 的问题, SparkSQL 使用了一个新的 SQL 优化器替代 Hive 中的优化器, 这个优化器就是 Catalyst, SparkSQL 的架构大致如下。


- 先对 SQL 或者 Dataset 的代码解析, 生成逻辑计划;
- 再对逻辑计划进行优化, 再生成物理计划
- 最后生成代码到集群中以 RDD 的形式运行
SparkSQL 常见操作
case class People(name: String, age: Int)
val spark: SparkSession = new sql.SparkSession.Builder() ①
.appName("hello")
.master("local[6]")
.getOrCreate()
import spark.implicits._
val peopleRDD: RDD[People] = spark.sparkContext.parallelize(Seq(People("zhangsan", 9), People("lisi", 15)))
val peopleDS: Dataset[People] = peopleRDD.toDS() ②
val teenagers: Dataset[String] = peopleDS.where('age > 10) ③
.where('age < 20)
.select('name)
.as[String]
① SparkSQL 中有一个新的入口点, 叫做 SparkSession
② SparkSQL 中有一个新的类型叫做 Dataset
③ SparkSQL 有能力直接通过字段名访问数据集, 说明 SparkSQL 的 API 中是携带 Schema 信息的
命令式
val spark: SparkSession = new sql.SparkSession.Builder()
.appName("hello")
.master("local[6]")
.getOrCreate()
val df = spark.read
.option("header", true)
.csv("dataset/BeijingPM20100101_20151231.csv")
df.printSchema()
df.select('year, 'month, 'PM_Dongsi)
.where('PM_Dongsi =!= "Na")
.groupBy('year, 'month)
.count()
.show()
SQL
使用 SQL 来操作某个 DataFrame 的话, SQL 中必须要有一个 from 子句, 所以需要先将 DataFrame 注册为一张临时表。
val spark: SparkSession = new sql.SparkSession.Builder()
.appName("hello")
.master("local[6]")
.getOrCreate()
val df = spark.read
.option("header", true)
.csv("dataset/BeijingPM20100101_20151231.csv")
df.createOrReplaceTempView("temp_table")
spark.sql("select year, month, count(*) from temp_table where PM_Dongsi != 'NA' group by year, month")
.show()
数据的读写
DataFrameReader
SparkSQL 的一个非常重要的目标就是完善数据读取, 所以 SparkSQL 中增加了一个新的框架, 专门用于读取外部数据源, 叫做 DataFrameReader。
val reader: DataFrameReader = spark.read
| 组件 | 解释 |
|---|---|
| schema | 结构信息, 因为 Dataset 是有结构的, 所以在读取数据的时候, 就需要有 Schema 信息, 有可能是从外部数据源获取的, 也有可能是指定的 |
| option | 连接外部数据源的参数, 例如 JDBC 的 URL, 或者读取 CSV 文件是否引入 Header 等 |
| format | 外部数据源的格式, 例如 csv, jdbc, json 等 |
DataFrameReader 有两种访问方式, 一种是使用 load 方法加载, 使用 format 指定加载格式, 还有一种是使用封装方法, 类似 csv, json, jdbc 等。
// 使用 load 方法
val fromLoad: DataFrame = spark
.read
.format("csv")
.option("header", true)
.option("inferSchema", true)
.load("dataset/BeijingPM20100101_20151231.csv")
// Using format-specific load operator
val fromCSV: DataFrame = spark
.read
.option("header", true)
.option("inferSchema", true)
.csv("dataset/BeijingPM20100101_20151231.csv")
DataFrameWriter
数据保存和数据读取一样重要, 所以 SparkSQL 中增加了一个新的数据写入框架, 叫做 DataFrameWriter。
val writer: DataFrameWriter[Row] = df.write
| 组件 | 解释 |
|---|---|
| source | 写入目标, 文件格式等, 通过 format 方法设定 |
| mode | 写入模式, 例如一张表已经存在, 如果通过 DataFrameWriter 向这张表中写入数据, 是覆盖表呢, 还是向表中追加呢? 通过 mode 方法设定 |
| extraOptions | 外部参数, 例如 JDBC 的 URL, 通过 options, option 设定 |
| partitioningColumns | 类似 Hive 的分区, 保存表的时候使用, 这个地方的分区不是 RDD 的分区, 而是文件的分区, 或者表的分区, 通过 partitionBy 设定 |
| bucketColumnNames | 类似 Hive 的分桶, 保存表的时候使用, 通过 bucketBy 设定 |
| sortColumnNames | 用于排序的列, 通过 sortBy 设定 |
mode 指定了写入模式, 例如覆盖原数据集, 或者向原数据集合中尾部添加等
| Scala 对象表示 | 字符串表示 | 解释 |
|---|---|---|
| SaveMode.ErrorIfExists | “error” | 将 DataFrame 保存到 source 时, 如果目标已经存在, 则报错 |
| SaveMode.Append | “append” | 将 DataFrame 保存到 source 时, 如果目标已经存在, 则添加到文件或者 Table 中 |
| SaveMode.Overwrite | “overwrite” | 将 DataFrame 保存到 source 时, 如果目标已经存在, 则使用 DataFrame 中的数据完全覆盖目标 |
| SaveMode.Ignore | “ignore” | 将 DataFrame 保存到 source 时, 如果目标已经存在, 则不会保存 DataFrame 数据, 并且也不修改目标数据集, 类似于 CREATE TABLE IF NOT EXISTS |
DataFrameWriter 还有一种是使用封装方法 如 csv, json, saveAsTable 等
// 使用 save 保存, 使用 format 设置文件格式
df.write.format("json").save("dataset/beijingPM")
// 使用 json 保存, 因为方法是 json, 所以隐含的 format 是 json
df.write.json("dataset/beijingPM1")
Parquet 格式文件
Parquet 是列式储式的格式,被许多数据处理系统所支持。Spark SQL 提供了支持 Parquet 文件读写操作的方法,它自动保存原始数据的模式。当写 Parquet 文件时,出于兼容性原因,所有列都自动转换为可空。
Dataset<Row> parquetFileDF = spark.read().parquet("people.parquet");
cubesDF.write().parquet("data/test_table/key=2");
分区
表分区是一个常用的优化方式,比如像 Hive。在分区表中,数据通常被存储在不同的目录中,分区列值编码在每个分区目录的路径中。所有的文件资源可以通过发现和推断分区信息。例如,我们可以使用一下目录结构将以前使用的所有人口数据存储到一个分区表中,其中有两个额外的列,性别和国家作为分区列。
path
└── to
└── table
├── gender=male
│ ├── ...
│ │
│ ├── country=US
│ │ └── data.parquet
│ ├── country=CN
│ │ └── data.parquet
│ └── ...
└── gender=female
├── ...
│
├── country=US
│ └── data.parquet
├── country=CN
│ └── data.parquet
└── ...
通过使用 SparkSession.read.parquet 或 SparkSession.read.load 访问 path/to/table,Spark SQL 将自动的从路径中提取分区信息,如下所示, Dataset 的 Schema 变成了
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- gender: string (nullable = true)
|-- country: string (nullable = true)
观察被分区列的数据格式被自动的关联了,当前,数值类型,日期,时间戳和 String 类型被支持了。有时,我们可能不想自动的关联分区列的数据格式,对于这种要求 ,自动关联的配置上是由 spark.sql.sources.partitionColumnTypeInference.enabled 来进行处理的,默认为 true,当类型关联被 false,分区列将使用 String 类型。
从 Spark1.6 开始,分区发现金查找给定路径下的分区。对于如上案例,如果我们使用 SparkSession.read.parquetorSparkSession.read.load来访问 path/to/table/gender=male,gender`将不会被作为分区列。如果我们需要指定分区发现应该开始的基本路径,它们可以在数据源选项中设置 basePath。例如,当 path/to/table/gender=male 是数据的路径,我们设置 basePath 为 path/to/table/,那么 gender 将被作为一个分区列。
val partDF = spark.read.load("dataset/beijing_pm/year=2010/month=1")
配置可以采用 SparkSession 的 setConf 方法,或者是运行 SQL 时使用 SET KEY=VALUE 来处理。
| 配置 | 默认 | Meaning |
|---|---|---|
| spark.sql.parquet.binaryAsString | false | 其他一些生成Parquet的系统,特别是Impala、Hive和较早版本的Spark SQL,在编写Parquet模式时并不区分二进制数据和字符串。此标志告诉Spark SQL将二进制数据解释为字符串,以提供与这些系统的兼容性。 |
| spark.sql.parquet.int96AsTimestamp | true | 一些parquet生产系统,特别是Impala和Hive,将时间戳存储到INT96中。此标志告诉Spark SQL将INT96数据解释为时间戳,以提供与这些系统的兼容性。 |
| spark.sql.parquet.compression.codec | snappy | 设置写入parquet文件时使用的压缩编解码器。如果在表特定的选项/属性中指定了’ compression ‘或’ parquet.compression ‘,则优先级为’ compression ‘、’ parquet.compression ‘、’ spark.sql.parquet.compression.codec '。可接受的值包括:无,未压缩,snappy, gzip, lzo, brotli, lz4, zstd。注意‘zstd’需要在Hadoop 2.9.0之前安装‘ZStandardCodec’,‘brotli’需要安装‘BrotliCodec’。 |
| spark.sql.parquet.filterPushdown | true | 启用 parquet 过滤器下推优化设置为真。 |
| spark.sql.hive.convertMetastoreParquet | true | 当设置为false时,Spark SQL将使用Hive SerDe而不是内置的支持。 |
| spark.sql.parquet.mergeSchema | false | 如果为真,则 parquet数据源将从所有数据文件收集的模式合并在一起,否则将从摘要文件或随机数据文件中选择模式。 |
| spark.sql.parquet.writeLegacyFormat | false | 如果是,数据将以Spark 1.4或更早的方式写入。例如,十进制值将以Apache Parquet的固定长度字节数组格式编写,而其他系统(如Apache Hive和Apache Impala)使用这种格式。如果为假,则使用Parquet 的新格式。例如,小数将以基于int的格式编写。如果 Parquet 地板输出用于不支持这种新格式的系统,则将其设置为true。 |
总结
- Spark 不指定 format 的时候默认就是按照 Parquet 的格式解析文件
- Spark 在读取 Parquet 文件的时候会自动的发现 Parquet 的分区和分区字段
- Spark 在写入 Parquet 文件的时候如果设置了分区字段, 会自动的按照分区存储
JSON 格式文件
Spark SQL 可以自动的推断 JSON 数据集的 Schema,加载其作为一个 Dataset. 这种转换可以使用 SparkSession.read().json() 来完成,或者通过 Dataset 转换而来。
注意: 提供的 json 文件不是典型的 json 文件。其每行必须包含一个独立的,自包含的有效 json 对象。
Dataset<Row> people = spark.read().json("examples/src/main/resources/people.json");
val dfFromParquet = spark.read.load("dataset/beijing_pm")
// 将 DataFrame 保存为 JSON 格式的文件
dfFromParquet.repartition(1)
.write.format("json")
.save("dataset/beijing_pm_json")
Hive
Spark SQL 也支持从 Hive 中读取和写入数据。不管怎么样,由于Hive 有大量的依赖项,但是 Saprk 发行版本却不包括在这些依赖项中。如果 Hive 依赖想能在 classpath 中被发现,那么 Spark 可以自动的加载它们。注意,这些 Hive 依赖必须可以在 worker 节点上也存在。因为他们需要访问Hive序列化和反序列化库(SerDes)来访问存储在Hive中的数据。
可以将 hive-site.xml, core-site.xml, hdfs-site.xml 三个文件放在 conf 目录,这样就配置好了对 Hive 的支持。
当与 Hive 一起工作时,必须通过 SparkSession 来实例化对 Hive 的支持,包括连接 Hive metastore,支持 Hive 序列化库,和 Hive 用户自定义函数。没有现有Hive部署的用户仍然可以启用Hive支持。当没有配置好 hive-site.xml,context 将自动的在当前目录下创建 metastore_db,同时通过 spark.sql.warehouse.dir 来创建一个目录,在启动Spark应用程序的当前目录中,默认的Spark -warehouse目录是哪个。注意:在 hive-site.xml 中的 hive.metastore.warehouse.dir 的属性在 Spark 2.0 之后被废弃了,而使用了 spark.sql.warehouse.dir 来指定默认存储路径。我们可能需要确保向启动 Spark 应用程序的用户写入权限。
SparkSession spark = SparkSession
.builder()
.appName("Java Spark Hive Example")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate();
spark.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive");
spark.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src");
指定 Hive 的存储格式
当我们创建 Hive 表时,我们需要定义这个表应该如何从/到文件系统读取/写入数据。例如:输入格式和输出格式。我们也需要定义怎么对行数据反序列化操作。或者序列化行数据等。下面的参数选项能指定存储格式。例如: CREATE TABLE src(id int) USING hive OPTIONS(fileFormat ‘parquet’)。默认情况,我们将以纯文本的形式读取表文件。注意:在创建表时,还不支持 Hive 存储处理程序,我们可以在 Hive 端使用存储处理程序创建表,并使用 Spark SQL 读取它。
| 属性 | 含义 |
|---|---|
| fileFormat | 文件格式是一种存储格式规范包,包括“serde”、“输入格式”和“输出格式”。目前我们支持6种文件格式:“sequencefile”、“rcfile”、“orc”、“parquet”、“textfile”和“avro”。 |
| inputFormat, outputFormat | 这两个选项指定相应的’ InputFormat ‘和’ OutputFormat '类的名称为字符串文字,例如。“org.apache.hadoop.hive.ql.io.orc.OrcInputFormat”。这两个选项必须成对出现,如果您已经指定了“fileFormat”选项,则无法指定它们。 |
| serde | 此选项指定serde类的名称。当指定“fileFormat”选项时,如果给定的“fileFormat”已经包含serde的信息,则不要指定此选项。目前“sequencefile”、“textfile”和“rcfile”不包含serde信息,您可以在这3种文件格式中使用此选项。 |
| fieldDelim, escapeDelim, collectionDelim, mapkeyDelim, lineDelim | 这些选项只能用于“textfile”文件格式。它们定义如何将带分隔符的文件读入行。 |
JDBC
Spark SQL 也包括一个可以使用 JDBC 从其他数据库读取数据的数据源,这个功能应该比使用 JdbcRDD 更好。这是因为结果是以数据aframe的形式返回的,可以很容易地在Spark SQL中处理它们,或者与其他数据源连接。从Java或Python中使用JDBC数据源也更容易,因为它不需要用户提供ClassTag。注意,这与Spark SQL JDBC服务器不同,后者允许其他应用程序使用Spark SQL运行查询。
// Note: JDBC loading and saving can be achieved via either the load/save or jdbc methods
// Loading data from a JDBC source
Dataset<Row> jdbcDF = spark.read()
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.load();
Properties connectionProperties = new Properties();
connectionProperties.put("user", "username");
connectionProperties.put("password", "password");
Dataset<Row> jdbcDF2 = spark.read()
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties);
// Saving data to a JDBC source
jdbcDF.write()
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.save();
jdbcDF2.write()
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties);
// Specifying create table column data types on write
jdbcDF.write()
.option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)")
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties);
数据转换操作
有类型操作
无类型转换
Columns 操作
spark 中的列类型类似于带着你表格中的列,可以从 DataFrame 中选择列、操作列和删除列。对 Spark 来说,列是逻辑结构,它仅仅表示通过一个表达式按每条记录计算出一个值。这意味着,要得到一个 column 列的真实值,需要有一行 row 数据,为了得到一行数据,就需要一个DataFrame。不能在 DataFrame 的上下文之外操作单个列。必须在 DataFrame 内使用 Spark 转换来的操作列。
有许多不同的方法来构造和引用列,但是最简单的方式就是使用 col() 和 column() 函数。要使用这些函数,需要传入一个列名。
// in Scala
import org.apache.spark.sql.functions.{col, column}
col("someColumnName")
column("someColumnName")
如前所述,这个列可能存在于我们的DataFrames中,也可能不存在。在将列名和我们在catalog 中维护的列进行比较之前,列不会被解析,即列是 unresolved。
| 注意 |
|---|
| 我们刚才提到的两种不同的方法引用列。Scala有一些独特的语言特性, 允许使用更多的简写方式来引用列。以下的语法糖执行完全相同的事情, 即创建一个列, 但不提供性能改进: $“myColumn” , 'myColumn 。 “$” 允许我们将一个字符串指定为一个特殊的字符串,该字符串应该引用一个表达式。 标记 ( ’ ) 是一种特殊的东西,称为符号; 这是一个特定于scala语言的,指向某个标识符。它们都执行相同的操作,是按名称引用列的简写方式。当您阅读不同的人的Spark代码时,可能会看到前面提到的所有引用。 |
表达式 expression
表达式是在 DataFrame 中数据记录的一个或多个值上的一组转换。列是表达式,把它想象成一个函数,它将一个或多个列名作为输入,表达式会解析它们,为数据集中的每个记录返回一个单一值。
在最简单的情况下,expr(“someCol”) 等价于 col(“someCol”)。
列操作是表达式功能的一个子集。expr(“someCol - 5”) 与执 行col(“someCol”) - 5,或甚至 expr(“someCol”)- 5 的转换相同。这是因为 Spark 将它们编译为一个逻辑树,逻辑树指定了操作的顺序。
// Scala方式
df.select("DEST_COUNTRY_NAME").show(2)
-- SQL方式
SELECT DEST_COUNTRY_NAME FROM dfTable LIMIT 2
可以使用相同的查询样式选择多个列,只需在 select 方法调用中添加更多的列名字符串参数:
// in Scala
df.select("DEST_COUNTRY_NAME", "ORIGIN_COUNTRY_NAME").show(2)
-- in SQL
SELECT DEST_COUNTRY_NAME, ORIGIN_COUNTRY_NAME FROM dfTable LIMIT 2
可以用许多不同的方式引用列,可以交替使用它们
-- in Scala
import org.apache.spark.sql.functions.{expr, col, column}
df.select(
df.col("DEST_COUNTRY_NAME"),
col("DEST_COUNTRY_NAME"),
column("DEST_COUNTRY_NAME"),
'DEST_COUNTRY_NAME,
$"DEST_COUNTRY_NAME",
expr("DEST_COUNTRY_NAME"))
.show(2
但是有一个常见的错误,就是混合使用列对象和列字符串,例如:
df.select(col("DEST_COUNTRY_NAME"), "EST_COUNTRY_NAME")
expr 是我们可以使用的最灵活的引用,它可以引用一个简单的列或一个列字符串操作。例如:
// 更改列名,然后通过使用AS关键字来更改它
-- in Scala
df.select(expr("DEST_COUNTRY_NAME AS destination")).show(2)
-- in SQL
SELECT DEST_COUNTRY_NAME as destination FROM dfTable LIMIT 2
// 操作将列名更改为原来的名称
df.select(expr("DEST_COUNTRY_NAME as destination").alias("DEST_COUNTRY_NAME")) .show(2)
用户自定义函数 UDF
spark.udf.register("zipToLong", (z:String) => z.toLong)
spark.udf.register("largerThan", (z:String,number:Long) => z.toLong>number)
zipDS.select(col("city"),zipToLongUDF(col("zip")).as("zipToLong"),largerThanUDF(col("zip"),lit("99923")).as("largerThan")).orderBy(desc("zipToLong")).show();
Spark on hive
http://spark.apache.org/docs/latest/sql-programming-guide.html
开发环境配置
- 将 hive_home/conf 的 hive-site.xml 拷贝到 spark_home/conf 内;
- 将 hadoop_home/etc/hadoop 内的 hdfs-site.xml 和 core-site.xml 拷贝到spark_home/conf 内;
- 在拷贝到 spark_home/conf 所在节点上以 local 模式启动 spark-sql;
- 如果 hive 的 metastore 是 mysql 数据库,需要将 mysql 驱动放到 spark_home/jars 目录下面;
开发环境:在项目中创建文件夹 conf ,将上述三个文件放入 conf 目录; 如果 hive 的 metastore 是 mysql 数据库,需要将 mysql 驱动放到项目的类路径下。
# SparkSQL 执行过程
## SparkSQL执行过程
1. 编辑 Dataset API SQL代码;
2. 如果代码编译没有报错,Spark 会将代码转化为逻辑计划;
3. Spark 会将逻辑计划转化为物理计划,会对代码进行优化(catalyst 优化器) ;
4. Spark 执行物理计划 (RDD)。
## 逻辑计划(Logical plan)
逻辑计划不涉及 Executor 和 Driver,只是将用户写的代码转化为最优版本,通过将用户代码转化为 unresolved logic plan,然后再转化为 resolvd logic plan,catalog(所有表和DataFrame 信息的存储库),接着会把计划给 catalyst 优化器,catalyst 优化器是一组优化规则的集合:谓词下推、投影。
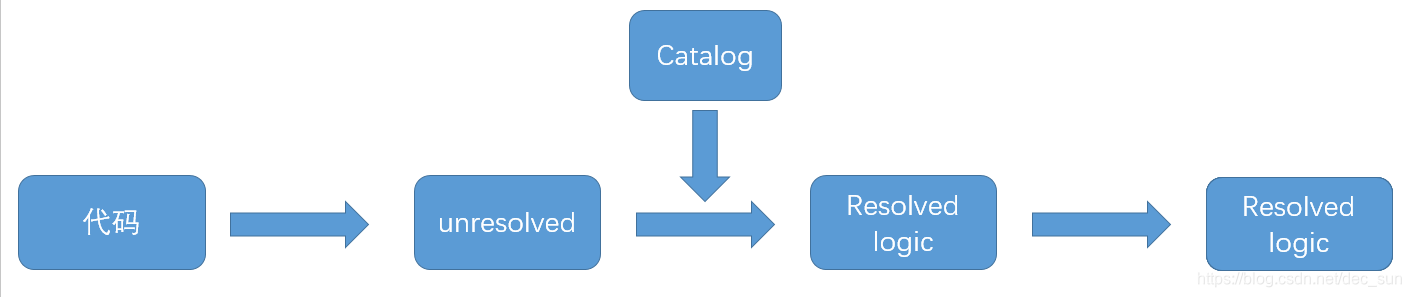
## 物理计划
最优逻辑计划通过生成不同的物理执行策略(A B C 计划),这些物理执行计划会通过 cost model 来比较,从而从中被选取一个最优的物理执行计划,其结果是一系列的 RDD 和 transformation。
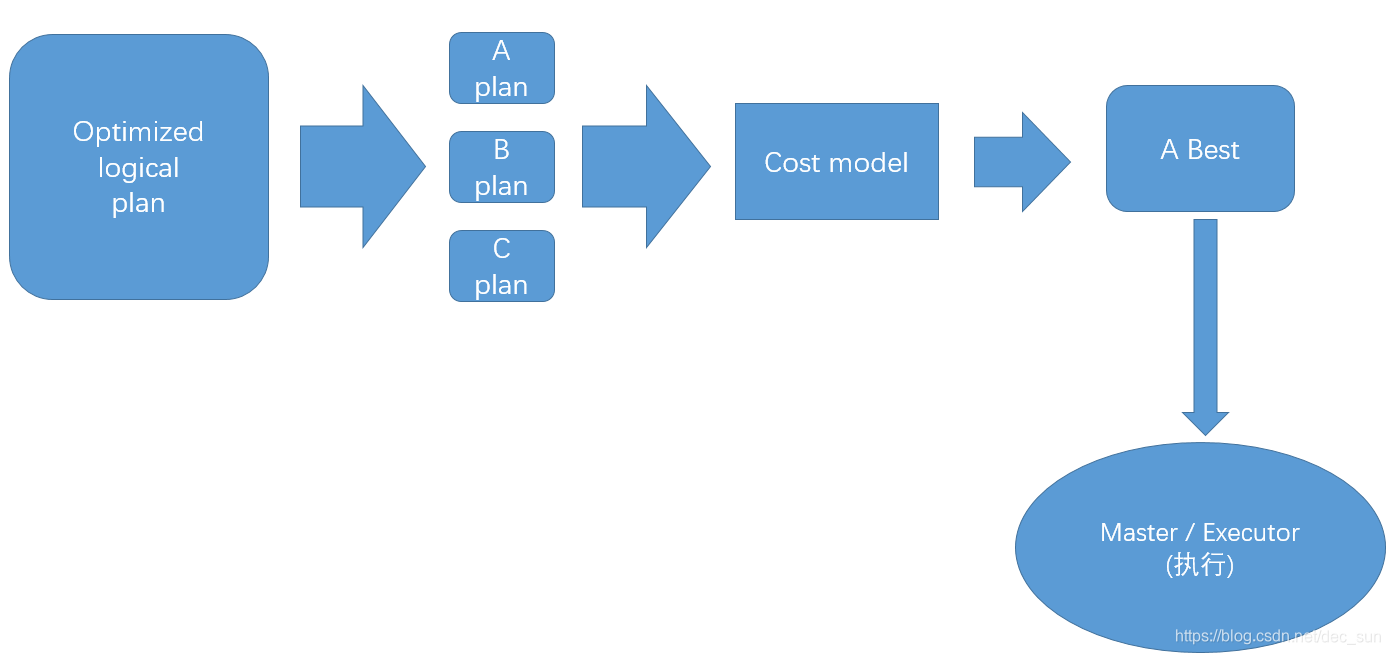
## 执行
选择一个物理执行计划,运行所有的 RDD 代码,使用 tungsten 进一步优化,生成本地 Java 字节码,执行生成的各种 stages,最后返回结果给用户。















 659
659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









