







前言:为什么要用GPU编程
我们平时跑的大部分程序都是在CPU上的,CPU的每个核很强大,有很大的缓存,分支处理也比较快,功能全面,各种程序都可以运行,但带来的缺点就是一个CPU里面放不了太多核(最多几十个),并行计算能力不是特别高。
GPU和CPU不同。GPU的核很多,能做到几千个,所以并发计算能力很强。但是相比来说每个核的主频低,缓存少,单核比CPU的一个核差很多。而且GPU的架构是SIMT(Single instruction multiple thread),所以并不是每个核完全独立运行的。由于GPU的这些特点,它很适合做那种并行程度高的运算,比如矩阵运算。而机器学习领域,特别如人工神经网络这类模型,矩阵运算是最主要的运算,自然就会想到使用GPU来提高性能。
1. OpenCL简介
2008年6月,苹果首先提出了OpenCL(Open Computing Language)规范,旨在提供一个通用的开放API,在此基础上开发GPU通用计算软件。随后,Khronos Group宣布成立GPU通用计算开放行业标准工作组,以苹果的提案为基础创立OpenCL行业规范。业界最主要的图形或者计算相关的厂商都是Khronos的成员。
OpenCL是一个为异构平台编写并行计算程序的框架,此异构平台可由CPU,GPU或其他类型的处理器组成。OpenCL提供了基于任务分割和数据分割的并行计算机制,开发人员可以利用GPU和CPU的计算能力,把GPU和CPU异构的系统运用在很多并行计算的领域。
OpenCL程序分成两部分:一部分是在GPU上执行,另一部分是在CPU上运行。在GPU上执行的程序就是实现“异构”和“并行计算”的部分。为了能在GPU上执行代码,程序员需要写一个特殊的kernel函数,这个函数需要使用OpenCL语言编写。OpenCL语言是在C++语言的基础上增加了一些约束、关键字和数据类型。在CPU上运行的程序通过OpenCL的API管理GPU上运行的程序。CPU上的程序可以用C++、Java、Python等高级语言编写。
OpenCL开发面向异构平台的应用需要完成以下步骤:
- 发现构成异构系统的组件。
- 探查这些组件的特征, 使软件能够适应不同硬件单元的特定特性。
- 建立将在平台上运行的指令块(内核)。
- 建立并管理计算中涉及的内存对象。
- 在系统中正确的组件上按正确的顺序执行内核。
- 收集最终结果。
2. OpenCL的一些基本概念
2.1 Platform(平台)
CPU加上OpenCL框架管理下的若干GPU构成了这个平台,通过这个平台,应用程序可以与GPU共享资源,并在GPU上执行kernel。实际使用中,一般是一个厂商对应一个Platform,比如Intel,NVIDIA,AMD。
2.2 Device(设备)、计算单元、处理单元
计算单元的集合,比如GPU就是典型的Device。Intel和AMD的CPU也提供OpenCL接口,也可以作为Device。
Device进一步划分为计算单元,计算单元还可以进一步划分为一个或多个处理单元。Device上的计算都在处理单元中完成。
2.3 Contex(上下文)
虽然OpenCL应用的计算工作是在GPU上进行的,但是CPU定义了内核,而且为内核的建立创建了上下文,定义了NDRange和队列(队列存储了内核如何执行以及何时执行的细节),所有这些重要函数都包含在OpenCL定义的API中。
CPU的第一个任务是为 OpenCL应用定义上下文。顾名思义, 上下文定义了一个环境, 内核就在这个环境中定义和执行。更准确地说, 由以下资源定义上下文:
- 设备(device):CPU使用的 GPU集合。
- 内核(kernel):在GPU上运行的OpenCL函数。
- 程序对象(program object):实现内核的程序源代码和可执行文件。
- 内存对象(memory object):内存中对GPU可见的一组对象, 包含可以由内核实例处理的值。
2.4 Program Object(程序对象)
OpenCL程序,由kernel函数、其它函数和声明等组成。
2.5 Kernel(核函数)
可以从CPU调用,运行在GPU上的函数。
2.6 Memory Object(内存对象)
在CPU和GPU之间传递数据的对象,一般映射到OpenCL程序中的global memory。有两种具体的类型:Buffer Object(缓存对象)和Image Object(图像对象)。
OpenCL 定义了两种类型的内存对象:
- Buffer Object:内核可用的一个连续的内存区。程序员可以将数据结构映射到这个缓冲区, 并通过指针访问缓冲区。
- Image Object::仅限于存储图像。图像存储格式可以进行优化来满足一个特定GPU的需要。
2.7 Command Queue(指令队列)
在指定GPU上管理多个指令,队列里指令执行顺序可以顺序也可以乱序。一个GPU可以对应多个指令队列。
CPU与GPU之间的交互是通过命令完成的, 这些命令由CPU提交给Command Queue。这些命令会在Command Queue中等待,直到在GPU上执行。Command Queue由CPU创建, 并在定义上下文之后关联到一个GPU。CPU将命令放入命令队列, 然后调度这些命令在关联GPU上执行。OpenCL支持 3 种类型的命令:
- 内核执行命令(kernel execution command):在 OpenCL 设备的处理单元上执行内核。
- 内存命令( memory command ):在宿主机和不同内存对象之间传递数据, 在内存对象之间移动数据, 或者将内存对象映射到宿主机地址空间, 或者从宿主机地址空间解映射
- 同步命令(synchronization command )对命令执行的顺序施加约束。
一个典型的CPU程序,需要定义上下文、命令队列、内存、程序对象和CPU所需要的数据结构。内存对象从CPU转移到GPU上,内核参数关联到内存对象,然后提交到Command Queue执行。内核完成工作时,计算中生成的内存对象可能会再复制到CPU。
2.8 NDRange(N维索引空间)
CPU发出命令,提交内核在一个GPU上执行。OpenCL运行时会创建一个整数索引空间,索引坐标对应执行内核的一个实例,各个执行内核的实例称为一个工作项,其对应的坐标就是工作项的全局ID。提交内核执行的命令相应地会创建一个工作项集合, 其中各个工作项使用内核定义的同样的指令序列。尽管指令序列是相同的, 但是由于代码中的分支语句或者通过全局ID选择的数据可能不同, 因此各个工作项的行为可能不同。
工作项组织为工作组。工作组提供了对索引空间更粗粒度的分解,跨越整个全局索引空间。工作项可由自身的全局ID或者工作组ID+其局部ID唯一标识。给定工作组中的工作项会在一个计算单元的处理单元上并发执行。
索引空间是一个N维的值网格,也称NDRange,下图给出一个具体的索引空间的例子:
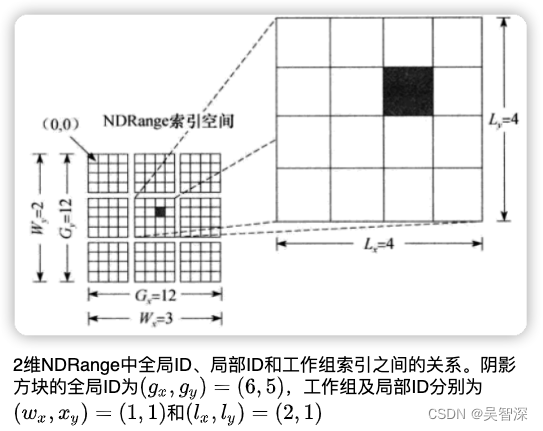
2.9 编程模型
OpenCL 定义了两种不同的编程模型:任务并行和数据并行。
- 数据并行编程模型
适合采用数据并行编程模型的问题都与数据结构有关, 这些数据结构的元素可以并发更新。OpenCL提供了层次结构的数据并行性:工作组中工作项的数据并行再加上工作组层次的数据并行。OpenCL规范讨论了这种数据并行形式的两个变种。在显式模式(explicit model)中, 程序员负责显式地定义工作组的大小。 利用第二个模型, 即隐式模型(implicit model), 程序员只需定义NDRange空间, 由系统选择工作组。总之, 数据并行很自然地切合了OpenCL执行模型。 这个模型是层次结构, 因为数据并行计算(工作项)可能包括矢量指令(SIMD),作为更大规模的块级数据并行(工作组)的一部分。所有这些工作结合起来为表述数据并行算法创建了一个很好的环境。 - 任务并行编程模型
OpenCL执行模型被设计为以数据并行作为主要目标。不过这个模型还支持大量任务并行算法。OpenCL将任务定义为单个工作项执行的内核, 而不考虑OpenCL应用中其他内核使用的NDRange。 如果程序员所希望的并发位来自于任务, 就会使用这个模型。 例如, 并发性可能只是通过矢量类型上的矢量操作来表述。
3. 编译运行第一个OpenCL程序
3.1 在Ubuntu上安装OpenCL
以下命令将安装OpenCL的开发环境:
apt install ocl-icd-* opencl-headers
安装之后,我们可以通过clinfo命令来查看当前计算机上存在的平台、设备、计算单元、处理单元等信息。clinfo可以通过以下命令来安装:
apt install clinfo
若计算机上安装了独立显卡,clinfo则可查看到存在若干个platform,以及每个platform下有的device、work group、work item等信息。
若没有安装独立显卡,则Intel的CPU也支持核心显卡,可通过如下命令安装核心显卡驱动:
apt purge beignet
apt install beignet
安装成功后,clinfo可查看到一个名为Intel Gen OCL Driver的platform。
疑难杂症
有些计算机上安装了独立显卡,但Ubuntu操作系统只启用了核心显卡。为了使用独立显卡,需要给独立显卡安装驱动。
输入命令:ubuntu-drivers devices,会显示系统推荐的驱动,
输入命令:apt install nvidia-推荐的数字,则可安装对应驱动。
驱动安装完后,再通过clinfo查看,则可看到增加了一个platform。
3.2 使用VSCode编译第一个OpenCL程序
3.2.1 手工编译
OpenCL程序是C/C++代码,需要使用g++编译器进行编译、链接和生成可执行程序。假设OpenCL程序已经写好(第4节给出一个基础OpenCL程序,先直接拷贝建立main.cpp文件即可,下一讲再介绍OpenCL程序的原理)。
我们首先要给计算机安装g++编译器,在OpenCL代码中需要#include <CL/cl.h>头文件,该头文件在安装OpenCL驱动时已经安装到g++默认搜索头文件的目录下:/usr/include/,所以直接通过#include <CL/cl.h>即可引入该头文件。
该头文件中定义的函数在链接库中定义,编译时需要链接对应的库,路径为:/lib/x86_64-linux-gnu,库名为OpenCL。
g++的链接命令
库文件名不等于库名,库文件名的命名规则为lib+<库名>+.so,所以OpenCL库对应的库文件为libOpenCL.so。
在编译时,为了链接指定的库,我们需要用到-L和-l参数。-L后指定库所在的目录,-l后跟库名,因此编译时,需要在g++命令中添加-L /lib/x86_64-linux-gnu -l OpenCL进行链接。
假设OpenCL代码文件名为main.cpp,则我们通过如下命令进行编译:
g++ -fdiagnostics-color=always -g main.cpp -o main -L /lib/x86_64-linux-gnu -l OpenCL -w
-g指定可调试;-o手动指定输出文件的路径,即后面跟着的路径;-L和-l参数前面已经解释过,指定库文件的路径和库名;-w指定编译时不显示告警信息。
3.2.2 VSCode配置默认生成任务
VSCode是目前使用最广泛的跨平台跨语言通用IDE环境。通过简单配置,可实现自动编译、断点调试等功能。主要是通过两个配置文件实现的。
在VSCode中,打开需要编译的cpp文件,点击“终端”>“配置默认生成任务”,则会在.vscode目录下新建一个tasks.json文件,可将如下内容拷贝覆盖:
{
"version": "2.0.0",
"tasks": [
{
"type": "cppbuild",
"label": "C/C++: cpp 生成活动文件",
"command": "/usr/bin/g++",
"args": [
"-fdiagnostics-color=always",
"-g",
"${workspaceFolder}/source/*.cpp",
"-o",
"${workspaceFolder}/out/${workspaceRootFolderName}",
"-L",
"/lib/x86_64-linux-gnu",
"-l",
"OpenCL",
"-w"//编译时不显示任何警告,-Wall是显示所有警告
]
}
]
}
command字段指定g++编译器的位置,args字段指定g++命令的参数。
我个人开发项目的习惯是建立三个文件夹,include文件夹下放各种.h文件,source文件夹下放.cpp文件,out文件夹用于项目编译输出,另外还有一个VSCode的配置文件夹.vscode。
在上面这段tasks.jsp配置中,我们指定每次自动生成任务时,对${workspaceFolder}/source/下的所有cpp文件进行编译,并输出到${workspaceFolder}/out/目录下,以${workspaceRootFolderName}命名输出的文件。${workspaceFolder}符号在配置文件中会被替换为VSCode项目所在的目录名。
配置完毕后,我们点击“终端”>“运行生成任务”则可自动编译链接生成。
3.2.3 VSCode配置调试
我们可以配置VSCode使用gdb调试程序。首先需要在系统中安装gdb,通过apt install gdb即可完成安装。
在VSCode中,点击“运行”>“添加配置”则可在.vscode目录下新建launch.json文件,该文件则用于配置调试信息,可将如下内容复制覆盖。
{
"version": "0.2.0",
"configurations": [
{
"name": "(gdb) 启动",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/out/${workspaceRootFolderName}",
"args": [],
"stopAtEntry": false,
"cwd": "${fileDirname}",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"setupCommands": [
{
"description": "为 gdb 启用整齐打印",
"text": "-enable-pretty-printing",
"ignoreFailures": true
},
{
"description": "将反汇编风格设置为 Intel",
"text": "-gdb-set disassembly-flavor intel",
"ignoreFailures": true
}
],
"preLaunchTask": "C/C++: cpp 生成活动文件"
}
]
}
需要注意的是,"preLaunchTask"字段配置的是预执行任务,在调试前需要启动生成,因此配置的内容与tasks.json中的"label"字段内容一致,VSCode通过label来判断任务。
至此,我们可以通过VSCode设置断点和启动调试。
4. OpenCL Hello World
#define CL_TARGET_OPENCL_VERSION 220
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <iostream>
#include <CL/cl.h>
using namespace std;
void check_result(const int *buf, const int len)
{
int i;
for (i = 0; i < len; i++)
{
if (buf[i] != (i + 1) * 2)
{
cout << "Result error!" << endl;
break;
}
}
if (i == len)
cout << "Result ok." << endl;
}
void init_buf(int *buf, int len)
{
int i;
for (i = 0; i < len; i++)
{
buf[i] = i + 1;
}
}
int main(void)
{
cl_int ret;
/** step 1: get platform */
cl_uint num_platforms;
ret = clGetPlatformIDs(0, NULL, &num_platforms); // get platform number
if ((CL_SUCCESS != ret) || (num_platforms < 1))
{
cout << "Error getting platform number: " << ret << endl;
return 0;
}
cl_platform_id platform_id = NULL;
ret = clGetPlatformIDs(1, &platform_id, NULL); // get first platform id
if (CL_SUCCESS != ret)
{
cout << "Error getting platform id: " << ret << endl;
return 0;
}
/** step 2: get device */
cl_uint num_devices;
clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_GPU, 0, NULL, &num_devices);
if ((CL_SUCCESS != ret) || (num_devices < 1))
{
cout << "Error getting GPU device number: " << ret << endl;
return 0;
}
cl_device_id device_id = NULL;
clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_GPU, 1, &device_id, NULL);
if (CL_SUCCESS != ret)
{
cout << "Error getting GPU device id: " << ret << endl;
return 0;
}
/** step 3: create context */
cl_context_properties props[] = {CL_CONTEXT_PLATFORM, (cl_context_properties)platform_id, 0};
cl_context context = NULL;
context = clCreateContext(props, 1, &device_id, NULL, NULL, &ret);
if ((CL_SUCCESS != ret) || (NULL == context))
{
cout << "Error creating context: " << ret << endl;
return 0;
}
/** step 4: create command queue */
cl_command_queue command_queue = NULL;
command_queue = clCreateCommandQueue(context, device_id, 0, &ret);
if ((CL_SUCCESS != ret) || (NULL == command_queue))
{
cout << "Error creating command queue: " << ret << endl;
return 0;
}
/** step 5: create memory object */
cl_mem mem_obj = NULL;
int *host_buffer = NULL;
const int ARRAY_SIZE = 1000;
const int BUF_SIZE = ARRAY_SIZE * sizeof(int);
// create and init host buffer
host_buffer = (int *)malloc(BUF_SIZE);
init_buf(host_buffer, ARRAY_SIZE);
// create opencl memory object using host ptr
mem_obj = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_USE_HOST_PTR, BUF_SIZE, host_buffer, &ret);
if ((CL_SUCCESS != ret) || (NULL == mem_obj))
{
cout << "Error creating command queue: " << ret << endl;
return 0;
}
/** step 6: create program */
char *kernelSource =
"__kernel void test(__global int *pInOut)\n"
"{\n"
" int index = get_global_id(0);\n"
" pInOut[index] += pInOut[index];\n"
"}\n";
cl_program program = NULL;
// create program
program = clCreateProgramWithSource(context, 1, (const char **)&kernelSource, NULL, &ret);
if ((CL_SUCCESS != ret) || (NULL == program))
{
cout << "Error creating program: " << ret << endl;
return 0;
}
// build program
ret = clBuildProgram(program, 1, &device_id, NULL, NULL, NULL);
if (CL_SUCCESS != ret)
{
cout << "Error building program: " << ret << endl;
return 0;
}
/** step 7: create kernel */
cl_kernel kernel = NULL;
kernel = clCreateKernel(program, "test", &ret);
if ((CL_SUCCESS != ret) || (NULL == kernel))
{
cout << "Error creating kernel: " << ret << endl;
return 0;
}
/** step 8: set kernel arguments */
ret = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *)&mem_obj);
if (CL_SUCCESS != ret)
{
cout << "Error setting kernel argument: " << ret << endl;
return 0;
}
/** step 9: set work group size */
cl_uint work_dim = 3; // in most opencl device, max dimition is 3
size_t global_work_size[] = {ARRAY_SIZE, 1, 1};
size_t *local_work_size = NULL; // let opencl device determine how to break work items into work groups
/** step 10: run kernel */
ret = clEnqueueNDRangeKernel(command_queue, kernel, work_dim, NULL, global_work_size, local_work_size, 0, NULL, NULL);
if (CL_SUCCESS != ret)
{
cout << "Error enqueue NDRange: " << ret << endl;
return 0;
}
/** step 11: get result */
int *device_buffer = (int *)clEnqueueMapBuffer(command_queue, mem_obj, CL_TRUE, CL_MAP_READ | CL_MAP_WRITE, 0, BUF_SIZE, 0, NULL, NULL, &ret);
if ((CL_SUCCESS != ret) || (NULL == device_buffer))
{
cout << "Error map buffer: " << ret << endl;
return 0;
}
// check result
check_result(device_buffer, ARRAY_SIZE);
/** step 12: release all resources */
if (NULL != kernel)
clReleaseKernel(kernel);
if (NULL != program)
clReleaseProgram(program);
if (NULL != mem_obj)
clReleaseMemObject(mem_obj);
if (NULL != command_queue)
clReleaseCommandQueue(command_queue);
if (NULL != context)
clReleaseContext(context);
if (NULL != host_buffer)
free(host_buffer);
return 0;
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









