














文档指导地址:https://github.com/InternLM/tutorial/blob/main/lmdeploy/lmdeploy.md
3.1 KV cache量化这条命令出现这样的错误:
# 计算 minmax
lmdeploy lite calibrate \
--model /root/share/temp/model_repos/internlm-chat-7b/ \
--calib_dataset "c4" \
--calib_samples 128 \
--calib_seqlen 2048 \
--work_dir ./quant_output
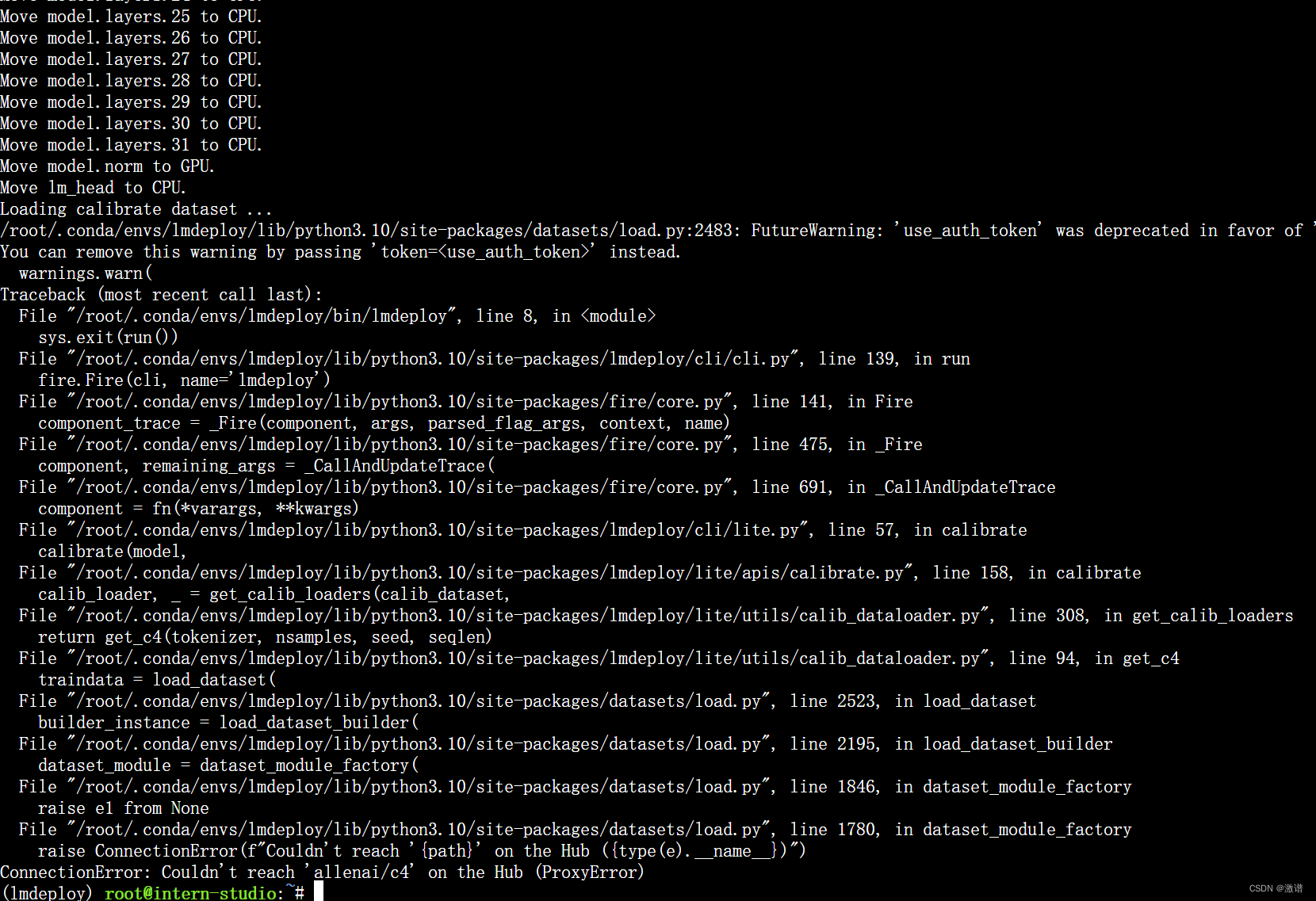
错误是因为从HF上下载数据集的问题,使用教程中这样操作即可:
这一步由于默认需要从 Huggingface 下载数据集,国内经常不成功。所以我们导出了需要的数据,大家需要对读取数据集的代码文件做一下替换。共包括两步:
- 第一步:复制
calib_dataloader.py到安装目录替换该文件:cp /root/share/temp/datasets/c4/calib_dataloader.py /root/.conda/envs/lmdeploy/lib/python3.10/site-packages/lmdeploy/lite/utils/- 第二步:将用到的数据集(c4)复制到下面的目录:
cp -r /root/share/temp/datasets/c4/ /root/.cache/huggingface/datasets/

KV cache量化后部署的模型,GPU占用没有改变呀,但是响应速度确实快了很多。















 546
546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









